본 내용은 인프런 강의 <데이터 분석을 위한 판다스>를 수강하며 중요한 점을 정리한 글입니다.
데이터 설명
num_dataset = len(coord['dataset'].unique())
dataset_I_len = len(coord[coord['dataset'] == 'I'])
print(f"총 {num_dataset}개의 데이터 셋으로 이루어져 있으며 각 데이터셋 안에 {dataset_I_len}개의 좌표가 들어있습니다.")- 코드 해설
num_dataset = len(coord['dataset'].unique()):
coord['dataset']: 'coord' 데이터프레임에서 'dataset' 열을 선택합니다.
.unique(): 'dataset' 열의 고유한 값을 찾습니다.
len(...): 고유한 값들의 개수를 세어줍니다.
num_dataset: 이 값은 'dataset' 열에서 발견된 고유한 데이터셋의 개수입니다.
따라서, num_dataset에는 'coord' 데이터프레임의 'dataset' 열에 대해 고유한 값들의 개수가 저장됩니다.
dataset_I_len = len(coord[coord['dataset'] == 'I']):
coord['dataset'] == 'I': 'dataset' 열에서 값이 'I'인 행들에 대한 불리언 마스크를 생성합니다.
coord[...]: 불리언 마스크를 사용하여 'coord' 데이터프레임에서 조건을 만족하는 행들을 선택합니다.
len(...): 선택된 행들의 개수를 세어줍니다.
dataset_I_len: 이 값은 'coord' 데이터프레임에서 'dataset'이 'I'인 행들의 개수를 나타냅니다.
따라서, dataset_I_len에는 'coord' 데이터프레임에서 'dataset'이 'I'인 행들의 개수가 저장됩니다.
이렇게 함으로써, 이 코드들은 'coord' 데이터프레임에서 'dataset' 열의 고유한 값들의 개수와 'dataset'이 'I'인 행들의 개수를 계산하여 변수에 저장합니다.
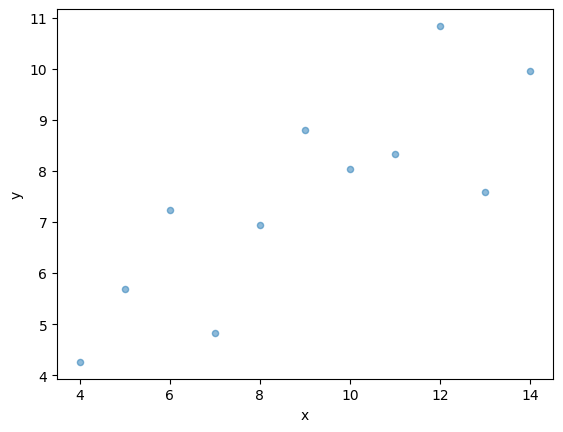
Q1. 전체 데이터 모양 확인하기
컬럼 x를 x 축으로 하고, 컬럼 y를 y 축으로 하는 산포도(scatter plot)를 전체 44개의 좌표 데이터를 이용해 그려주세요.
coord.plot.scatter(x='x', y='y', alpha = 0.5)- 코드해설
coord: 이 코드가 실행되는 데이터프레임입니다. 코드를 실행하기 전에 coord라는 변수에 데이터프레임이 할당되어 있어야 합니다.
.plot.scatter: Pandas 데이터프레임에서 제공하는 산점도를 그리는 메서드입니다. 여기서 scatter는 산점도를 의미하며, 데이터프레임의 두 열을 x와 y축에 매핑하여 산점도를 생성합니다.
x='x', y='y': 이 부분은 산점도의 x축과 y축에 사용할 열을 지정합니다. 여기서 'x' 열의 값은 x축에, 'y' 열의 값은 y축에 매핑됩니다.
alpha=0.5: 이 부분은 그려지는 점들의 투명도를 나타냅니다. 0에서 1 사이의 값을 가지며, 0에 가까울수록 투명하고 1에 가까울수록 불투명합니다. 여기서는 0.5로 설정되어 점들이 중간 정도로 투명한 산점도를 생성합니다.
Q2. 각 데이터셋의 평균과 표준편차 구하기
앞에서 배웠던 describe() 함수를 이용하여 각각의 dataset('I', 'II', 'III', 'IV')에 대하여 x와 y의 평균과 표준편차를 구해봅시다.
coord.loc[coord['dataset'] == 'I', ['x', 'y']].describe()- 코드해설
coord['dataset'] == 'I': 이 부분은 'dataset' 열에서 값이 'I'인 행을 선택하는 조건을 나타냅니다. 즉, 'dataset'이 'I'인 행들을 선택합니다.
coord.loc[...]: 이 부분은 행과 열을 기반으로 데이터프레임에서 원하는 부분을 선택하는 역할을 합니다. 여기서 행을 선택하는 부분은 앞서의 조건에 해당하는 행들이고, 열을 선택하는 부분은 'x'와 'y' 열입니다.
['x', 'y']: 이 부분은 'x'와 'y' 열을 선택합니다.
.describe(): 이는 선택된 'x'와 'y' 열에 대한 기술 통계량을 계산하는 함수입니다. 기술 통계량은 평균(mean), 표준편차(standard deviation), 최소값(minimum), 25%, 50%, 75%의 백분위수(percentiles), 최대값(maximum) 등을 포함합니다.
Q3. 각 데이터셋의 산포도 그리기
Q1에서는 전체 44개의 좌표에 대해 산포도를 그렸습니다. 이번에는 4개의 데이터셋 별로 산포도를 그리고, 4개의 데이터셋 모양이 다름을 확인하세요.
coord[coord['dataset'] == 'I'].plot.scatter(x='x', y='y', alpha = 0.5)