CNN 모델의 구성
- Convolution Block: Convolution Layer → Batch normalization Layer → Activation Layer
- Pooling Layer
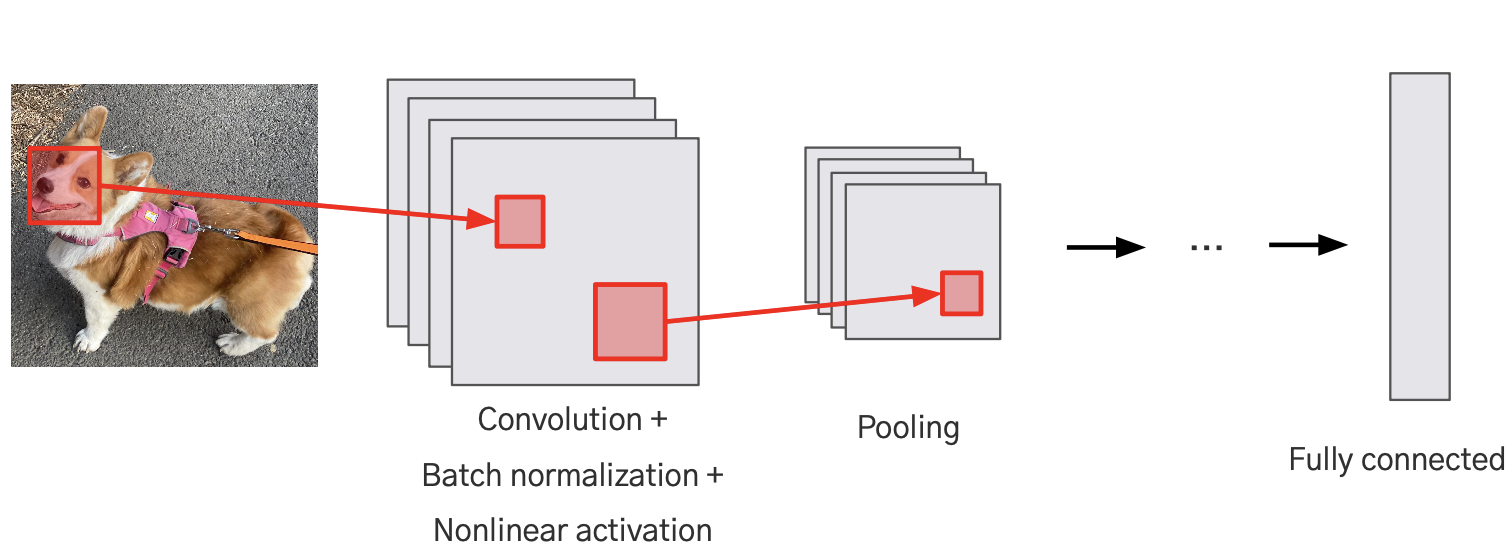
Convolution Layer
- 네트워크가 비전 태스크를 수행하는 데에 유용한 Feature들을 학습할 수 있도록 함
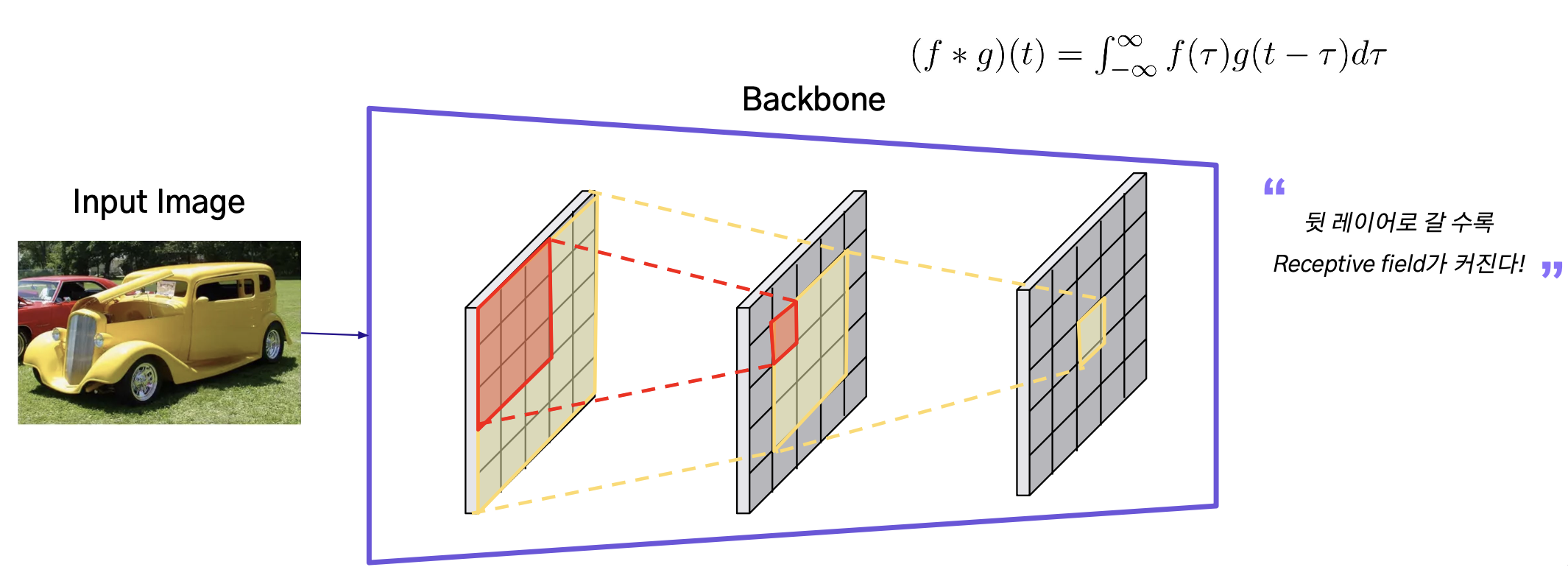
- Convolution Layer를 여러개 쌓는 경우, 뒤 레이어의 결괏값 하나를 만드는데 사용되는 이미지의 범위가 넓어진다
이를 통해, 네트워크는 저수준(low-level) 특징에서 고수준(high-level) 특징까지를 학습할 수 있음. 고수준 특징은 이미지의 보다 복잡하고 추상적인 측면(예: 객체의 일부분 또는 전체 형태)을 나타냄.
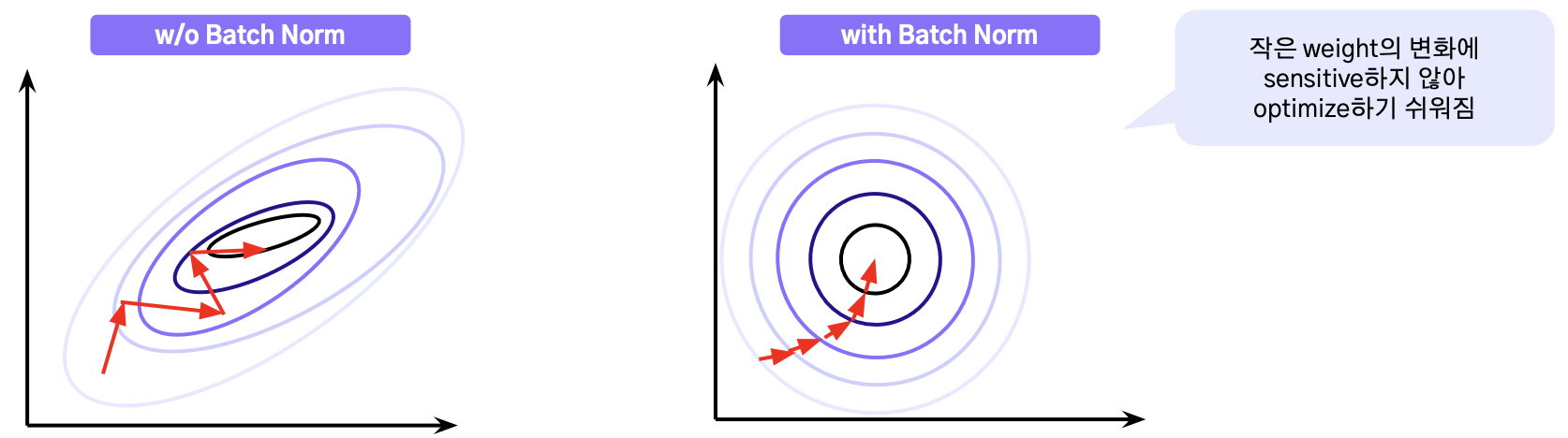
