
CH1. TCP/IP
📌 네트워크의 시작
기존에 회선교환 방식으로 네트워크를 구축하다가 당시 미 국방성에서 냉전시대에 핵전쟁을 대비하기 위해 통신망 구축을 위한 아르파넷(ARPANET) 프로젝트에서 패킷교환 방식으로 네트워크를 구축하게 됨. 이는 오늘날 우리가 사용하는 인터넷 프로토콜 (IP) 기반이 됨.
회선교환 방식
🔸 발신자와 수신자 사이에 데이터를 전송할 전용선을 미리 할당하고 둘을 연결함.
🔸 내가 연결하고 싶은 상대가 다른 상대와 연결 중이라면, 그 연결이 끊어지고 나서야 상대방과 연결할 수 있음.
🔸 또한, 특정 회선이 끊어지는 경우 처음부터 다시 연결을 성립해야 함.
패킷교환 방식
🔸 패킷이라는 단위로 데이터를 잘게 나누어 전송하는 방식으로, 각 패킷에는 출발지와 목적지 정보가 있고 이에 따라 패킷이 목적지를 향해 가장 효율적인 방식으로 이동함.
🔸 이를 통해, 특정 회선이 전용선으로 할당되지 않기 때문에 빠르고 효율적으로 데이터 전송 가능.
🔸 IP 주소라는 특정한 숫자값으로 출발지와 목적지의 정보를 표기하고 패킷단위로 데이터를 전송.
📌 IP/IP packet
🔸 복잡한 인터넷 망 속 수많은 노드(하나의 서버 컴퓨터)들을 지나 클라이언트와 서버가 통신을 하기 위해서 IP 주소를 컴퓨터에 부여해 패킷이라는 통신 단위로 데이터를 전달함.
IP packet

🔸 IP 패킷은 pack과 bucket이 합쳐진 단어로 데이터 통신을 위한 소포라고 볼 수 있음.
🔸 전송 데이터를 전송하기 위해 출발지 IP, 목적지 IP와 같은 정보를 포함.
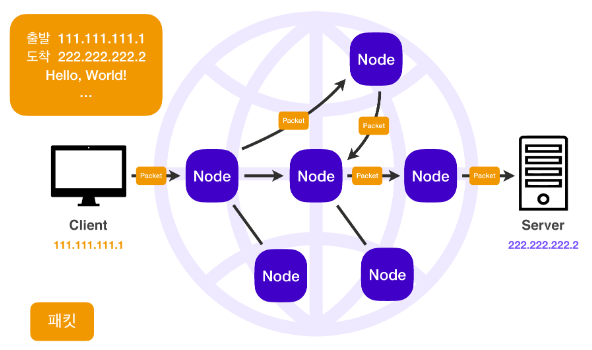
🔸 패킷 단위로 전송을 하면 노드들은 목적지 IP에 도달하기 위해 서로 데이터를 전달하고, 이를 통해 복잡한 인터넷 망 사이에서도 정확한 목적지로 패킷을 전송할 수 있음.
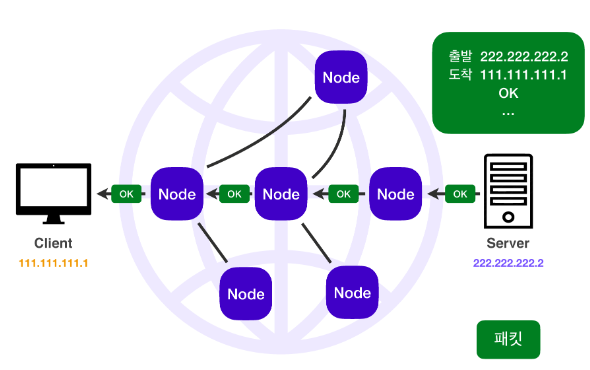
🔸 또한 서버에서 데이터를 받으면 이에 대한 응답을 IP 패킷을 통해 클라이언트에 전달함.
IP 한계
🔸 비연결성
- 패킷을 받을 대상이 없거나 서비스 불능 상태여도 클라이언트는 서버의 상태를 파악할 수 없기 때문에 패킷을 그대로 전송함.
🔸 비신뢰성
- 중간에 있는 서버가 데이터를 전달하던 중 장애가 생겨 패킷이 중간에 소실되더라도 클라이언트는 이를 파악할 수 없음. 즉, 패킷이 중간에 소실될 수 있음.
- 전달 데이터의 용량이 클 경우 이를 패킷 단위로 나눠 데이터를 전달하게 되는데 이때 패킷들은 중간에 서로 다른 노드를 통해 전달 될 수 있기 때문에 클라이언트가 의도하지 않은 순서로 서버에 패킷이 도착할 수 있음. 즉, 패킷이 순서대로 도착하지 않을 수 있음.
