모델링
- 데이터로부터 패턴, 규칙을 찾아 수학식으로 정리하는 과정 -> 오차를 최소화하는것이 포인트
모델링의 목표
- 과거 (train)와 미래(val)을 동시에 잘 예측하는 모델 예측
- 표본 -> 모집단!
평가 방법
1. 회귀 평가방법
1-1) R^2 Score : 평균 모델의 오차 중에서 회귀모델이 해결한 비율
1-2) MSE : 오차양
1-3) RMSE : 오차양
1-4) MAE : 평균오차
1-5) MAPE : 평균오차율
2. 분류 평가방법
2-1) Accuracy : 정분류률
2-2) Recall : 재현율(실제) tradeoff 관계
2-3) Precision : 정밀도(예측) tradeoff 관계
2-4) F1 : Recall과 precision 조화 평균
성능
- 성능 향상 : 편차와 오차를 줄인다
1) 모든 조건이 같더라도 데이터가 달라진다면 성능이 변한다.(Variance)
2) 현실세계와 모델간에는 오차가 존재(Bias)
==> 같은 알고리즘, 하이퍼파라미터 값, 데이터가 달라짐에 따라 성능의 편차 발생
1.성능의 평균
1-1) k-fold cv(교차검증)
data k개로 나누기, 각 fold가 한번씩 val 되도록 교차검증
2. 성능 향상 : 튜닝
2-1) 랜덤서치
- 값의 범위 지정
- 시도횟수 지정
- 횟수만큼 시도후 가장 성능이 좋은 모델 선정
2-2) 그리드서치
- 값의 범위 지정
- 실행, 모든 조합을 다 시도
3. 편차와 오차 동시에 줄이는 법
3-1) 학습 데이터를 늘린다(Learning-curve)
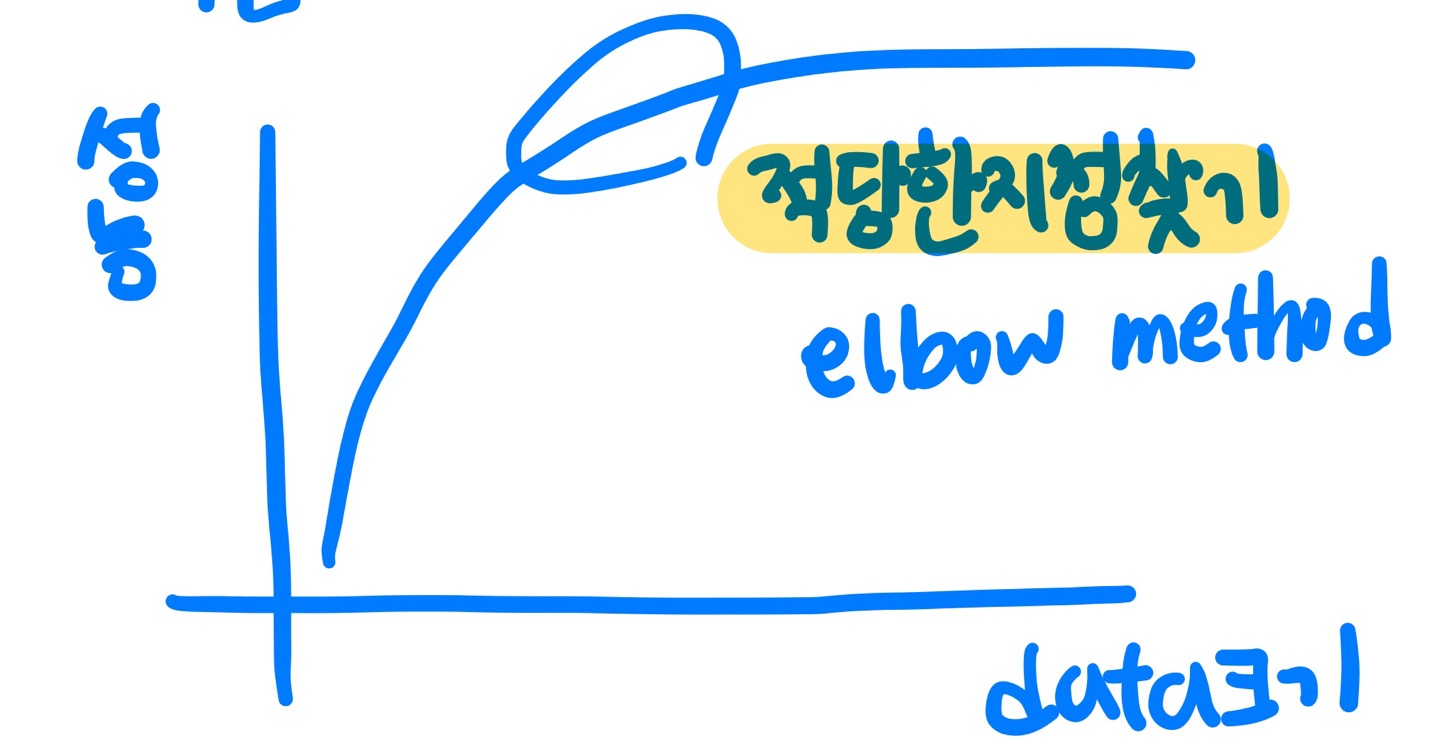
과연 data양이 많을수록 좋을까?
-> data가 많아지면 variance, bias 개선됨, 하지만 모델의 복잡도도 고려해야함
3-1-2) 모델의 복잡도
train의 패턴들이 모델에 반영 정도
1) 선형모델 : feature 개수
2) other : 하이퍼파라미터 조절