Batch Normalization
- Deep network가 잘 학습될 수 있도록 함
- Gradient flow를 개선시킴
- 더 빠르게 converge될 수 있도록 함
- 학습 시 regularization을 한 것 같은 효과를 얻을 수 있음
- 좀 더 robust한 모델이 될 수 있도록 하는 데에 기여함 (즉, overfitting을 방지하는 데에 도움을 줌)
- 보통 Convolution Layer 다음, 그리고 Activation Layer 전에 Batch Normalization을 해줌
Activation Layer
- 모델에 비선형성을 부여해 주기 위해서 사용됨
- 선형 함수의 Layer들로만 구성될 경우 여러 개를 쌓더라도 선형 함수 하나로 표현될 수 있는 모델이 될 뿐이기 때문에, 깊은 네트워크의 장점을 살릴 수 없게 됨
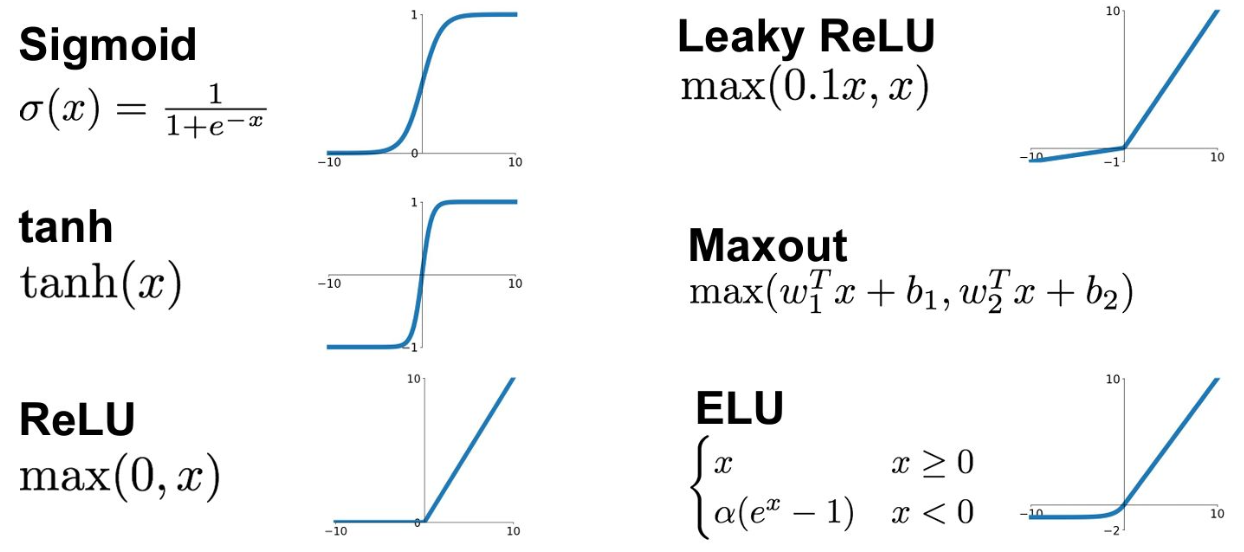
sigmoid