📌 TCP/UDP
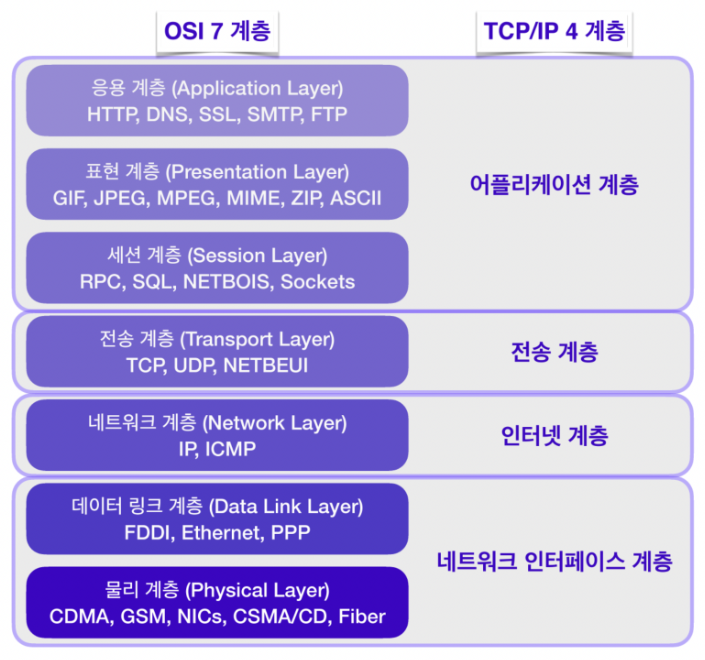 🔸 네트워크 프로토콜 계층은 OSI 7계층과 TCP/IP 4 계층으로 나눌 수 있음.
🔸 네트워크 프로토콜 계층은 OSI 7계층과 TCP/IP 4 계층으로 나눌 수 있음.
💡 TCP/IP 4 계층은 OSI 7 계층보다 먼저 개발되었으며, TCP/IP 프로토콜의 계층은 OSI 모델의 계층과 정확하게 일치하지는 않음. 실제 네트워크 표준은 업계표준을 따르는 TCP/IP 4 계층에 가까움.
🔸 IP 프로토콜 보다 더 높은 계층에 TCP 프로토콜이 존재하기 때문에 IP 프로토콜의 한계를 보완할 수 있음.
📍 채팅 프로그램에서 메세지를 보낼 때 일어나는 일
1. 프로그램이 HTTP 메세지를 생성.
2. Socket을 통해 전달. (소켓 : 프로그램이 네트워크에서 데이터를 송수신할 수 있도록 네트워크 환경에 연결할 수 있게 만들어진 연결부)
3. TCP 정보 생성, 메세지 데이터 포함.
4. IP 패킷 생성, TCP 데이터 포함.
5. 생성된 TCP/IP 패킷은 LAN 카드와 같은 물리적 계층을 지나기 위해 이더넷 프레임 워크에 포함되어 서버로 전송됨.
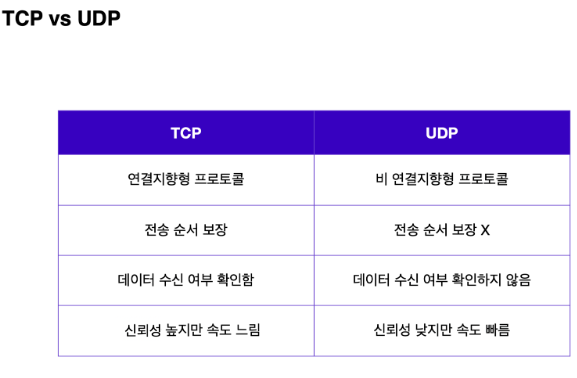
TCP (Transmission Control Protocol, 전송 제어 프로토콜) 특징
🔸 IP 패킷의 출발지 IP와 목적지 IP 정보를 보완할 수 있는 출발지 PORT, 목적지 PORT, 전송 제어, 순서, 검증 정보 등을 포함.
🔸 같은 계층에 속한 UDP에 비해 상대적으로 신뢰할 수 있는 프로토콜.
🔸 장치들 사이에 논리적인 접속을 성립하기 위해 TCP 3 way handshake (가상 연결)를 사용하는 연결지향형 프로토콜.
- 클라이언트가 서버에 접속을 요청하는 SYN (Synchronize) 패킷을 보냄.
- 서버는 SYN 요청을 받고, 클라이언트에게 요청을 수락한다는 ACK (Acknowledgment)와 SYN이 설정된 패킷을 발송.
- 클라이언트가 서버에게 ACK를 보내면, 이 이후로부터 연결이 성렵되며 데이터를 전송할 수 있음.
- 현재는 최적화가 이루어져 3번 ACK를 보낼때 데이터를 함께 보내기도 함.
🔸 데이터 전달 보증. 데이터 전송이 성공적으로 이루어졌을 때 이에 대한 응답을 돌려주기 때문에 IP 패킷의 한계인 비연결성을 보완함.
🔸 순서 보장, 신뢰할 수 있는 프로토콜. 만약 패킷이 순서대로 도착하지 않는다면 TCP 세그먼트에 있는 정보를 토대로 다시 패킷 전송을 요청할 수 있어, IP 패킷의 비신뢰성(순서를 보장하지 않음)을 보완.
UDP (User Datagram Protocol, 사용자 데이터그램 프로토콜) 특징
🔸 IP에 PORT, 체크섬(ckecksum) 필드 정보만 추가된 단순한 프로토콜.
- 체크섬 : 중복 검사의 한 형태로, 오류 정정을 통해 공간(전자 통신)이나 시간(기억 장치) 속에서 송신된 자료의 무결성을 보호하는 단순한 방법)
🔸 기능이 거의 없음 (HTTP3는 UDP를 사용해 이미 여러 기능이 구현된 TCP보다는 커스터마이징이 가능하다는 장점을 가짐).
