Abstract
- Time series self-supervised learning은 label에 대한 의존도를 줄이기 위해 label이 없는 데이터를 활용하여 사전 훈련 하는 것을 목표로 함. 그러나, 이는 Time series 내에 존재할 수 있는 잠재적인 noise에 대한 논의가 이루어지지 않았다는 문제가 있음.
- 이러한 잠재적인 noise로 인한 문제를 해결하기 위해 모델 훈련 전에 기존의 노이즈 제거 방법을 적용하는 것이 일반적임. 그러나 이러한 전처리를 통한 방식은 아래 두가지 이유로 노이즈의 영향을 완전히 제거하지 못할 가능성이 존재함
- Time series의 다양한 유형의 노이즈로 인해 적합한 노이즈 제거 방법을 자동으로 결정하기 어려움
- 원본 데이터를 잠재 공간에 매핑한 뒤 노이즈가 증폭될 수 있음
- 따라서 본 논문에서는 시계열 데이터의 표현에 존재하는 노이즈를 완화하고 모든 sample에 대해 적합한 노이즈 제거 방법을 자동으로 선택하는 Denoising-aware Contrastive Learning (DECL)을 제안함
Introduction
- 기존 연구들에 의해 시계열 Self-supervised learning 분야에 고무적인 진전이 있었음에도 불구하고, 주어진 시계열이 깨끗하다는 가정을 기반으로하기 때문에 시계열 내 존재하는 잠재적인 노이즈에 대한 논의가 제한적임. 그러나, 많은 경우에 시계열은 자연스럽게 노이즈를 포함하고 있어 데이터의 특성을 크게 변화시킬 수 있고 이로 인해 SSL 알고리즘이 학습한 표현의 품질이 저하될 수 있음
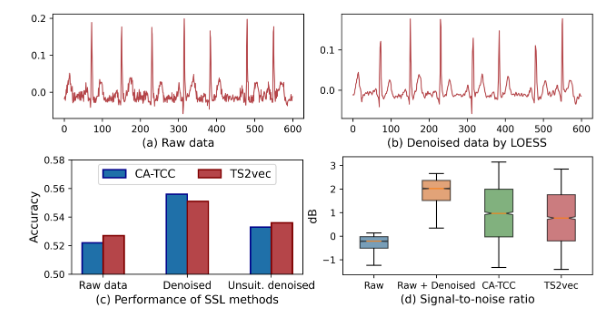
-
예를 들어, ECG 데이터셋인 PTB-XL에는 상당한 고주파 노이즈를 포함하고 있으며 기존의 시계열 SSL 기법인 CA-TCC를 적용시키면 상당히 낮은 분류 정확도를 보임. 반면 LOESS와 같은 적절한 Denoising 기법을 작용하면 정확도가 크게 향상됨을 위 그림을 통해 볼 수 있음
-
이에 따라 본 논문에서는 아래와 같은 Research Question을 탐구함
How can we effectively denoise noisy time series for SSL to learn better representations?
-
위와 같은 Denoising의 효과에도 불구하고 LOESS와 같은 전처리 방식으로 노이즈를 제거하는 것이 학습과정에서 노이즈로 인한 영향을 완전히 제거하지 못한다고 저자들은 주장함. 그 이유는 다음과 같음
1. 시계열 데이터에 존재하는 노이즈 유형이 다양하기 때문에 가장 적합한 디노이징 기법을 선택하기 어려움
- 모든 노이즈 유형을 보편적으로 처리할 수 있는 단일 Denoising 기법은 존재하지 않으므로 적절한 방법을 자동으로 선택하기 어렵고 실제로 위 그림의 (c)에서 보이듯 부적합한 Denoising 기법인 Median filter를 적용하면 오히려 분류 정확도가 떨어짐을 볼 수 있음
2. Raw data를 Latent space로 mapping 한 뒤로는 노이즈가 오히려 증폭될 수 있음
- 이를 보이기 위해 위 그림 (d)에서는 Raw data, Denoised data, 그리고 Denoised data에서 학습된 표현의 Signal-to-Noise ratio를 비교함. 그 결과, Denoised data의 SNR은 개선됨을 볼 수 있지만 이를 다시 표현 공간으로 매핑하면 오히려 SNR이 감소하여 표현 학습 과정에서 노이즈가 증 폭될 수 있음을 시사함
따라서 시계열 SSL 분야에서 노이즈를 효과적으로 완화하는 방법은 여전히 Challenge로 남아있음
- 이를 극복하기 위해 본 논문에서는 DECL을 제안함. 특히, 두 가지 새로운 설계를 포함하는 데 첫 번째로 Auto-regressive encoder를 기반으로 noise를 완화하기 위한 새로운 Denoiser-driven contrastive learning objective를 제안함. 이는 Raw time series에 기존의 Denoiser를 적용하여 positive sample을 생성하고 이어서 contrastive learning objective를 사용하여 최적화를 통해 표현이 positive sample과 가까워지도록 유도하고 negative sample로부터 멀어지도록 하여 noise를 줄이는 전략을 사용함.
