[논문 세미나] TabGLM: Tabular Graph Language Model for Learning Transferable Representations Through Multi-Modal Consistency Minimization
Paper Seminar
목록 보기
16/18
Abstract
다양한 출처와 type을 가진 Tabular data를 처리하는 것은 Deep learning model에게 어려움. 반면, Attention 기반 구조의 Self-supervised learning 방식은 큰 성공을 거두었지만 Tabular data를 처리하는 데 있어서 기본적인 Linear 와 Tree 기반 구조보다 덜 효과적임.
Tabular data를 Image, Language, Graph 등의 단일 형태로 변환하는 모델을 통해 성능 향상이 있었지만, Heterogeous 특성을 가진 데이터에는 성능이 하락하는 결과를 보임. 이를 극복하기 위해 본 논문에서는 TabGLM을 제안하며 이는 Data의 각 행을 Fully-connected graph와 직렬화된 Text로 변환한 다음, 각각 GNN과 Text encoder를 사용하여 인코딩을 진행 함. 본 제안 모델은 25개의 Benchmark dataset에 대해서 상당한 성능 향상을 보여주며 SOTA를 달성함
Introduction
- Tabular data는 종종 수치, 범주 및 Text 값의 혼합으로 수집되며 이러한 특성을 Heterogeneous라고 함. 최근 연구들에서 Tabular data를 Image, Text, Graph 등 단일 형식으로 변환을 통해 의미적 또는 구조적 관계를 모델링하였음. 그러나, 단일 형식의 관계를 단일 모달 변환을 통하면 Heterogeneous 특성을 가진 데이터에 대해서는 성능이 하락함. 이는 풍부한 의미 및 구조적 뉘앙스를 유지하면서 Tabular data 내의 다양한 유형의 정보를 효과적으로 통합하는 것이 과제로 남음
- 이를 위해 본 논문에서는 Tabular data의 구조적, 의미적 정보를 효과적으로 포착하기 위해 설계된 새로운 Multi-modal architecture인 TablGLM을 제안함. 이는 각 행을 그래프와 직렬화된 Text로 변환하고 GNN과 사전 훈련된 Text encoder를 사용하여 각각 인코딩을 진행함. 이후, TabGLM의 joint semi-supervised learning strategy인 MUCOSA를 통해 그래프와 텍스트 인코더 모두에서 학습된 표현을 정렬하는 동시에 Downstream task에 적용함. 이러한 Alignment는 서로 다른 형식 간의 상호 보완적인 정보를 활용하여 학습된 표현의 품질을 향상시키는 동시에 overfitting을 방지하는 정규화 전략으로 작용함
Contributions
- Tabular data의 각 행을 Graph와 Text로 변환하여 구조적, 의미적 특징을 모두 포착하는 Multi-modal method를 제안함