🔸 비 연결지향 - TCP 3 way handshake X
🔸 데이터 전달 보증 X
🔸 순서 보장 X
🔸 데이터 전달 및 순서가 보장되진 않지만, 단순하고 빠름.
🔸 신뢰성보다는 연속성이 중요한 서비스 (e.g. 실시간 스트리밍)에 자주 사용됨.
CH2. 네트워크 계층 모델
📌 OSI 7계층 모델
🔸 ISO (International Organization for Standardization)라고 하는 국제표준화기구에서 1984년에 제정한 표준 규격.
옛날에는 같은 회사에서 만든 컴퓨터끼리만 통신이 가능했음. 따라서 다른 회사의 시스템이라도 네트워크 유형에 관계없이 상호 통신이 가능한 규약, 즉 프로토콜이 필요했음. ISO에서는 제조사에 상관없이 공통으로 사용할 수 있는 네트워크 표준 규격을 정의함.
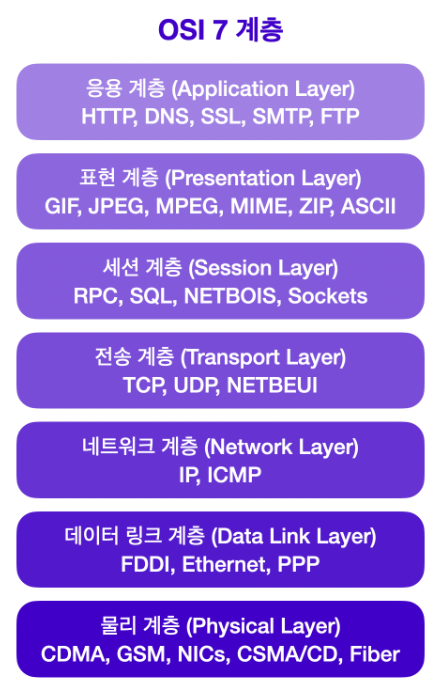
🔸 OSI 7계층 모델은 네트워크를 이루고 있는 구성요소들을 7단계로 나누고, 각 계층의 표준을 정함.
🔸 목적 : 표준화를 통하여 포트, 프로토콜의 호환 문제를 해결하고, 네트워크 시스템에서 일어나는 일을 해당 계층 모델을 이용해 쉽게 설명하는 것.
🔸 네트워크 관리자가 문제가 발생했을 때 이것이 물리적인 문제인지, 응용 프로그램과 관련이 있는지 등 원인이 어디에 있는지 범위를 좁혀 문제를 쉽게 파악할 수 있음.
1계층 - 물리 계층
- OSI 모델의 맨 밑에 있는 계층으로 시스템 간의 물리적인 연결과 전기 신호를 변환 및 제어하는 계층.
- 주로 물리적 연결과 관련된 정보를 정의.
- 전기 신호를 전달하는데 초점을 두고, 들어온 전기 신호를 그대로 잘 전달하는 것이 목적.
- e.g. 디지털 또는 아날로그로 신호 변경
2계층 - 데이터링크 계층
- 네트워크 기기 간의 데이터 전송 및 물리주소(e.g. MAC 주소)를 결정하는 계층.
- 물리 계층에서 들어온 전기 신호를 모아 알아볼 수 있는 데이터 형태로 처리.
- 주소 정보를 정의하고 출발지와 도착지 주소를 확인한 후, 데이터 처리를 수행.
- e.g. 브리지 및 스위치, MAC 주소
3계층 - 네트워크 계층
- 가장 복잡한 계층 중 하나로서 실제 네트워크 간에 데이터 라우팅을 담당.
- 라우팅 : 어떤 네트워크 안에서 통신 데이터를 짜인 알고리즘에 의해 최대한 빠르게 보낼 최적의 경로를 선택하는 과정.
- e.g. IP 패킷 전송
4계층 - 전송 계층
- 컴퓨터 간(End-To-End) 신뢰성 있는 데이터를 서로 주고받을 수 있도록 하는 서비스를 제공하는 계층.
- 해당 데이터들이 실제로 정상적으로 보내지는지 확인하는 역할.
- 네트워크 계층에서 사용되는 패킷은 유실되거나 순서가 바뀌는 경우가 있는 데, 이를 바로 잡아주는 역할도 담당.
- e.g. TCP/UDP 연결
5계층 - 세션 계층
- 세션 연결의 설정과 해제, 세션 메시지 전송 등의 기능을 수행하는 계층. 즉, 컴퓨터 간의 통신 방식에 대해 결정.
- 양 끝 단의 프로세스가 연결을 성립하도록 도와주고, 작업을 마친 후에는 연결을 끊는 역할.
6계층 - 표현 계층
- 응용 계층으로 전달하거나 전달받는 데이터를 인코딩 또는 디코딩하는 계층.
- 인코딩/디코딩, 압축/해제, 암호화/복호화 등의 역할을 수행.
- e.g. 문자 코드, 압축, 암호화 등의 데이터 변환
7계층 - 응용 계층
- 최종적으로 사용자와의 인터페이스를 제공하는 계층.
- 사용자가 실행하는 응용 프로그램(e.g. Google Chrome)들이 해당 계층에 속함.
- e.g. 이메일 및 파일 전송, 웹 사이트 조회 등 애플리케이션에 대한 서비스를 사용자에게 제공하는 계층.