- 두 번째로는 각 sample에 가장 적합한 Denoiser를 선택하는 방법을 학습하기 위해 Automatic denoiser-selection 전략을 도입함. 이는 Auto-regressive learning에서 noisy data는 일반적으로 큰 reconstruction error를 갖는 경향이 있으며 그 반대도 마찬가지일 것이라는 것에 기인하며 결과적으로 reconstruction error를 Denoiser가 sample에 얼마나 적합한지에 대한 proxy로 사용할 수 있음
Methodology
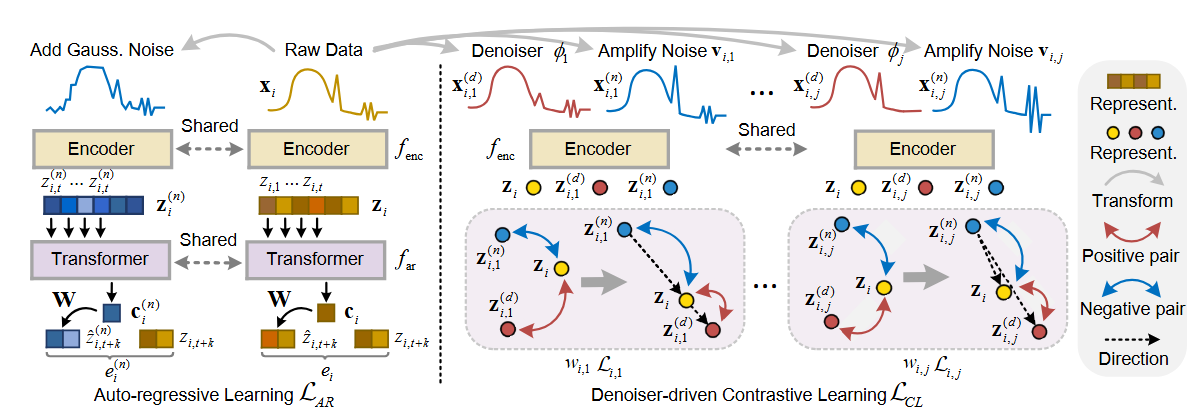
Auto-regressive Learning
- DECL에서 해당 부분은 Encoder를 통해 raw data를 잠재 공간에 매핑하고 이로인해 얻어진 표현을 SSL에 활용하는 것을 목적으로 함. 구체적으로, 이는 3-block convolution 구조인 Encoder와 Auto-regressive 모듈을 포함함. Encoder에서 얻어진 표현 를 AR 모듈을 거치면서 Context vector인 로 요약함. 해당 context vector는 미래 Time step을 예측하는 데 사용됨. 본 논문에서는 Transformer bloack을 AR module로 사용함
- 해당 과정을 통해 Encoder로 얻어진 시계열 데이터의 표현을 복원하는 방식으로 표현을 학습함
Denoiser-driven Constrastive learning
- 잠재 공간에서 Noise가 증폭될 수 있다는 점을 고려하여 본 논문에서는 Denoiser driven contrastive learning을 통해 표현에서 직접 잡음을 제거하는 것을 제안함. 이를 위해 잡음이 제거된 데이터에서 얻은 표현을 positive sample로, 잡음이 증폭된 데이터에서 얻은 표현을 negative sample로 활용함
- 이는 두 단계로 이루어짐.
