3월 8일에 Google Cloud Onboard에 다녀왔다. 팬데믹 현상 이후에 Google Cloud에서 처음으로 개최된 오프라인 행사이며 클라우드의 여러 Product에 대한 소개를 들었다.
환영사 및 Google Cloud 개요
발표자 : 진광훈, Customer Engineer
🙌🏻 Intro to Google Cloud
Google Cloud도 다른 Public Cloud를 제공하는 회사 못지 않는 큰 규모의 데이터센터를 지니고 있으며 대표하는 카테고리 세 가지다.
-
친환경 클라우드: Google Cloud Region Picker 기능을 통해서 친환경적인 Region을 추천한다.
-
해저 광케이블에 진심인 회사: Google Cloud Location에 접속하면 광케이블 설치되어 있는 지역을 확인할 수 있다.
-
다양한 서비스 제공: googlecloudcheatsheet.withgoogle.com에서 다양한 서비스 목록에 대해서 확인할 수 있다.
Google Cloud는 Multi-Region(Europe), Region(europe-west2), Zone(europe-west2-a)으로 리소스를 구성한다.
☄️ Accessing Google Cloud
구글 클라우드에 접근하는 방법은 다음과 같습니다.
-
리소스 계층 수준 신뢰 경계를 정의한다.
-
사용하는 모든 구글 클라우드 서비스는 프로젝트와 연결되며, 프로젝트가 하나의 그룹화 할 수 있는 요소이다.
- 프로젝트 식별 속성: 프로젝트 ID, 프로젝트 Name, 프로젝트 Number
-
유연한 관리를 제공하는 폴더
-
조직(Organization) 노드는 최상위 권한이며, 프로젝트를 구성한다.
- Google Cloud에서 워크 스페이스 생성 시 조직은 알아서 생성된다.
-
IAM(Identity and Access Management) 리소스 계층의 예
- 리소스에 대한 정책이 설정되며 리소스는 상위 정책을 상속한다.
- 덜 제한적인 상위 정책이 더 제한적인 리소스 정책에 우선한다.
- IAM 정책은 네 가지 유형의 보안 주체(who)를 가진다
- Google account, Cloud Identity User
- Service Account
- Google Group
- Cloud Identity or Google Workspace domain
- IAM 역할은 관련 권한 모음입니다. (사용자에게 특정 항목에 대한 역할이 할당된다)
🔥 누가(Who) + 무엇을 할 수 잇나(can do what) + 어떤 리소스에 (on which resource)
-
서비스 계정(Service Account)은 서버 간 상호 작용을 제어한다.
- 프로젝트에서 서버 간 상호 작용을 수행하기 위한 ID 제공한다.
- 한 서비스에서 다른 서브로 인증하는데 사용한다.
- 리소스가 사용하는 권한을 제어하는데 사용한다.
-
서비스 계정 및 IAM
- 서비스 계정은 키를 사용하여 인증하며, 사전 정의된 IAM 역할 또는 Custom IAM 역할을 서비스 계정에 할당한다.
-
구글 클라우드와 상호작용하는 네 가지 방법
- Cloud Console : Web UI
- Cloud Shell & Cloud SDK : CLI
- Google Cloud Mobile App : for iOS and Android
- Rest API : for custom applications
구글의 혁신적인 클라우드 데이터베이스 확인하기
발표자 : 최유정, APAC Technology Practice Specialist, Data Management
Google Cloud는 15개의 카테고리 기반의 410개의 DBMS를 보유하고 있다. DT(Digital transformation)를 위한 근간은 데이터베이스이며, Google Cloud는 데이터베이스 유지보수에 대한 Managed 벤더를 제공한다.

