Data Understanding
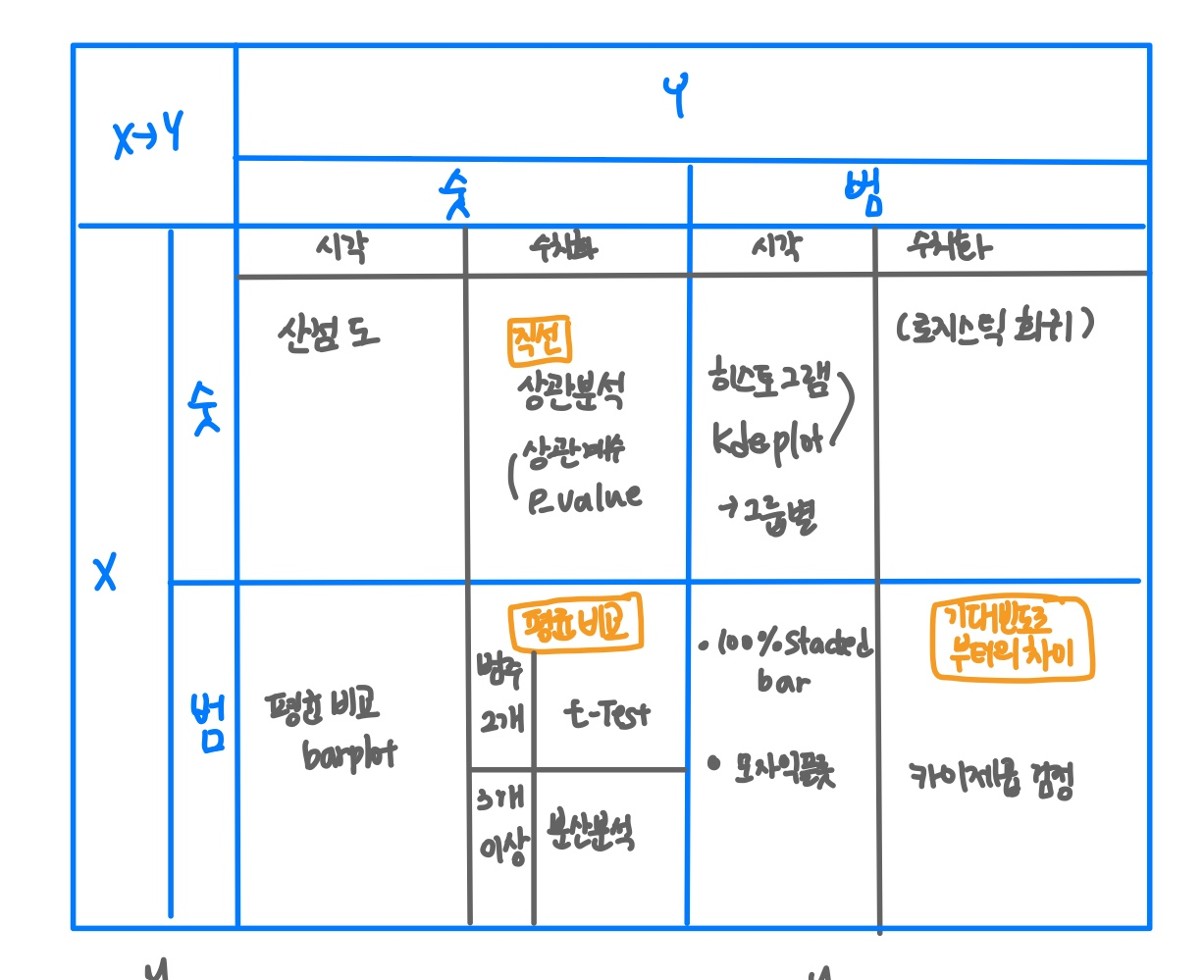
이변량 분석
| x->y | 숫자 | 범주 |
|---|---|---|
| 숫자 | 산점도, 상관분석, 상관계수, P_value | 히스토그램, kdeplot, 로지스틱 회귀 |
| 범주 | barplot, T-test, anova | 모자익플롯, 카이제곱검정 |
- 대립가설 : 관련이 없다. -> 현재의 가설
- 귀무가설 : 관련이 있다. -> 새로운 가설
수치화
- p_vaule : 대립가설이 틀릴 확률
- t-test : 두 평균의 차이를 표준오차로 나눈값
- 분산분석(anova) : 여러 집단 간의 차이 , 전체 평균 사용
- 카이제곱검정 : 클수록 기대빈도로부터 실제값에 차이가 크다
수치화 해석
- p_vaule : <0.05 -> 대립가설이 틀릴 확률이 0.05 이하로 대립가설이 참
- t-test : <-2 or 2> -> 대립가설에 참
- 분산분석(anova) : 2~3 -> 대립가설이 참
- 카이제곱검정 : 자유도의 2~3배 크면 -> 대립가설 참

소프트웨어 엔지니어
이변량 분석에 대해 이해하기 좋았습니다! 감사합니다 :)