(1) Raw data에 대해 노이즈 제거 및 노이즈 증폭된 sample을 생성하고 해당 representation을 획득
- Raw data에 대해 Data augmentation을 수행하는 과정으로, raw data에 적합한 Denoising 방법이 선택되면, Denoised data를 생성할 수 있음. noise가 증폭된 데이터를 생성하는 경우, 해당 유형에 대해 더 많은 noise를 추가하는 것이 원칙임. 이를 위해 raw data와 Denoised data를 비교하여 "noise"가 무엇인지 파악한 다음 이를 증폭시킴
(2) Raw data의 representation을 Positive sample과 Negative sample을 활용하여 Constrastive learning을 수행
- Data augmentation 이후에 Encoder를 통해 해당 증강 데이터의 표현을 얻고 Denoiser-driven contrastive learning을 수행함. 구체적으로, 아래 수식과 같이 해당 표현의 triplet을 구성함
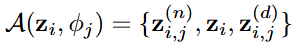
- 와 는 각각 와 의 표현이며, 대조 학습 시에 각각 negative sample과 positive sample로 간주됨. 그럼 다음 를 anchor로 삼아서 anchor를 positive sample과 가까워지게 만드는 동시에 laten space 상에서 negative sample로 부터 멀리 밀어내도록 학습됨
- 더 나아가, Latent space에서 큰 noise에서 미세한 noise로 향하는 방향은 더 나은 Denoising 효과를 나타낼 수 있기 때문에 positive sample과 negative sample이 anchor로 향하는 매핑 방향은 각 triplet마다 반대가 되도록 강제함
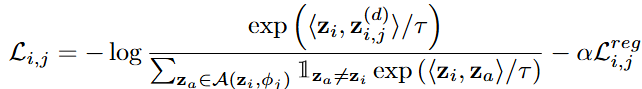
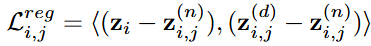
Automatic Denoiser Selection
- 많은 기존의 Denoising 방법이 노이즈 제거에 효과적인 것으로 입증되었지만 노이즈 유형이 일치하지 않으면 주어진 시계열에 대한 노이즈를 제대로 처리하지 못할 수 있음. 본 논문에서는 이러한 문제를 해결하기 위해 일반적으로 사용되는 Denoising 방법의 집합을 만들고 이들로부터 적절한 방법을 자동으로 선택하는 방식을 제안함
- 구체적으로, 본 논문에서는 로부터의 재구성 오차를 활용해서 Denoising 방법 집합 내에서 적합한 방법을 자동으로 선택하는 방식을 제안함. 해당 아이디어는 노이즈가 많은 데이터가 일반적으로 큰 재구성 오차를 발생시킨다는 점에 기인하며 적절한 Denoising 기법을 적용한 데이터는 작은 재구성 오차를, 부적절한 기법을 적용한 데이터는 큰 재구성 오차를 보이게 되는 것임
- 그러나, 재구성 오차를 그대로 학습 목표로 활용하는 것은 해당 문제를 완전히 해결하지 못할 수 있음. Auto-regressive module이 노이즈가 섞인 raw data에 과적합되어 오히려 raw data가 Denoised data보다 더 작은 재구성 오차를 가지게 될 수 있기 때문임. 이를 해결하기 위해 가 noise가 섞인 시계열로부터 Global pattern을 학습하면서 과적합을 방지하도록 돕는 추가 정규화 항을 추가하였음
- 이는 데이터를 더 강한 노이즈로 증강하고, 그 표현을 에 집어넣은 뒤, 노이즈가 덜한 raw data를 재구성하도록 강제하는 것임. 구체적으로 설명하자면 raw data에 Gaussian noise를 추가하여 데이터를 증강하고 이를 latent space에 mapping하여 다음과 같은 표현을 얻음
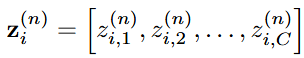
- 이후, Auto-regressive learning 처럼 에 집어넣어서 context vector와 예측치를 얻고 아래와 같은 loss로 학습이 수행됨. 이러한 Loss를 통해 예측 과정에서 노이즈가 섞인 시계열의 Global pattern을 파악하며, 이는 raw data에 과적합되는 것을 방지함.
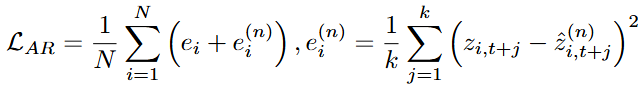
Experiments
Research Question 1 - How effective is DECL for unsupervised representation learning?