Challenge별 데이터 베이스 추천
💡 Challenge 1
1. 익숙한 관계형 DB를 사용하고 싶을 때
2. 데이터베이스 관리(HA, 확장, 보안, 백업/복구, DR 등) 관리를 손쉽게 하고 싶을 때
3. On-premise 데이터베이스를 최소한의 노력으로 클라우드로 이관하고자 할 때
4. 관계형 데이터베이스의 데이터를 분석하고 싶은데, Data Pipeline 구성을 구성할 때
∴ Cloud SQL: Fully managed relational dabase service
- Supports PostgreSQL, MySQL, SQL Server
- Fully Managed & Enterprise Ready
- Trusted, Developer Friendly
- Monitoring: CPU 뿐만 아니라, SQL 레벨까지
- BigQuery to Cloud SQL federation : Easily analyze data, EXTERNAL_QUERY()
- 무중단 마이그레이션 서비스 제공
💡 Challenge 2
1. 시스템 응답 시간을 더 빠르게 하고 싶을 때
2. 데이터베이스 읽기 부하가 많은데 확장을 할 지? 다른 방안이 없을 지 모색할 때
3. 추가 인력을 투입하기 어렵고 관리형 서비스를 찾을 때
∴ Memory Store
💡 Challenge 3
1. Heavy workload를 위한 더 나은 성능을 제공하는 Database가 필요할 때
2. 대쉬보드 및 리포팅을 위한 OLAP 쿼리 성능도 빠르게 수행하고 싶을 때
3. 오픈소스 데이터베이스를 더 관리하기 쉬운 방법을 찾을 때
4. 머신 러닝 모델을 손쉽게 활용하는 방안이 필요할 때
∴ AlloyDB: PostgreSQL + Cloud native architecture + DNA of AI/ML
-
Better Performance
- OLTP(Online Transaction Processing): 4x faster
- OLAP(Onlen Analytical Processing, Columnarization): 100x faster
-
Easy to manage with advanced ML(Machine Learning)
- Intelligent Transactions - Vertex AI functions(Built in)
💡 Challenge 4
1. 모바일과 웹 등 Multi Devices를 지원하는 애플리케이션을 작성해야 할 때
2. 디바이스 간 동기화를 고려할 때
3. 오프라인시에도 서비스를 지속하고 싶고, 네트워크 복구 시에 동기화를 고민할 때
4. 워크로드 증가에 따른 확장 및 관리하기 쉬운 데이터베이스를 찾을 때
∴ Firestore
💡 Challenge 5
1. 클릭스트림이나 IoT처럼 엄청나게 쏟아지는 데이터를 빠르게 저장해야 할 때
2. 스키마를 미리 예측하기 어려울 때
3. 처리량이 예측이 안되는데, 나중에 무중단으로 읽기/쓰기 모두 확장해야 할 때
4. 글로벌 서비스를 하고 싶은데 동기화를 쉽게 구현하고 싶을 때
∴ Cloud Bigtable: Low latency and high throughput at scale
- GMail이 Cloud Bigtable로 구현 되었다가, 현재는 Spanner로 이관
- Spotify는 Bigtable을 통해 75% 비용을 감소하였음
💡 Challenge 6
1. 무중단 시스템을 위해 다운타임을 최소화 하고 싶을 때
2. 워크로드에 따라 무중단으로 읽기/쓰기 모두 확장해야 할 때
3. RDBMS처럼 SQL도 사용하고 스키마 관리 및 트랜잭션 처리도 해야할 때
4. 글로벌 서비스를 하고 싶은데 강력한 일관성을 보장해야 할 때
∴ Spanner: 분산 환경, 트랜잭션 관리
Google Compute Engine 입문하기
발표자 : 진광훈, Customer Engineer
📌 개요
Compute Engine이란?
- Google 인프라에서 가상 머신을 만들고 실행할 수 있는 컴퓨팅 및 호스팅 서비스
- 우수한 확장성과 성능, 가치를 제공하며 대규모 컴퓨팅 클러스터를 간편하게 실행할 수 있게 해준다.
- 관리형 가상 머신과 고객 친화적인 가격을 제공한다.
- 가상 머신 선택
- 메모리 및 컴퓨팅 집약적인 애플리케이션에 대형 VM 사용
- 복원력을 위해 자동 크기 조정(Autoscaling) 사용, 확장 가능한 애플리케이션
💻 가상 머신 인스턴스 / VM Instances 유형
가상 머신 인스턴스 / VM instances

가상 머신 인스턴스 : 이름 규칙
계열 내의 머신에서 standard, highcpu, highmemory로 구분되는 기준은 vCPU:Memory 비율이다.