- 본 논문에서 활용하는 MUCOSA는 두 가지 Modality의 정보 융합을 지원하는 동시에 overfitting을 완화하는 정규화 전략으로 작동함
- Pre-trained text encoder를 활용하여 학습 가능한 파라미터의 숫자를 효과적으로 낮출 수 있음
- 25개의 Benchmark dataset에 대해서 성능 향상을 이루었고, SOTA 성능을 달성함
Method
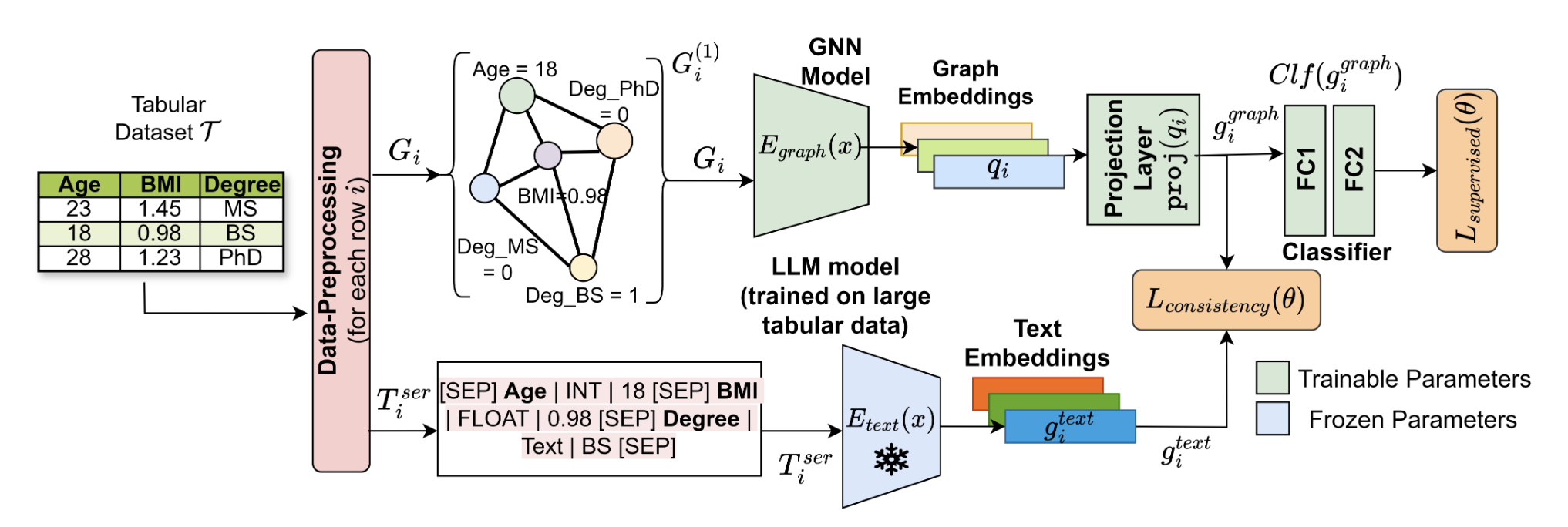
- TabGLM은 Tabular data가 주어졌을 때 각각 개의 Feature column을 가진 개의 레코드와 레이블로 구성된 행렬로 데이터를 표현하며 Test dataset에 새로 들어온 레코드가 Target class 중 하나에 속할 확률을 예측하는 학습을 수행함
TabGLM: Tabular Graph Language Model
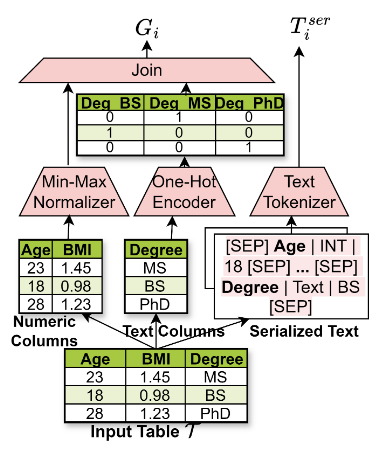
- 위 그림은 Encoding 과정을 나타낸 것으로, 입력 Table의 각 레코드를 그래프와 직렬화된 Text로 Encoding 함
Text pipeline
- Text encoder는 각 레코드의 의미 정보를 보존하기 위해 인코딩을 수행하며, 이를 위해 먼저 Tabular data의 각 행을 직렬화된 Text로 변환함. 이는 각 행이 템플릿화된 Text로 표현되도록 하며 이를 토큰화하여 텐서로 변환 후 Text encoder로 전달함
- 본 논문에서는 Text encoder로 TAPAS와 TAPEX 중 가장 성능이 좋은 Pretrained Text Encoder를 채택하는 방식을 사용함. 이는 성능과 계산 복잡성 간의 절충안을 제시하며 Ablation study를 통해 해당 결과를 보여줌
- Text encoder는 훈련 과정에서 고정된 상태로 유지되며 각 레코드에서 문맥 인식 기능을 인코딩하는 인스턴스 수준의 임베딩을 생성하는데 사용됨
Graph pipeline
- Graph encoder는 Fully-connected graph를 입력으로 받아서 각 행에 해당하는 임베딩을 학습함. Graph encoder의 목표는 원본 Tabular data 내의 열 간의 잠재적인 구조적 관계를 인코딩하는 것으로, 기존 연구에서 밝혀진 GNN 기반 방법의 한계인 Categorical feature를 Encoding하는 능력을 보완하기 위해 One-hot encoding으로 변환하는 전처리 과정을 거친 뒤 Encoder의 입력으로 전달하는 구조를 채택함
MUCOSA: Multi-Modal Consistency Learner
- 본 논문에서 사용되는 Joint semi-supervised learning 방식인 MUCOSA는 Text encoder와 Graph encoder에서 학습된 표현이 서로 직교하는 개념을 인코딩하며, 전자는 의미 정보를 후자는 구조를 인코딩 함
