01. 머신러닝 정의
< Machine Learning >: 컴퓨터가 주어진 X값과 찾고자하는 값 Y 사이의 관계를 모델링하는 방법
Definition (from wiki): “A Computer program is said to learn from experience E with respect to some class of tasks T and performance measure P if its performance at tasks in T, as measured by P, improves with experience E.”
- ML은 경험 E를 통해서 주어진 T에 대하여 P로 측정한 값이 향상되는 프로그램
- 수학적으로는 주어진 입력 X에 대하여 찾으려는 값 Y 사이의 관계 f를 찾는 문제로 정의
- f는 function이며 어떤 수식으로 표현되는 함수라기 보다는 데이터와 데이터 사이의 관계로 보자
1-1. Machine Learning Tasks
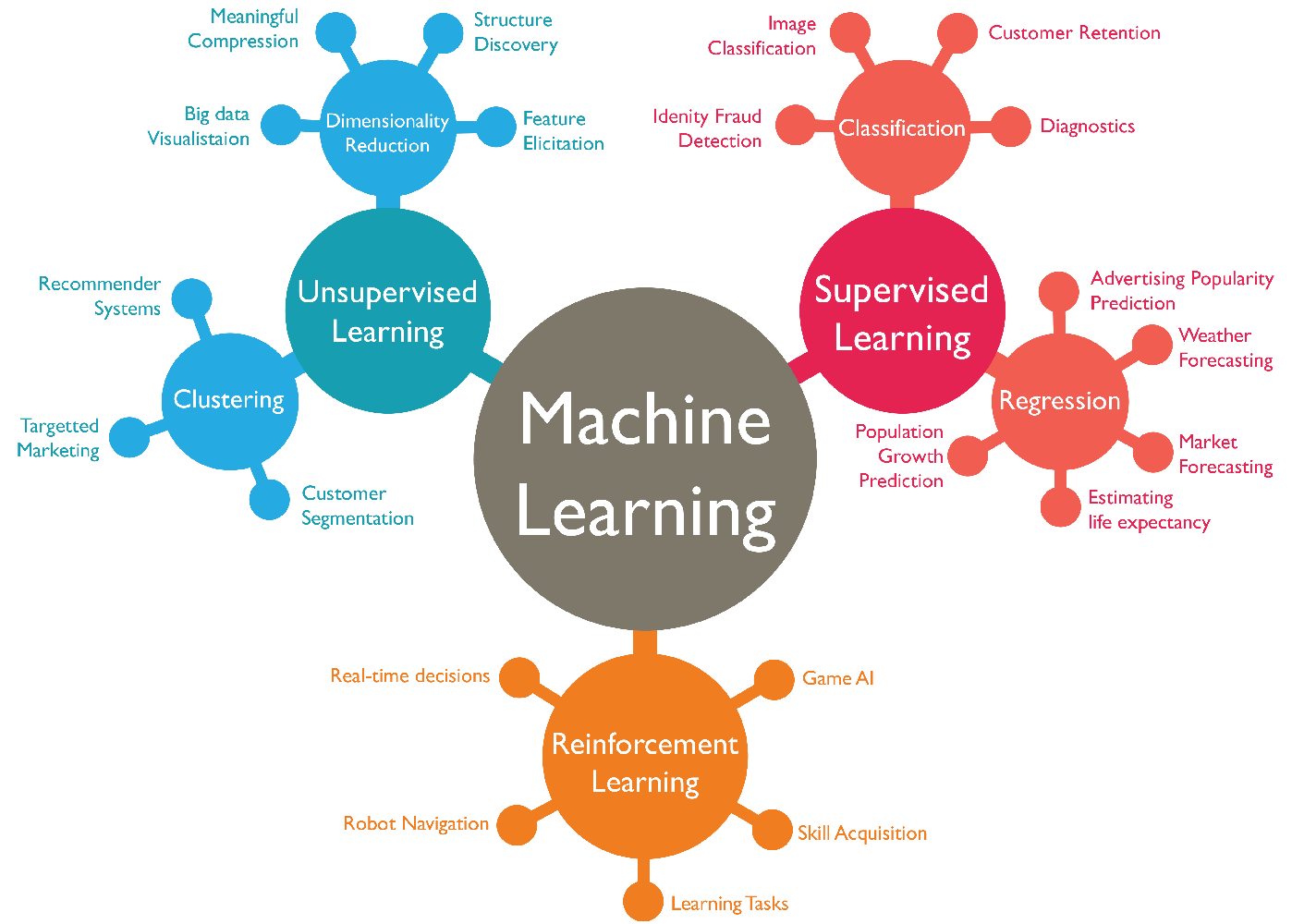
1-1-1. Supervised Learning
Supervised Learning → 입력 데이터(x)와 그에 해당하는 정답(y)가 함께 학습에 사용되는 방법론
- Classification - 주어진 데이터(x)를 몇 가지 종류(category,y)로 나누는 방법
- Regression - 주어진 데이터(x)와 관련이 있다고 생각하는 값(y) 사이의 관계를 찾는 방법
1-1-2. unsupervised Learning
Unsupervised Learning → 입력 데이터(x)만 학습에 사용되는 방법론.(y가 주어져 있지 않은 경우)
- Clustering - 주어진 데이터(x)를 몇가지 그룹(subset of X)로 나누는 방법
- Dimensionality Reduction - 주어진 데이터(x)의 중요한 정보들을 뽑아내는 방법
1-1-3. Reinforcement Learning
Reinforcement Learning → 행동의 대상(agent)과 환경(environment) 사이의 integration을 통해서 목표를 최대화(reward maximization)하는 학습 방법론.
