Why?
data가 적을 때, 어떻게하면 validation도 많이 하면서 training도 많이 할 수 있을까?
교차 검증이란?
정의
train data로 모델을 훈련, test data로 모델을 검증 할때 일관된 test data를 통해 모델의 성능을 검증하고 수정하는 과정을 반복하면, overfitting 발생.
교차 검증은 train data를 train set + validation set으로 분리한 뒤, validation data를 통해 검증하는 방식
Pros
- 데이터 부족으로 인한 underfitting을 방지
- overfitting 방지
- 평가에 사용되는 데이터 편중을 막음.
- 단일 분할보다 데이터에 대한 성능 향상 + 일반화된 모델을 만들 수 있음.
Cons
- Iteration 횟수가 많기 때문에, 모델 훈련/평가 리소스 증가.
K-Fold Cross Validation
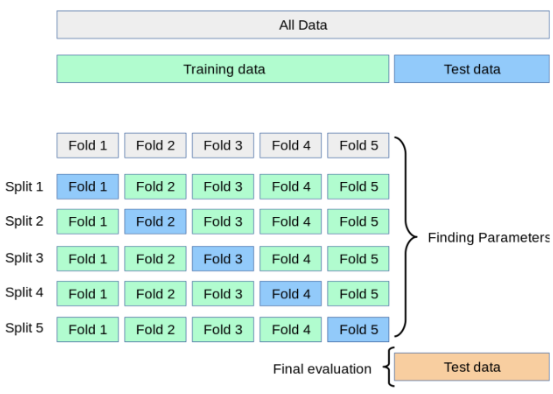
검증과정
- 전체 데이터셋을 Training Set과 Test Set으로 나눔
- Training Set를 Traing Set + Validation Set으로 사용하기 위해 k개의 폴드로 나눔
- 첫 번째 폴드를 Validation Set으로 사용하고 나머지 폴드들을 Training Set으로 사용
- 모델을 Training한 뒤, 첫 번 째 Validation Set으로 평가.
- 차례대로 다음 폴드를 Validation Set으로 사용하며 3번을 반복
- 총 k 개의 성능 결과가 나오며, 이 k개의 평균이 해당 학습 모델의 성능
Q. 애초에 작은 data 수에서 k-fold로 인해 data 크기가 더 작아졌을 때, K의 갯수는 늘려야하나? 줄여야하나?
- K 값을 더 작게 설정!!
- K를 너무 크게 설정하면 각 폴드의 data의 수가 너무 작아져 모델 평가의 신뢰성이 감소.
- 물론 상황에 맞게 조절, 보통 K=5 or 10으로 시작하는 것이 좋은 출발점
K-Fold VS StratifiedK-Fold
KFold:
기본 개념: 데이터를 n_splits 개의 연속적인 폴드로 무작위로 분할합니다.
분할 방식: 데이터를 순차적으로 분할하며, 각 폴드는 다른 폴드와 완전히 겹치지 않습니다.
사용 사례: 데이터 세트가 비교적 균등하게 분포되어 있거나, 데이터의 균일한 분할이 중요하지 않은 경우에 사용됩니다.
단점: 데이터 세트가 불균형한 클래스를 포함하는 경우, 각 폴드가 전체 데이터의 클래스 비율을 반영하지 못할 수 있습니다.
StratifiedKFold:
기본 개념: KFold와 유사하지만, 각 폴드가 전체 데이터 세트의 클래스 비율을 반영하도록 분할합니다.
분할 방식: 각 클래스의 샘플 비율에 따라 데이터를 분할하여, 각 폴드가 원본 데이터 세트의 클래스 분포를 유지합니다.
사용 사례: 클래스 불균형이 있는 데이터 세트에 적합합니다. 예를 들어, 어떤 클래스의 샘플이 다른 클래스보다 훨씬 적은 경우에 사용됩니다.
장점: 모델의 성능이 편향되지 않도록 클래스 비율을 유지합니다.
결론적으로, StratifiedKFold는 클래스 불균형이 있을 때 유용하며, 각 폴드가 전체 데이터의 대표성을 유지하도록 합니다. 반면 KFold는 더 단순한 분할 방식을 제공하며, 데이터의 순차적 분할을 통해 교차 검증을 수행합니다.