- 애플리케이션은 서비스를 요청하는 측(사용자 측)에서 사용하는 애플리케이션과 서비스를 제공하는 측의 애플리케이션으로 분류. (서비스를 요청하는 측을 클라이언트, 서비스를 제공하는 측을 서버).
- 클라이언트와 서버 모두 응용 계층에서 동작.
데이터 캡슐화
🔸 OSI 7계층 모델은 송신 측의 7계층과 수신 측의 7계층을 통해 데이터를 주고받음. 각 계층은 독립적이므로 데이터가 전달되는 동안에 다른 계층의 영향을 받지 않음.
🔸 데이터를 전송하는 쪽 - 데이터를 보내기 위해서 상위 계층에서 하위 계층으로 데이터를 전달, 이때 데이터를 상대방에게 보낼 때 각 계층에서 필요한 정보를 데이터에 추가하는데 이 정보를 헤더(데이터링크 계층에서는 트레일러)라고 함. 이렇게 헤더를 붙여나가는 것을 캡슐화라고 함.
🔸 마지막 물리 계층에 도달하면, 송신 측의 데이터링크 계층에서 만들어진 데이터가 전기 신호로 변환되어 수신 측에 전송됨.
🔸 데이터를 받는 쪽 - 하위 계층에서 상위 계층으로 각 계층을 통해 전달된 데이터를 받게 됨. 이때 상위 계층으로 데이터를 전달하며 각 계층에서 헤더(데이터링크 계층에서는 트레일러)를 제거해 나가는 역캡슐화를 진행.
🔸 역캡슐화를 거쳐 마지막 응용 계층에 도달하면 드디어 전달하고자 했던 원본 데이터만 남게 됨.
📌 TCP/IP 4계층 모델
🔸 OSI 모델을 기반으로 실무적으로 이용할 수 있도록 현실에 맞춰 단순화된 모델로 실용성에 기반을 둔 인터넷 표준임.
4계층 - 애플리케이션 계층
- OSI 계층의 세션 계층, 표현 계층, 응용 계층에 해당.
- TCP/UDP 기반의 응용 프로그램을 구현할 때 사용.
- e.g. FTP, HTTP, SSH
3계층 - 전송 계층
- OSI 계층의 전송 계층에 해당.
- 통신 노드 간의 연결을 제어하고, 신뢰성 있는 데이터 전송을 담당.
- e.g. TCP/UDP
2계층 - 인터넷 계층
- OSI 계층의 네트워크 계층에 해당.
- 통신 노드 간의 IP 패킷을 전송하는 기능 및 라우팅을 담당.
- e.g. IP, ICMP, ARP, RARP
1계층 - 네트워크 인터페이스 계층
- OSI 계층의 물리 계층과 데이터 링크 계층에 해당.
- 물리적인 주소로 MAC을 사용.
- e.g. LAN, HDLC, PPP, 패킷망 등에 사용됨.
CH3. HTTP
📌 HTTP의 특징
🔸 HTTP/1.1, HTTP/2 - TCP 기반 프로토콜
🔸 HTTP/3 - UDP 기반 프로토콜
클라이언트 서버 구조
- Request Response 구조 - 클라이언트가 서버에 요청을 보내고, 응답을 대기. 서버가 요청에 대한 결과를 만들어 응답.
무상태 프로토콜 (Stateless)
- 상태 유지 : 서버가 클라이언트의 상태를 보존. 클라이언트 A의 요청을 서버 1이 기억하고 있기 때문에 항상 서버 1이 응답해야 함. 만약 서버 1이 장애가 난다면 유지되던 상태 정보가 다 날아가 처음부터 다시 서버에 요청해야 함.
- 무상태 : 서버가 클라이언트의 상태를 보존하지 않아 갑자기 클라이언트 요청이 증가해도 서버를 대거 투입할 수 있음. 클라이언트 A가 요청할 때 이미 필요한 데이터를 다 담아서 보내기 때문에 아무 서버나 호출해도 됨. 한 서버에 장애가 생기더라도 다른 서버에서 응답을 전달하면 되기 때문에 클라이언트는 다시 요청할 필요가 없음.
- 장점 : 응답 서버를 쉽게 바꿀 수 있어 무한한 서버 증설이 가능. 즉, 서버 확장성 높음 (스케일 아웃)
- 단점 : 클라이언트가 추가 데이터 전송
- 한계
- 모든 것을 무상태로 설계할 수 있는 경우도 있고 없는 경우도 있음.
- 무상태 - e.g. 로그인이 필요없는 단순한 서비스 소개 화면.
- 상태 유지 - e.g. 로그인, 로그인한 사용자의 경우 로그인했다는 상태를 서버에 유지 (브라우저 쿠키, 서버 세션, 토큰 등을 이용해 상태를 유지해야 함)
- 상태 유지는 최소한만 사용.
비연결성 (Connectionless)
- TCP/IP의 경우 기본적으로 연결을 유지함.
- 연결 유지 모델 - 클라이언트 1, 2는 요청을 보내지 않더라도 계속 연결을 유지해야 하고, 이러는 동안 서버의 자원이 계속 소모가 됨.
- 비연결성을 가지는 HTTP에서는 실제로 요청을 주고받을 때만 연결을 유지하고 응답을 주고나면 TCP/IP 연결을 끊음 ➡️ 최소한의 자원으로 서버 유지 가능.