- Real-time decisions - 주어진 환경에 대해서 reaction을 하면서, 최적화가 필요한 방법론
- Game AI - alphago,deepblue,alphastar(스타크래프트)
02. Data Split
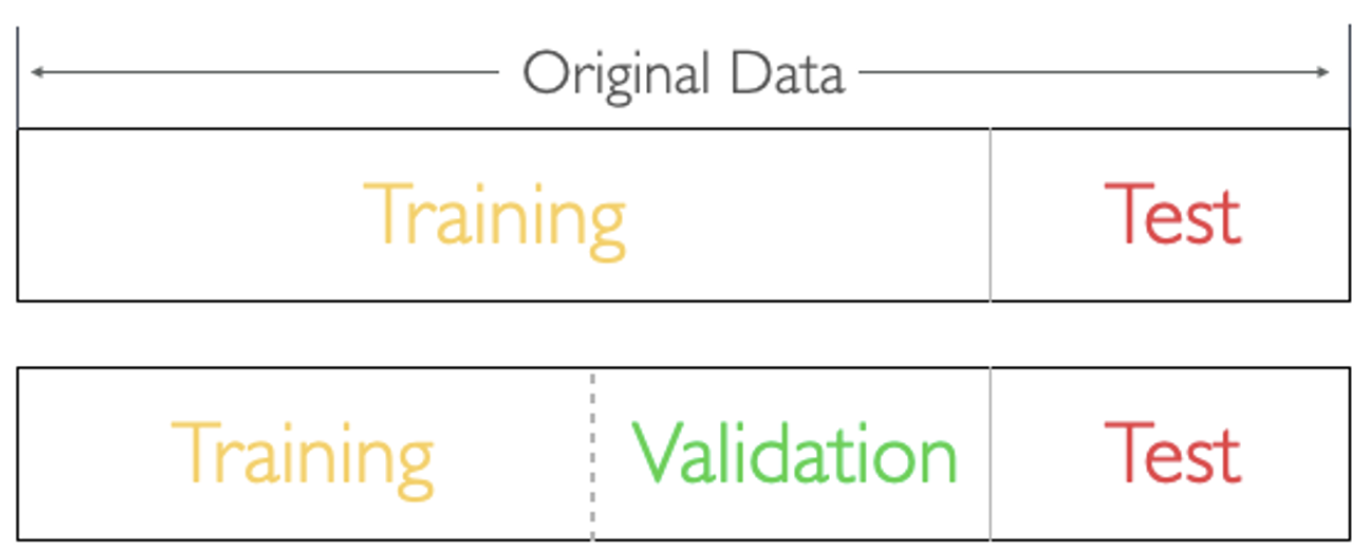
-
data split이라고 하면 train-test split 의미(train/test 데이터는 서로 겹치지 않음)
-
train data는 학습에 사용하고, test data는 평가에 사용합니다.
-
직관적인 설명을 위해 예시를 하나 가정.
- 우리는 2022년 “머신러닝” 과목의 기말고사는 100점 맞고 싶습니다.
- 우리에겐 10년치 족보 문제와 답안이 함께 있습니다. (완벽한 답안이라고 가정합니다)
- 기말고사를 100점 맞기 위해서 어떻게 공부 방법을 설계하는 것이 좋을까요?
- 8년치 열심히 공부하고(오답정리), 2년치는 시험 직전 날에 풀어본다. → train - test split
- 외우고 있는지 이해하고 있는지 모르니, 6년치를 열심히 공부하고 그때마다 2년치를 풀어보고 점수를 체크한다. 그리고 시험 직전 날에 마지막 2년치를 풀어본다. - overfitting 방지 효과도 있음. → train(60%) - validation(20%) - test split(20%)
(test 데이터가 무지막지하게 많으면 할 필요 없긴함)
- 우리의 목표는 족보에 안나왔던 실제 기말고사를 100점 맞는 것이 목표
→ 안풀어본 족보에 대한 예측(prediction for Unseen data)
03. Training
ML model이 데이터의 패턴을 파악하는 과정.