3-1-3) 과적합 : train의 패턴이 모델에 과하게 반영됨 -> 튜닝 : val 성능의 고점 파악!!
3-2) 성능 튜닝
알고리즘
1. 선형회귀
- 오차를 최소화하는 직선 y=w1x1+w0
- 전제조건 : NAN, 가변수화, 독립
- 성능 : 변수 선택 중요, 변수 선택법!, 변수들은 독립성 가정 충족 -> 다중공선성문제
2. 로지스틱회귀
- 오차를 최소화하는 직선 -> 로지스틱 함수로 변환 (-무한 ~ 무한) -> (0 ~ 무한) -> (0 ~ 1)
- 전제조건 : NAN, 가변수화, 독립
- 성능 : 변수 선택 중요
3. knn
- 예측할 데이터와 train set과의 거리 계산, 가장 가까운 평균으로 예측 (vs DBSCAN)
- 전제조건 : NAN, 가변수화, 독립
- 성능 : k가 작을수록 복잡(k의 max = train 수), 거리계산법에 따라 성능이 다름
4. Decision Tree
- 정보정달량 = 부모의 불순도 - 자식의 불순도, 정보정달량이 가장 큰 변수로 split
- 전제조건 : NAN, 가변수화, 스케일링(거리로 고려하는 알고리즘)
- 성능 : max_depth 클수록 복잡, min_samples_leaf 작을수록 복잡
5. SVM
- 마진을 최대화 하는 결정경계선
- 전제조건 : NAN, 가변수화, 스케일링(거리로 고려하는 알고리즘)
- g: 곡률의 반경 / c: 오류에 대한 허용정도
- 성능 : c가 클수록, gamma가 클수록 복잡
6. 랜덤포레스트
- 트리 여러개 -> 각평균 예측으로 최종 예측
- 전제조건 : NAN, 가변수화
- 성능 : 트리의 개수 100정도면 충분 오히려 크면 과적합 -> 데이터 건수를 늘려도 n_estimators 수평유지, 트리가 많은 의미가 없음
7. XGB
- 트리 여러개, 오차를 줄이는 방향으로 모델 생성 -> 트리를 더해 하나의 모델로!
- 전제조건 : NAN, 가변수화
- 성능 : n_estimators 클수록, max_depth 클수록 복잡, learning rate

소프트웨어 엔지니어