- HTTP 1.0 기준으로, HTTP는 연결을 유지하지 않는 모델.
- 일반적으로 초 단위 이하의 빠른 속도로 응답. 트래픽이 많지 않고, 빠른 응답을 제공할 수 있는 경우, 비연결성의 특징은 효율적으로 작동.
- 한 시간 동안 수천 명이 서비스를 사용해도, 실제 서버에서는 초당 처리 요청 개수는 수십 개에 불과. e.g. 웹브라우저에서 계속 연속해서 검색 버튼을 누르지 않음.
- 한계
- 트래픽이 많고, 큰 규모의 서비스를 운영할 때에는 비연결성은 한계.
- TCP/IP 연결을 새로 맺어야 함 - 3 way handshake 시간 추가.
- 웹 브라우저로 사이트를 요청하면 HTML 뿐만 아니라 자바스크립트, CSS, 추가 이미지 등 수 많은 자원이 함께 다운로드
- 해당 자원들을 각각 보낼 때마다 연결 끊고 다시 연결하고를 반복하는 것은 비효율적이기 때문에 지금은 HTTP 지속 연결(Persistent Connections)로 문제를 해결.
- HTTP 초기에는 각각의 자원을 다운로드하기 위해 연결과 종료를 반복해야 했음.
- HTTP 지속 연결에서는 연결이 이루어지고 난 뒤 각각의 자원들을 요청하고 모든 자원에 대한 응답이 돌아온 후 연결을 종료함.
- HTTP/2, HTTP/3에서 더 많은 최적화.
HTTP 메세지
단순함, 확장 가능
📌 HTTP Headers의 종류와 특징
🔸 HTTP 메시지는 헤더와 바디로 구분됨.
🔸 HTTP 바디 : 데이터 메세지 본문(Message body)을 통해 표현(Representation) 데이터를 전달.
🔸 메세지 본문 🟰 데이터를 실어 나르는 부분 🟰 페이로드(payload)
🔸 표현 데이터 : 요청이나 응답에서 전달할 실제 데이터.
🔸 표현 헤더 : 표현 데이터를 해석할 수 있는 정보를 제공. 데이터 유형(html, json), 데이터 길이, 압축 정보 등.
표현 헤더(Representation Headers)
🔸 HTTP 헤더 형식 : <field-name>:<field-value> (field-name은 대소문자 구분없음)
🔸 용도
- HTTP 전송에 필요한 모든 부가정보를 담기 위해 사용.
- e.g. 메세지 바디의 내용, 메세지 바디의 크기, 압축, 인증, 요청 클라이언트, 서버 정보, 캐시 관리 정보...
- 표준 헤더가 너무 많음 (List of HTTP header fields)
- 필요 시 임의의 헤더 추가 가능 e.g. Helloworld: hihi
🔸 표현 헤더는 요청, 응답 둘 다 사용.
Content-Type : 표현 데이터의 형식
- 미디어 타입, 문자 인코딩.
- eg.
- Text/html; charset=utf-8
- application/json
- Image/png
- [MDN] MIME types, [MDN] Content-Type
Content-Encoding : 표현 데이터의 압축 방식
- 표현 데이터를 압축하기 위해 사용
- 데이터를 전달하는 곳에서 압축 후 인코딩 헤더 추가
- 데이터를 읽는 쪽에서 인코딩 헤더의 정보로 압축 해제
- e.g.
- gzip
- deflate
- identity
- [MDN] Content-Encoding
Content-Length : 표현 데이터의 길이
- 바이트 단위
- Transfer-Encoding : 전송 시 어떤 인코딩 방법을 사용할 것인가를 명시. chunked의 방식으로 사용.
- 현재는 Transfer-Encoding보다는 Content-Encoding을 사용.
- Transfer-Encoding(전송 코딩)을 사용하면 Content-Length를 사용하면 안됨. chunked 방식의 인코딩은 많은 양의 데이터를 분할하여 보내기 때문에 전체 데이터의 크기를 알 수 없어 표현 데이터의 길이를 명시해야 하는 Content-Length 헤더와 함께 사용할 수 없음
Content-Language : 표현 데이터의 자연어 언어
- 표현 데이터의 자연 언어를 표현
- e.g.
- ko
- en
- en-US
- [MDN] Content-Language
요청(Request)에서 사용되는 헤더
From : 유저 에이전트의 이메일 정보
- 일반적으로 잘 사용하지 않음.
- 검색 엔진에서 주로 사용.
Referer : 이전 웹 페이지 주소
- 현재 요청된 페이지의 이전 웹 페이지 주소
- A → B로 이동하는 경우 B를 요청할 때
Referer: A를 포함해서 요청Referer를 사용하면 유입경로 수집 가능- referer는 단어 referrer의 오탈자이지만 스펙으로 굳어짐
User-Agent : 유저 에이전트 애플리케이션 정보
- 클라이언트의 애플리케이션 정보(웹 브라우저 정보, 등등)
- 통계 정보
- 어떤 종류의 브라우저에서 장애가 발생하는지 파악 가능
- e.g.