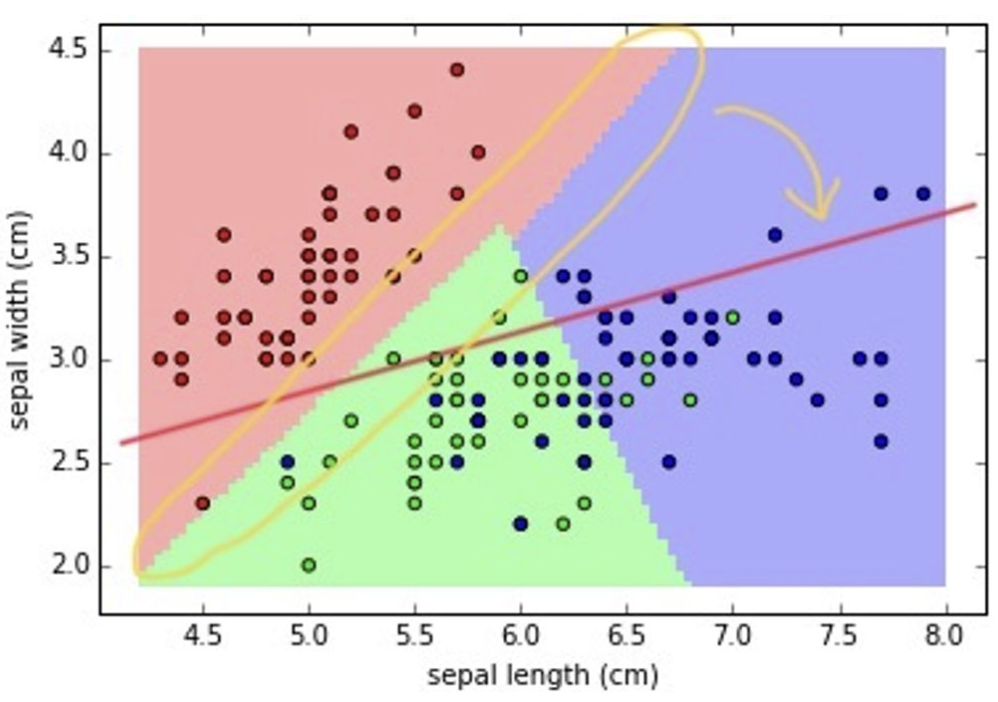
-
빨간선이 노란선으로 바뀌어 가는 과정
-
(조금 자세히) 라고 하면, w와 b가 직선을 결정
(w와 b는 parameter) -
주어진 데이터로부터 정보를 얻어서, 성능이 향상될 수 있는 방향으로 점차 정보를 업데이트해나가는 과정이 “학습(training)".
04. Inference
학습된 머신러닝 모델에 test data를 넣어서 결과를 내는 것.
-
학습된 모델과 test data가 있어야함.
-
inference에서는 학습이 일어나지 않음.(=오답 정리를 하지 않습니다.)
-
라고 하면, 와 가 직선을 결정합니다.
-
w와 b는 이미 학습 과정에서 결정되었음
-
정해진 모델에 대한 “평가”만 이루어짐.