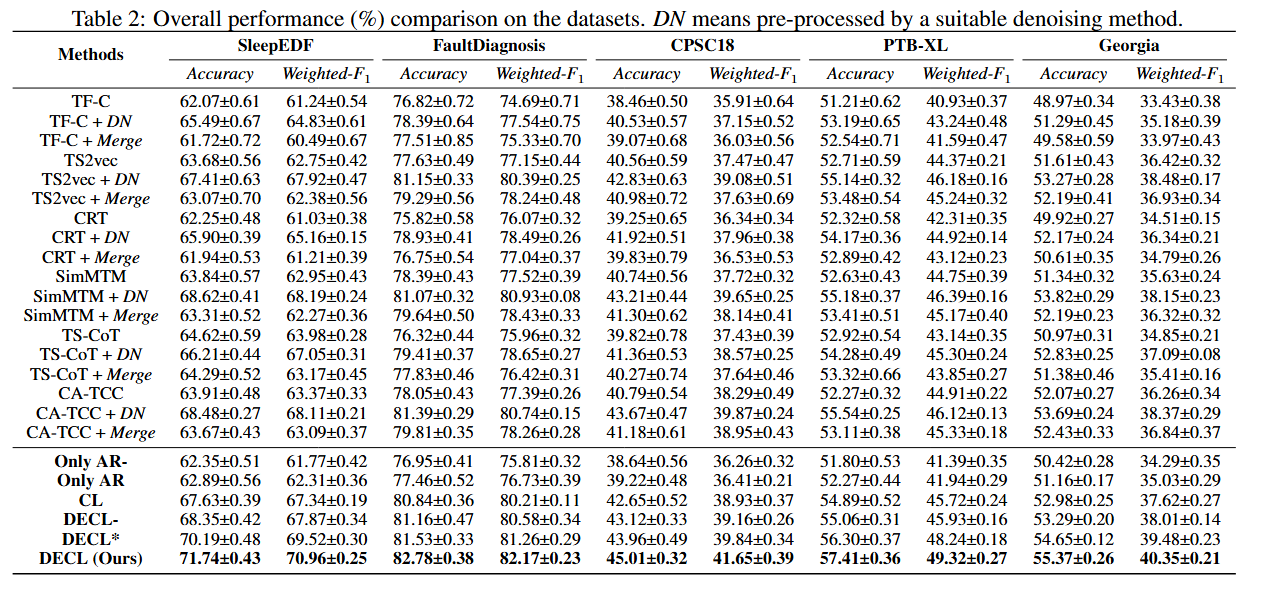
- 본 RQ를 위한 실험 과정에서 표현 학습을 위해 label이 없는 데이터로 Self-supervised learning 방법을 pre-train한 다음, 학습된 표현의 효과를 평가하기 위해 label이 있는 데이터의 일부를 사용함. 기존 연구에서 제안된 Linear evaluation scheme에 따라 사전 훈련된 모델의 파라미터를 고정하고 이를 Encoder로 간주한 다음 Encoder 다음의 Linear classifier를 훈련시킴
- 실험 결과, 기존의 SSL 방법은 노이즈가 섞인 데이터에서 최적이 아닌 성능을 달성하며, 모든 Denoising 방법을 직접 결합하여 전처리하면 만족스럽지 못한 성능이 도출됨. 이는 특정 Denoising 방법이 노이즈 유형과 일치하지 않을 때 데이터에 추가 노이즈를 유발할 수 있기 때문이라고 저자들은 말하고 있음
- 또한, DECL은 다른 SSL 방법보다 우수한 성능을 달성하며 이는 본 논문의 방법인 DECL이 적절한 Denoising 방법을 활용하여 노이즈를 완화하고 Representation learning을 수행하기 때문임
Research Question 2 - Is the method effective with fine-tuning?
- 본 RQ는 실제 환경과 유사하게 소량의 labeled data만 사용 가능한 시나리오를 시뮬레이션하기 위해, label을 사용하여 Pre-trained model을 fine-tuning하고 그 효과를 조사하기 위해 도입되었으며, 본 RQ를 위한 실험 설정은 두 가지가 있음
Fine-tuning on the Source Dataset
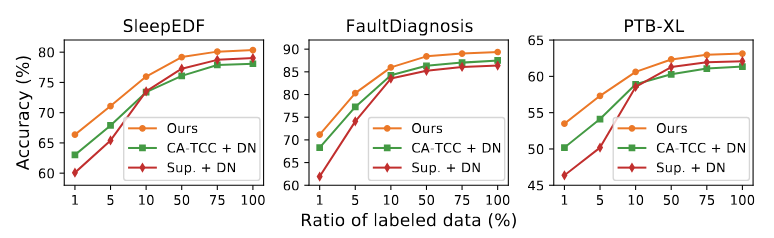
- 첫 번째 실험 설정은 Label이 없는 데이터로 사전 학습을 수행한 뒤, 동일한 데이터셋으로 fine-tuning을 수행한 것임. 아래 그림에서 보이듯이 DECL은 fine-tuning 시 다양한 label ratio를 적용할 때 기존 SSL 기반 모델과 Supervised 기반 모델의 성능을 능가함을 보임
Fine-tuning on New Dataset
- 두 번째 실험 설정은, 사전 학습된 데이터셋과 다른 데이터셋으로 fine-tuning을 수행하는 것임.