- user-agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/
537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36
Host : 요청한 호스트 정보(도메인)
- 필수 헤더
- 하나의 서버가 여러 도메인을 처리해야 할 때 호스트 정보를 명시하기 위해 사용
- 하나의 IP 주소에 여러 도메인이 적용되어 있을 때 호스트 정보를 명시하기 위해 사용

Origin : 서버로 POST 요청을 보낼 때, 요청을 시작한 주소를 나타냄
- 여기서 요청을 보낸 주소와 받는 주소가 다르면 CORS 에러가 발생.
- 응답 헤더의 Access-Control-Allow-Origin와 관련.
Authorization : 인증 토큰(e.g. JWT)을 서버로 보낼 때 사용하는 헤더
- “토큰의 종류(e.g. Basic) + 실제 토큰 문자”를 전송
- e.g
- Authorization: Basic YWxhZGRpbsDufhVuc2VzYW1l
응답(Response)에서 사용되는 헤더
Server : 요청을 처리하는 ORIGIN 서버의 소프트웨어 정보
- e.g.
- Server: Apache/2.2.22 (Debian)
- Server: nginx
Date : 메시지가 발생한 날짜와 시간
- e.g.
- Date: Tue, 15 Nov 1994 08:12:31 GMT
Location : 페이지 리디렉션
- 웹 브라우저는
3xx응답의 결과에Location헤더가 있으면,Location위치로 리다이렉트(자동 이동)201(Created):Location값은 요청에 의해 생성된 리소스 URI3xx(Redirection):Location값은 요청을 자동으로 리디렉션하기 위한 대상 리소스를 가리킴
Allow : 허용 가능한 HTTP 메서드
405(Method Not Allowed)에서 응답에 포함- e.g.
- Allow: GET, HEAD, PUT
Retry-After : 유저 에이전트가 다음 요청을
하기까지 기다려야 하는 시간
503(Service Unavailable): 서비스가 언제까지 불능인지 알려줄 수 있음- e.g.
- Retry-After: Fri, 31 Dec 2020 23:59:59 GMT(날짜 표기)
- Retry-After: 120(초 단위 표기)
콘텐츠 협상 헤더
🔸 클라이언트가 선호하는 표현 요청으로 요청시에만 사용함. [MDN] Content Negotiation
🔸 Accept: 클라이언트가 선호하는 미디어 타입 전달
🔸 Accept-Charset: 클라이언트가 선호하는 문자 인코딩
🔸 Accept-Encoding: 클라이언트가 선호하는 압축 인코딩
🔸 Accept-Language: 클라이언트가 선호하는 자연 언어
예시 1) Accept-Language 헤더를 통해 클라이언트가 원하는 언어를 서버에 요청.
- 한국어 브라우저에서 특정 웹사이트에 접속했을 때 콘텐츠 협상(Accept-Language)이 적용되지 않았다면, 서버는 요청으로 받은 우선순위가 없으므로 기본 언어로 설정된 영어로 응답.
- 클라이언트에서 Accept-Language로 KO를 작성해 요청한다면 서버에서는 해당 우선순위 언어를 지원할 수 있기 때문에 한국어로 된 응답을 돌려줌.
예시2) Accept-Language에 한국어를 요청했지만 서버는 한국어를 지원하지 않으며 기본 언어는 독일어로 설정되어 있음, 한국어가 안되면 영어로라도 응답을 받길 원할 경우
- 서버에서 지원하는 언어가 여러 개일 때 클라이언트가 최우선으로 선호하는 언어가 지원되지 않는다면 협상 헤더에서는 원하는 콘텐츠에 대한 우선순위를 지정할 수 있음.
- 1부터 0까지 우선순위를 부여하면 이를 토대로 서버는 응답을 지원함.
언어;q=숫자
[MDN] Language localisation

CH4. HTTPS
🔸 HTTPS는 HTTP Secure의 약자로, 기존의 HTTP와 달리 요청과 응답으로 오가는 내용을 암호화하기 때문에 프로토콜을 더 안전하게(Secure) 사용할 수 있음.
HTTP
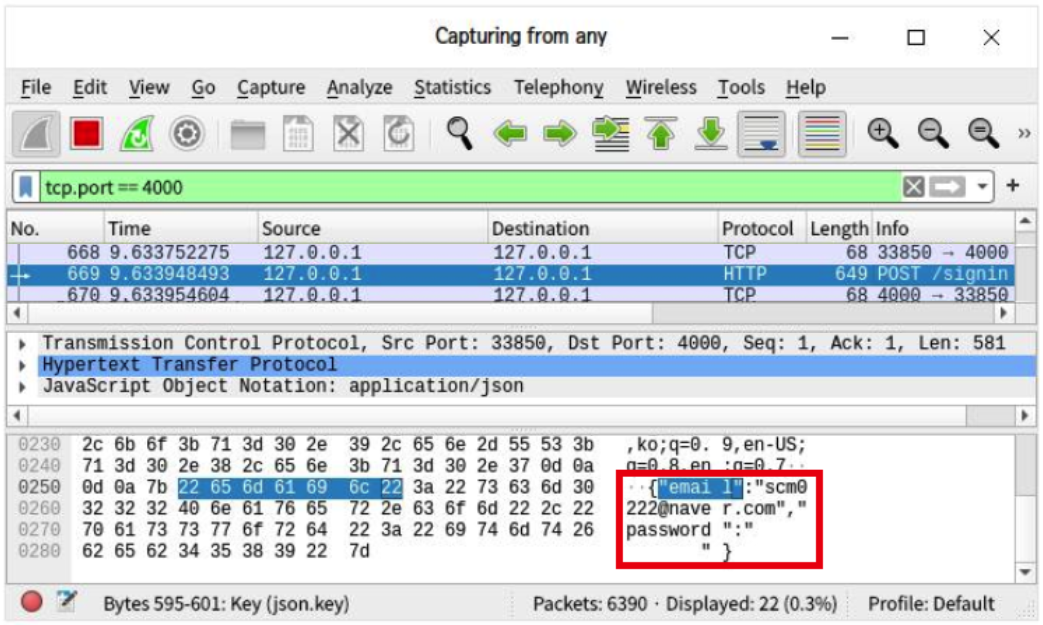
- 위 사진은 HTTP로 보낸 요청을 'wireshark'라는 패킷 분석 프로그램을 이용한 것으로 email과 password 같은 값을 그대로 볼 수 있는 것을 알 수 있음.
