안녕하세요. 마수리입니다.
궁금증을 갖고 무엇인가를 조사해 보는 것은 때론 즐겁습니다. 오늘도 몰랐던 사실을 하나 알게 되어 이렇게 글을 남겨봅니다.
오늘은 오픈서치에 대한 글입니다.
현재 오픈서치의 구성은 2개의 노드를 클러스터링 해서 사용하고 있고 따로 샤드 설정을 하지 않아서 기본적으로 primary와 replica를 각각 1개씩 가지는 상황이었습니다.
또한, bulk 연산의 효율성을 증대하기 위해 bulk 연산 전에 replica의 개수를 0개로 줄이고 연산이 완료되면 다시 1개로 늘리는 식으로 최적화를 하였고 그렇기 때문에 bulk 연산 중에는 1개의 primary 샤드에만 데이터가 입력 되는 상황입니다.
이러한 설정의 오픈서치 클러스터에 bulk 연산을 이용해서 다량의 데이터를 넣는 중 의아한 점을 발견했습니다.
왜.. 2개의 노드 모두 메모리를 사용하는거지? 분명
primary샤드는 1개로 둘 중 1개의 노드로만 데이터가 전송되어야 하는 것 아닌가..??
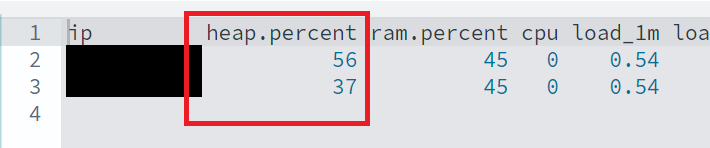
미리 말씀 드리자면 위의 말은 모두 맞는 말입니다.
그럼..!! 왜?! 어째서?! 모든 노드의 메모리를 사용하는걸까?

정답은 공식 사이트에서 쓴 블로그를 읽다가 알게 되었습니다.
오픈서치의 여러가지 노드가 클러스터링이 되었을 때 bulk 연산을 하면 어떤 현상이 일어나는지 간단히 설명해 보겠습니다.
데이터가 오픈서치 클러스터로 들어오면 클러스터로 연결된 노드 중에 coordinating node로 데이터를 받게 됩니다. Coordinating node란 사용자의 http 요청을 받고 bulk 연산이 처리 되어야하는 노드로 라우팅 시키고 각각의 노드에서 나온 결과를 취합해서 다시 사용자에게 보내주는 역할을 하는 노드입니다.
조금 더 자세히 설명하자면 bulk 연산은 그야말로 여러가지 연산이 합해서 1개의 호출로 들오는 api입니다. 이 데이터 안에는 여러 개의 index를 방문해야 하는 데이터가 있을 수 있고 샤드가 여러 개일 경우 각각의 샤드가 위치한 노드로 데이터를 보내야 할 수도 있습니다. 이렇게 라우팅 된 데이터는 각각의 노드에서 데이터 처리 큐에 들어가 쓰레드 풀에 의해서 순차적으로 처리가 진행하게 되게 됩니다.
이런 coordinating node는 이 역할만 하는 노드를 만들 수도 있고 그렇지 않다면 모든 노드가 기본적으로 coordinating node가 될 수 있습니다.
네! 정답은 여기에 있었습니다. 모든 노드가
coordinating node가 될 수 있기 때문에 샤드가 저장되는 노드만 사용되는게 아니라 모든 노드가 사용자의 요청을 받아 적어도 라우팅 작업은 하고 있었던 것입니다.
정리
여러개의 오픈서치 노드를 클러스터링해서 사용할 때 샤드가 1개라면 1개의 노드에 적재되는게 맞다. 하지만 이것이 오픈서치 클러스터의 1개의 노드에만 메모리를 사용해한다는 뜻은 아니다. 왜냐하면 오픈서치 클러스터로 사용자의 요청이 들어오면 coordinating node가 처리를 담당하는데 이 역할은 클러스터의 모든 노드가 할 수 있기 때문이다.
이런 궁금증으로 인해 여러가지 노드의 역할에 대해 알아보고 결국 coordinating node의 역할을 직접 알게 되었습니다.
오늘은 여기까지입니다.
감사합니다!