-
이대는 객관성을 유지하기 위해서 training data가 아닌 test data를 사용
-
우리의 학습 목표는 inference의 성능이 높아지길 기대하는 것
→ “Prediction for Unseen data”
05. Feature Engineering
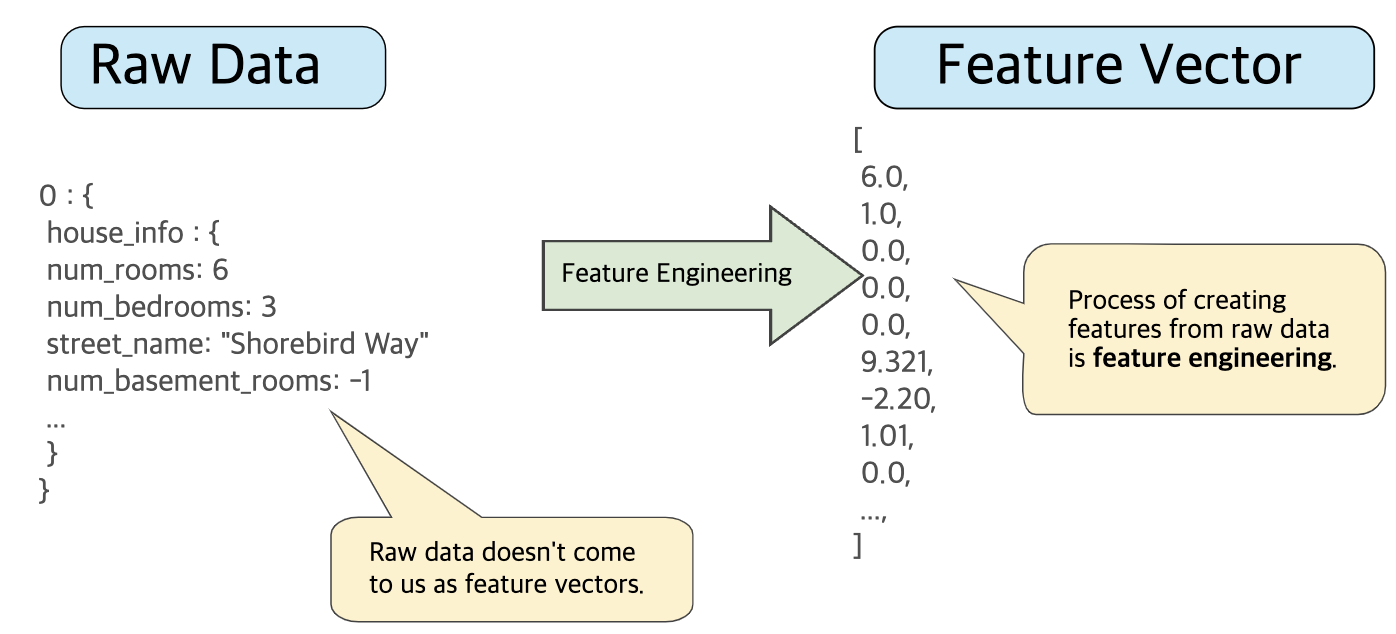
-
데이터 마트까지 구성된 데이터sms
input vector. (정형화 되어 있는 수치들) -
이 input vector를 머신러닝 모델에 사용할
feature vector로 바꾸는 작업이 feature engineering. -
feature vector란 input vector에서 머신러닝 모델이 보아야할 특징(feature)를 정의한 수치값들.
-
feature engineering에 따라 머신러닝 모델의 성능이 굉장히 크게 변함.
-
feature vector가 표현되는 공간은
feature space.
06. Loss Function
loss function : 모델의 inference 결과(예측값)와 실제 값(y) 사이의 틀린 정도를 계산하는 함수 ⇒ 비지도 학습에서는 target value(y)가 없으니 정답을 기반으로 하진 않음.
-
(predicted value)과 (target value) 사이의 차이를 계산해주는 함수.
-
차이가 적을수록 학습을 잘한 것.
-
그럼 Loss function의 결과에 영향을 주는 변수는 무엇일까?
→ parameter! (weight)
-
Loss function의 계산결과가 가장 작아질 수 있는 parameter를 찾는 것이 학습의 목표가 됨.
6-1. Loss Function Optimization
-
Loss function이 최적의 값을 가질 수 있는 파라미터를 찾기 위해서는 파라미터를 적절히 update 해야함.
-
성능이 향상되는 방향으로 파라미터 update가 중요(=loss가 줄어드는 방향)
-
Loss space에서 최적의 파라미터 조합을 찾는 문제는 수학적으로 매우 어렵(고딩때처럼 2차원이 아님)
(고차원에서의 최적화 문제는 해답을 찾기가 어렵 + 때문에 resource cost 증가) -
현실적으로 최적의 파라미터 조합을 찾을 수 있는 “
Gradient Descent Algorithm” 이 제일 많이 사용
07. Evaluation Metric
evaluation metric : 머신러닝 모델을 평가하는 기준.(=performance measure P)
-
머신러닝 모델의 성능을 평가하는 방법은 어떤 task에 따라 다름
-
각 evaluation metric마다 중요하게 보는 기준이 다름(중점으로 평가하는 항목이 당연히 다르제)
7-1. Metric for Classification

-
→ 맞은 개수의 비율.
-
→ 예측모델이 positive로 예측한 것의 맞는 비율.
-
→ 실제 positive 중에서 예측 모델이 맞은 비율.
-
→ precision과 recall의 조화평균.(둘 다 좋아야 좋게 나오는 평가 지표.)
7-2. Metric for Regression
- MSE(Mean Squared Error)→ 예측값과 실제값 사이의 차이를 제곱한 뒤 평균(unit-sensitive)
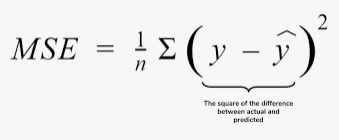
- Score → 실제 값의 분산 대비, 예측 모델이 얼마나 더 실제값을 잘 맞췄는지의 비율 계산(best 1, worst 0)