- 이는 제3자가 HTTP 요청 및 응답을 탈취한다면 전달되는 데이터의 내용을 그대로 확인할 수 있다는 뜻임.
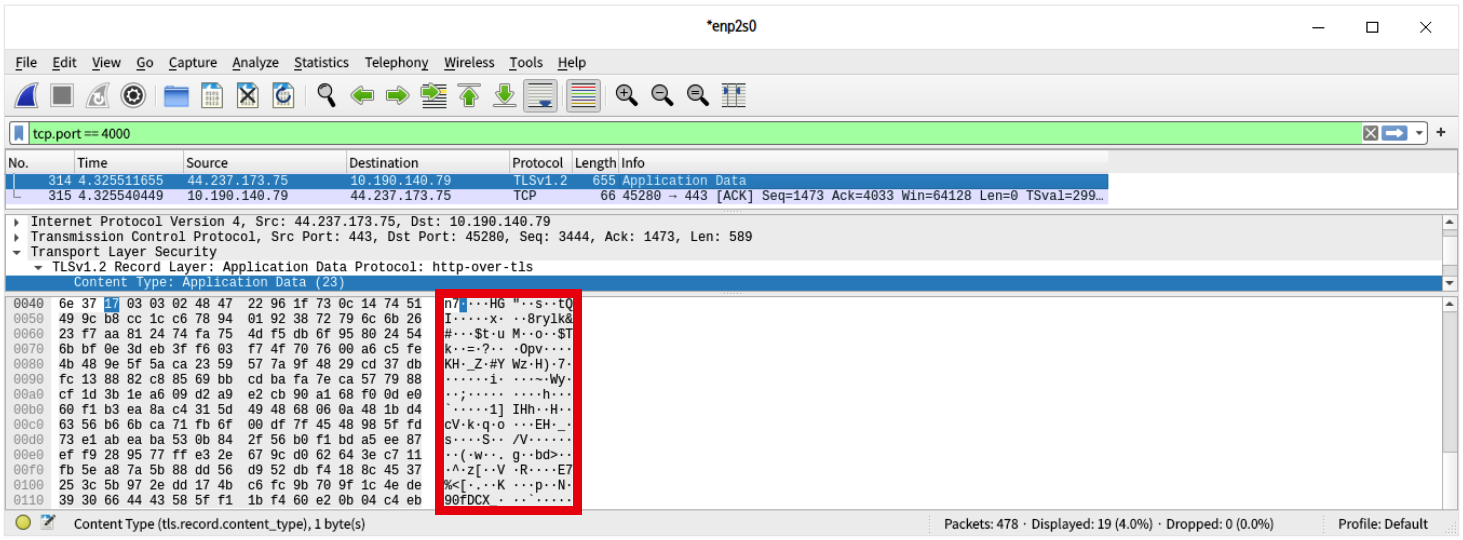
- 위 사진은 동일한 요청을 HTTPS 프로토콜로 보냈을 때를 확인한 것. 똑같은 요청임에도 데이터가 암호화되었음을 알 수 있음.
- 중간에 제3자에게 데이터가 탈취되더라도 그 내용을 알아볼 수 없음.
📌 암호화 방식
🔸 데이터를 암호화를 할 때 사용할 키, 암호화한 것을 해석(복호화)할 때 사용할 키가 필요.
🔸 암호화와 복호화할 때 사용하는 키가 동일하다면 대칭 키 암호화 방식, 다르다면 공개 키(비대칭 키) 암호화 방식.
대칭 키 암호화 방식
🔸 하나의 키만 사용, 암호화할 때 사용한 키로만 복호화가 가능.
🔸 연산 속도가 빠름.
🔸 키를 주고받는 과정에서 탈취당했을 경우, 암호화가 소용없어지기 때문에 키를 관리하는데 신경을 많이 써야 함.
공개 키(비대칭 키) 암호화 방식
🔸 두 개의 키 사용, 암호화할 때 사용한 키(공개 키)와 다른 키로만 복호화(비밀 키)가 가능.
🔸 공개 키는 공개되어 있기 때문에 누구든지 접근 가능. 누구든 이 공개 키를 사용해서 암호화한 데이터를 보내면, 비밀 키를 가진 사람만 그 내용을 복호화할 수 있음.
🔸 보통 요청을 보내는 사용자가 공개 키를, 요청을 받는 서버가 비밀 키를 가짐. 이때, 비밀 키는 서버가 해킹당하는 게 아닌 이상 탈취되지 않음.