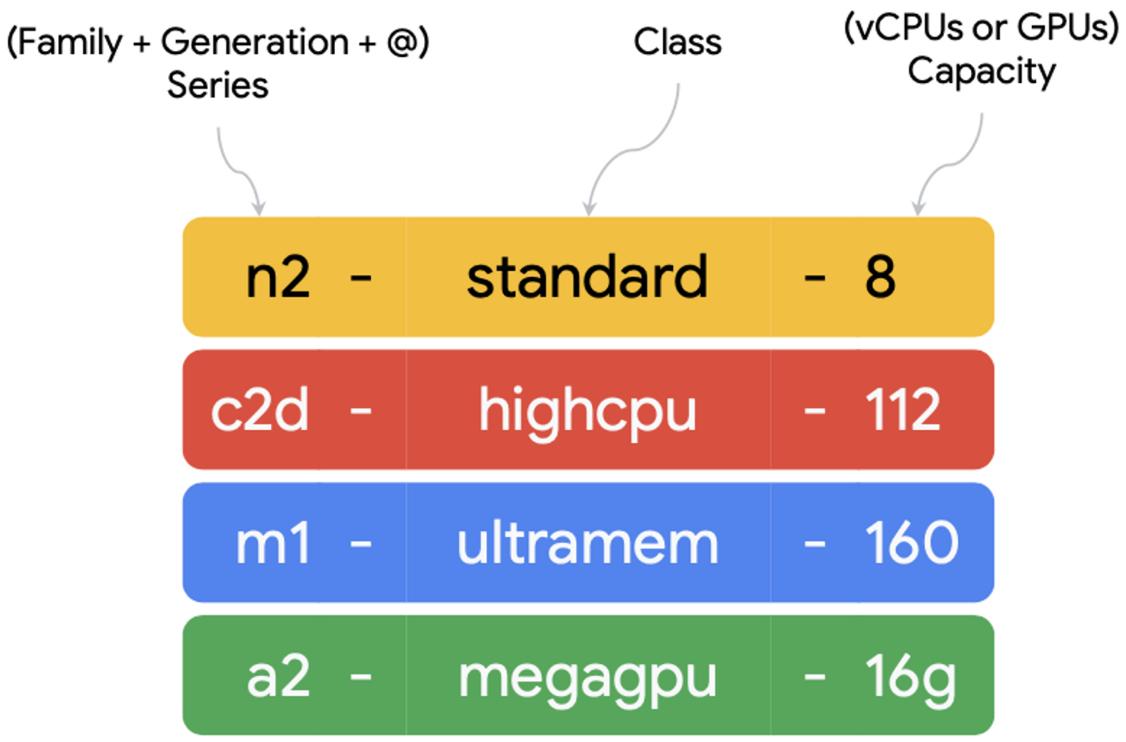
- VM Instacnes : E2
- Core share & Cpu bursting
- Low price(비용 효율), All region
- VM Instances : N2
- 가장 인기있는 인스턴스, 적절한 비용
- 최대 vCPU 128개, 메모리 864GB
- 커스텀VM (GCP 만의 기능)
- VM Instances : N2D
- N2 상위 버전, AMC EPYC CPU 기반
- 컨피덴션 VM 지원, 커스텀 VM 지원
- VM Instances : Tau T2D
- 멀티 스레드 지원 배제, 코어당 1개의 스레드로 고효율 연산 구현
- 업계 최고의 가격 대비 성능
- Scale-out(수평 확장) 최적화
- VM Instances : Tau T2A
- Taud T2D 상위 버전
- 특정 리전에서 사용 가능, 올해 4월 5일까지 무료로 사용 가능
- VM Instances : N1
- CPU 성능이 뒤쳐짐, 가격 대비 좋은 성능
- GPU와 TPU 운영
- VM Instances : C2
- 고성능 환경에서 주로 사용
- 최대 vCPU 60개, 240GB 메모리
- VM Instances : C2D
- 최대 vCPU 112개, 896GB
- 표준 및 높은 CPU와 높은 메모리 지원
- VM Instances : M1 & M2
- 1GB당 가장 낮은 메모리 비용 제공
- VM Instances : M3
- VM의 vCPU 시간당 및 메모리 1GB당 가격은 M1과 동일
- VM Instances : A2 Standard
- 최대 GPU 16개, vCPU 96개, 메모리 1.3TB 지원
- 최대 3TB 로컬 SSD, 100Gbps 고대역 네트워크 구성 지원
- VM Instances : A2 Ultra
- 최대 GPU 8개, vCPU 96개, 메모리 1.3TB 지원
- 최대 3TB 로컬 SSD, 100Gbps 고대역 네트워크 구성 지원
🌠 GCP만의 특별한 기능
- Custom VM
- Fit하게 필요한 만큼의 용량(Memory, CPU)을 선택할 수 있다.
- 확장 메모리 기능을 포함한다.
- 자동 확장 (Autoscaling)
- Predictive Autoscaling : 예측 자동 확장
- 컨피덴셜 VM : AMD가 제공하는 기술
- Memory에 있는 데이터까지 제공
- Spot VM : 일괄 작업과 내결함성 워크로드에 적합한 저비용의 컴퓨팅
- 월 1회 가격 변경 보장을 통한 가격 안정성 유지
🤑 가격 형성 구조
클라우드는 기본적으로 점유권에 따라서 가격이 결정된다.
-
가상 머신 인스턴스 : 가격 형성 구조
- 기본 구성: vCPU, Memory
- 추가 구성: Persistenct Disk, Local Disk, High Network
-
할인 프로그램
- CUD : 기간 동안 리소스 사용을 명시하면, 할인 적용되는 프로그램
- 클라우드 네이티브 : Spot
- 대규모 : CUD
🌐 네트워크
VPC(Virtual Private Cloud Networking)
- 각 VPC 네트워크는 Google Cloud 프로젝트에 포함한다.