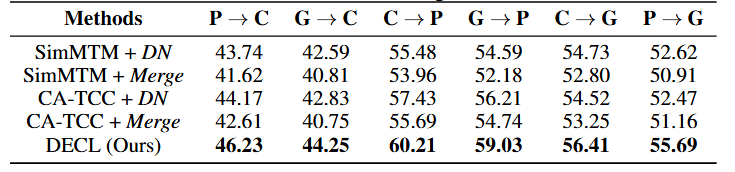
- 위 표를 보면 알 수 있듯이, Denoising 방법에 따른 성능 차이를 확인하 수 있음. 또한, DECL이 다른 비교모델 대비 cross-domain 실험에서 높은 성능을 기록함. 이는 DECL이 유용한 표현 학습에 대한 노이즈의 영향을 완화하고 잘 일반화될 수 있음을 입증한 것임
Research Question 3 - What are the effects of each component?

- 위 표를 통해 확인할 수 있는 Ablation study의 결과를 보면, 만을 사용하면 성능이 만족스럽지 못하다는 것을 알 수 있으며 이는 잠재 공간의 노이즈를 제거할 수 없어서 표현 학습을 방해하기 때문이라고 저자들은 말하고 있음. 또한, 을 활용하지 않은 실험과 비교했을 때 이 정규화 항이 전체 성능에 도움이 된다는 것을 알 수 있음
- 또한, 대조학습의 triplet을 만들고 contrastive learning을 수행할 때 방향을 강제하는 제약 조건이 표현 학습의 노이즈를 제거하는 데 도움이 된다는 것을 알 수 있음
Research Question 4 - Is it robust with varied degrees of noise?
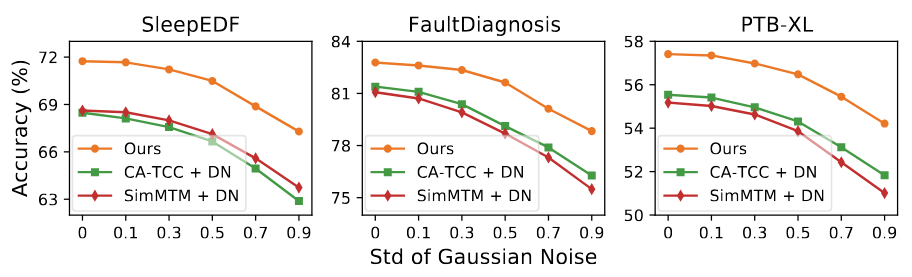
- Noise가 섞인 비율을 조정하는 실험 결과, 더 많은 양의 Noise를 유도하면 모델의 성능이 점진적으로 저하된다는 사실과 DECL이 지속적으로 비교 모델 대비 우수한 성능을 보인다는 것을 알 수 있음. 이는 DECL이 모든 sample에 적합한 Denoising 방법을 선택하고 대조 학습을 통해 표현 공간 상에서 노이즈를 더욱 줄이기 때문이라고 저자들은 말하고 있음
Research Question 5 - How sensitive is it to the hyper-parameters?
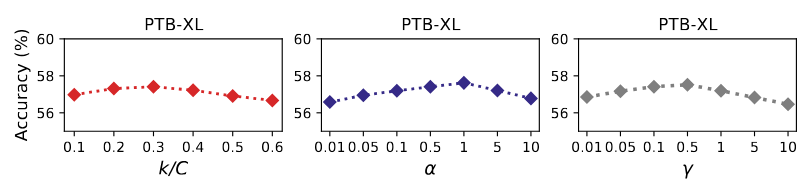
- Hyper-parameter 세 가지를 다르게 설정하여 비교 실험 결과, 모든 hyper-parameter에서 robust한 성능을 관찰할 수 있음
Conclusion
- 본 논문에서는 시계열 데이터의 Self-supervised learning을 위해 원본 데이터에 섞인 노이즈의 영향을 완화하는 연구를 진행함. 이에 따라 표현 학습에서 노이즈 제거를 위한 DECL이라는 방법을 제안함. 이 방법은 모든 sample에 적합한 Denoising 방법을 자동으로 선택하고, noise가 없는 표현을 얻기 위해 맞춤형 대조 학습을 수행함. 실험 결과, 비교 모델 대비 우수한 결과를 도출함

Researcher