🔸 이러한 공개 키 방식은 공개 키를 사용해 암호화한 데이터가 탈취당한다고 하더라도, 비밀 키가 없다면 복호화할 수 없으므로 대칭 키 방식보다 보안성이 더 좋음.
🔸 대칭 키 방식 보다 더 복잡한 연산이 필요하여 더 많은 시간을 소모한다는 단점.
📌 SSL/TLS 프로토콜
🔸 HTTPS는 HTTP 통신을 하는 소켓 부분에서 SSL (Secure Sockets Layer) 혹은 TLS (Transport Layer Security)라는 프로토콜을 사용하여 서버 인증과 데이터 암호화를 진행. (SSL이 표준화되며 바뀐 이름이 TLS이므로 사실상 같은 프로토콜임)
🔸 CA(Certificate Authority)를 통한 인증서 사용
🔸 대칭 키, 공개 키 암호화 방식을 모두 사용
인증서와 CA(Certificate Authority)
🔸 HTTPS를 사용하면 브라우저가 서버의 응답과 함께 전달된 인증서를 확인할 수 있음. 이러한 인증서는 서버의 신원을 보증.
🔸 이때 인증서를 발급해 주는 공인된 기관들을 Certificate Authority, CA라고 부름.
-
서버는 인증서를 발급받기 위해서, CA로 서버의 정보와 공개 키를 전달. CA는 서버의 공개 키와 정보를 CA의 비밀 키로 암호화하여 인증서를 발급.
-
서버는 클라이언트에게 요청을 받으면 CA에게 발급받은 인증서를 보냄. 사용자가 사용하는 브라우저는 CA들의 리스트와 공개 키를 내장하고 있음.
-
우선 해당 인증서가 리스트에 있는 CA가 발급한 인증서인지 확인하고, 리스트에 있는 CA라면 해당하는 CA의 공개 키를 사용해서 인증서의 복호화를 시도.
-
CA의 비밀 키로 암호화된 데이터(인증서)는 CA의 공개 키로만 복호화가 가능하므로, 정말로 CA에서 발급한 인증서가 맞다면 복호화가 성공적으로 진행.
-
복호화가 성공적으로 진행된다면, 클라이언트는 서버의 정보와 공개 키를 얻게 됨과 동시에 해당 서버가 신뢰할 수 있는 서버임을 알 수 있음.
-
복호화가 실패한다면, 이는 서버가 보내준 인증서가 신뢰할 수 없는 인증서임을 알 수 있음.
대칭 키 전달
🔸 사용자는 서버의 인증서를 성공적으로 복호화하여 서버의 공개 키를 확보.
🔸 공개 키 암호화 방식은 보안은 확실하지만, 복잡한 연산이 필요하여 더 많은 시간을 소모하기 때문에 모든 요청에서 공개 키 암호화 방식을 사용하는 것은 효율이 좋지 않음.
🔸 공개 키는 클라이언트와 서버가 함께 사용하게 될 대칭 키를 주고받을 때 씀.
🔸 대칭 키는 속도는 빠르지만, 오고 가는 과정에서 탈취될 수 있다는 위험성.
🔸 하지만 클라이언트가 서버로 대칭 키를 보낼 때 서버의 공개 키를 사용해서 암호화하여 보내준다면, 서버의 비밀 키를 가지고 있는 게 아닌 이상 해당 대칭 키를 복호화할 수 없으므로 탈취될 위험성이 줄어듬.
🔸 클라이언트는 데이터를 암호화하여 주고받을 때 사용할 대칭 키를 생성. (대칭 키를 생성하는 데에는 더 복잡한 과정이 있음.)
🔸 클라이언트는 생성한 대칭 키를 서버의 공개 키로 암호화하여 전달. 서버는 전달받은 데이터를 비밀 키로 복호화하여 대칭 키를 확보. 이렇게 서버와 클라이언트는 동일한 대칭 키를 갖게 됨.
🔸 HTTPS 요청을 주고받을 때 이 대칭 키를 사용하여 데이터를 암호화하여 전달. 대칭 키 자체는 오고 가지 않기 때문에 키가 유출될 위험이 없음.(요청이 중간에 탈취되어도 제3자가 암호화된 데이터를 복호화할 수 없음)
🔸 서버와 클라이언트 간의 CA를 통해 서버를 인증하는 과정과 데이터를 암호화하는 과정을 아우른 프로토콜을 SSL 또는 TLS이라고 말하고, HTTP에 SSL/TLS 프로토콜을 더한 것을 HTTPS라고 함.
- 서버가 (서버정보 + 서버 공개키)를 CA로 전달
- CA는 전달받은 (서버정보 + 서버 공개키)를 CA의 비밀키로 암호화해서 인증서 발급.
- 클라이언트가 서버에 요청하면 인증서를 전달.
- 클라이언트의 브라우저에 내장된 CA 리스트와 공개키를 통해 전달받은 인증서를 CA 공개키를 통해 복호화. (서버정보 + 서버 공개키) 확보.
- 클라이언트는 서버의 공개키를 통해 대칭키를 암호화해서 서버에 전달.
- 서버는 전달받은 대칭키를 서버의 비밀키로 복호화.
- 클라이언트와 서버는 복호화된 대칭키를 통해 데이터를 암호화 및 복호화.