- Gradient 값이 kill 되는 현상이 생길 수 있음 (e.g. σ(x)의 값이 0에 가깝거나 1에 가까운 값일 경우)
- Sigmoid를 거친 결과는 0에 centroid되어 있지 않음 (항상 양수 값만 가짐)
- Exponential 함수를 계산해야 하므로 cost가 높음
tanh
- 여전히 gradient 값이 kill 되는 현상이 생길 수 있음
- Tanh를 거친 결과는 0에 centroid되어 있음
ReLu
- 양수의 값을 가질 경우 gradient가 kill되지 않음
- Computational cost가 매우 적음
- Sigmoid나 tanh 함수보다 매우 빠르게 수렴함 (e.g. 대략 6배 빠름)
- ReLU를 거친 결과는 zero-centroid가 아님
- 음수값을 가질 경우 gradient가 0이므로 update 되지 않음
Leaky ReLu
- 양수의 값을 가질 경우 gradient가 kill되지 않음
- Computational cost가 매우 적음
- Sigmoid나 tanh 함수보다 매우 빠르게 수렴함 (e.g. 대략 6배 빠름)
- ReLU를 거친 결과는 zero-centroid가 아님
- 음수값을 가질 경우 gradient가 0이므로 update 되지 않음
Pooling Layer
-
Feature Map에 Spatial Aggregation을 시켜줌
- 모델의 파라미터 수를 줄여줌
- 더 넓은 Receptive Field를 볼 수 있게 해줌
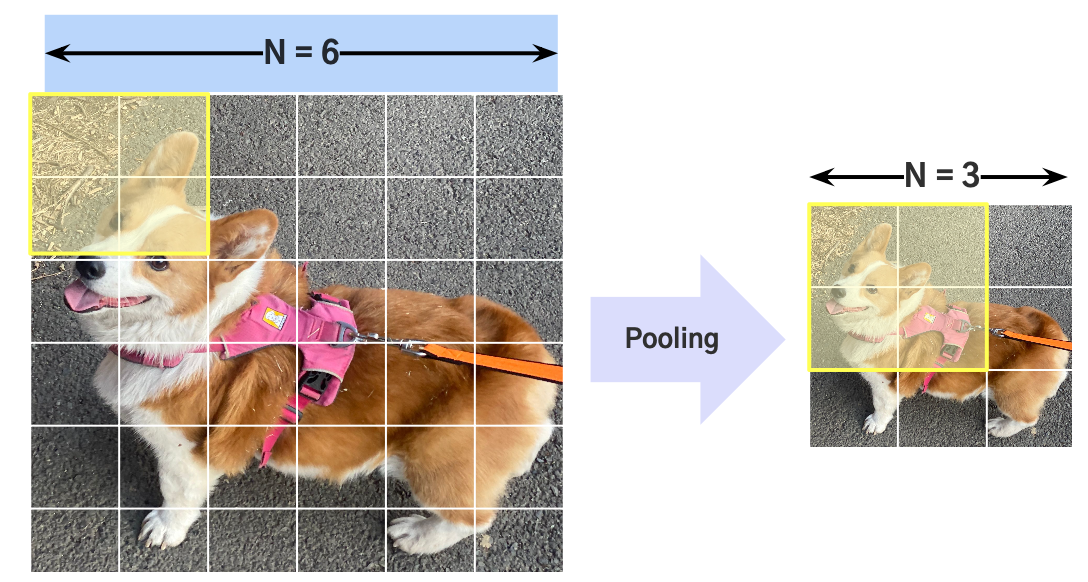
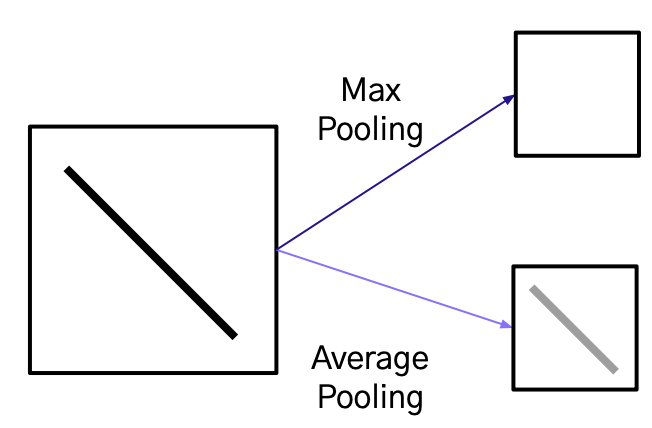
Max Pooling vs. Average Pooling
-
Max Pooling의 단점: 정보의 손실이 일어날 수 있음
-
Average Pooling의 단점: 중요한 정보가 희석될 수 있음

Real Cryptocurrency Trader & AI Engineer LV.1