- 두 학습된 표현을 결합하기 위해 Consistency loss를 통해 두 Modality 간의 일관성을 최소화함
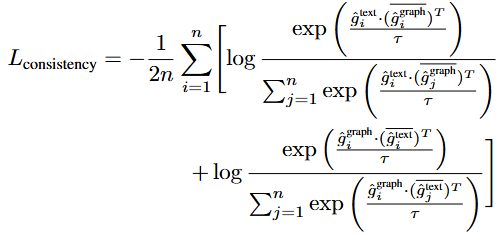
- TabGLM의 최종 목표는 Classification 이므로 해당 Task에 맞는 학습을 위해 Supervised loss를 도입하여 Classifier를 학습하며 이때 추론 과정에서 Graph embedding만을 사용하는 설정과 동일하게 Classifier는 Graph embedding만을 사용함
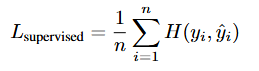
Experiments
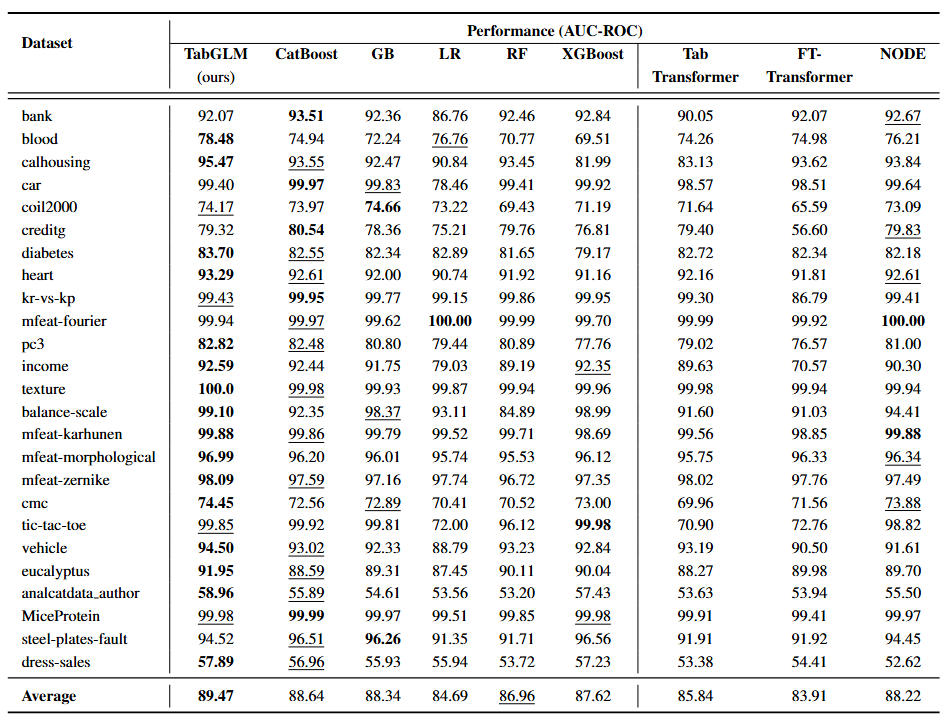
- 제안 모델인 TabGLM의 성능 검증을 위해 25개의 Benchmark dataset에 대한 성능 평가를 수행하였으며 해당 결과는 위의 표에 나와있음
- TabGLM은 CatBoost, GB, LR, RF, XGBoost와 같은 전통적인 선형 및 트리 기반 모델보다 전반적으로 우수한 성능을 보임. 특히, AUC-ROC 점수에서 LR 대비 최대 4.77%p, RF 대비 2.51%p의 상당한 성능 향상을 달성함/ 그러나, kr-vs-kp, pc3와 같은 column의 수가 적고 가단한 Dataset에서는 CatBoost와 같은 트리 기반 모델이 여전히 강세를 보임
- 또한, TabGLM은 최신 Tabular data 대상으로 개발된 딥러닝 모델들보다 뛰어난 성능을 보임. FT-Transformer 대비 5.56$p, TabTransformer 대비 3.64%p, NODE 대비 1.26%p의 성능 향상을 기록함
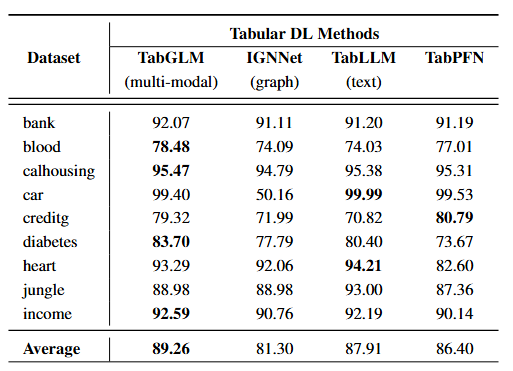
- 위 결과 표는 Uni-modal로 Tabular data를 변환해서 학습을 진행한 비교모델과 TabGLM의 성능을 비교한 것이며 text로 변환하는 TabLLM 대비 1.35%p, graph로 변환하는 IGNNet 대비 7.96%p의 성능 우위를 보임
- 위 결과는 TabGLM의 Multi-modal 설계가 Heterogeneous 데이터셋에서 구조적 정보와 의미적 정보를 모두 활용하여 기존 Uni-modal 접근 방식의 한계를 극복하였음을 보여줌
Ablation study
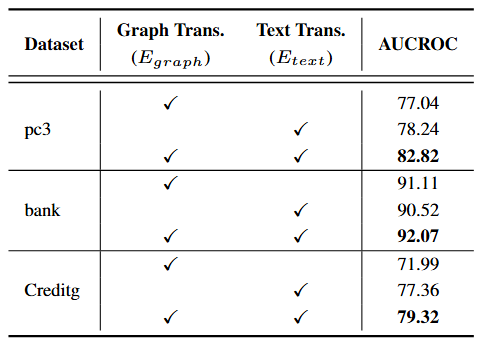
- TabGLM의 핵심 Contribution은 Tabular data의 표현 학습을 위한 Multi-modal architecture에 있음. 이를 평가하기 위해 두 개의 Uni-modal architecture로 분해하여 실험을 진행하였고 그 결과는 위 표에 나와있음
- 실험 결과, TabGLM의 Multi-modal architecture가 일관되게 Uni-modal architecture보다 우수한 결과를 보임

Researcher