- Google Cloud VPC는 전 세계적(Global, All Region)이다. 서브넷은 지역적(regional)이다.
- 글로벌 Load Balancing : 전 세계 단일 프런트엔드 제공한다.
- 사용자는 단일 글로벌 애니캐스트 IP 주소를 받는다
New Product
- C3 VM : 아직 Publiv Preview, 제한된 Region에서 사용 가능하다.
- 200Gbps, 저지연 네트워킹
- 인텔 4세대, 전세대 대비, 최대 10배 향상된 IOPS
Google Cloud의 스토리지 알아보기
발표자: 이보란, Customer Engineer, Infrastructure Modernization
🗄 Storage @ Google Cloud
구글 클라우드 내의 스토리지는 Colossus 기반으로 되어있다.
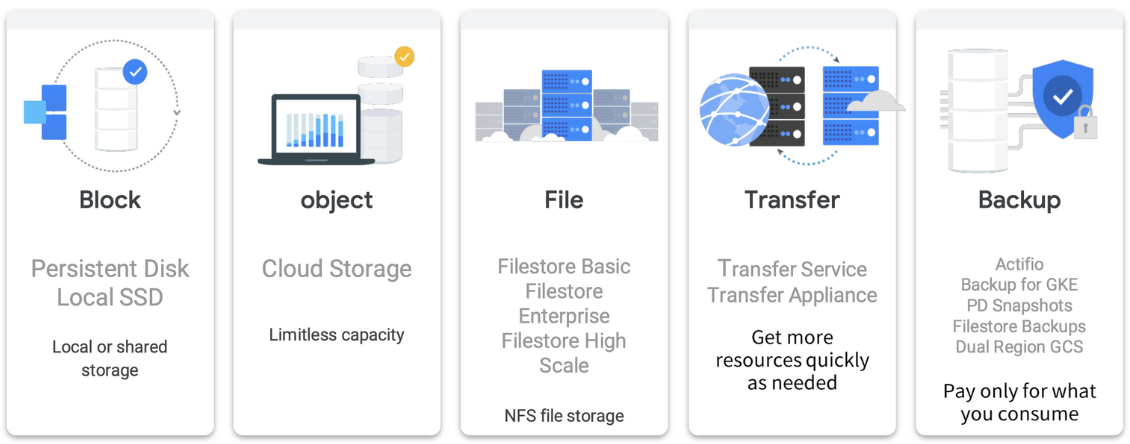
📦 Block : Persistent Disk
- Block 스토리지 : PD(Persistence Disk)
- 종류 : DB, SAP 워크로드, GCE, GKE, HPS
- 특징 : 다양한 성능과 가격, Auto Scaling, 데이터 손실을 방지하는 내구성
- 가용성 레벨에 따른 분류 : Loacl SSD < Persistend Disk < Reginal Persistent Disk
☁️ Obeject : Cloud Storage
-
Object 스토리지 : API 형태로 제공, Cloud Storage
-
종류 : 컨텐츠/이미지 전송, 데이터 분석, 백업 및 아카이브
-
특징: 사용 편의성, 안정성 비용 효율성(월 GB당 $0.0025), 아카이브 스토리지에 백업 하더라도 빠른 접근 속도(ms이내) 유지
-
활용 영역: 컨텐츠 저장 및 전달, 분석 및 머신러닝, 백업 및 아카이빙
-
기본 이해(용어)
-
객체 : 데이터의 기본 형태
-
버킷 : 객체를 담는 곳
-
Location : 버킷이 생성되는 곳
-
Storage Class : 객체에 적용되는 클래스, 가격과 영향
-
-
버킷 및 객체의 보호/보존 조치(Locking)
-
버킷 레벨에서의 관리
- Bucket Lock : Retention Policies, 기간 지정을 통한 정책 수정 불가능
-
객체 레벨에서의 관리
- Object holds(객체 보존 조치) : 개별 객체에 적용할 수 있는 보존 조치
-
Versioning: 객체 버전 관리: 버킷 레벨에서 Versioning을 활성화
-
-
데이터 암호화: 기본 키, 고객 관리 암호화 키, 고객 제공 암호화 키
-
데이터 접근 제어
- Uniform: 균등하게 접근 제어
- Fine-grained: 객체 레벨에서 상세한 접근 제어
- 공개 접근 방지: 버킷 레벨에서 정책을 통한 접근 방지
-
VPC Service Control: 데이터 내부 유출 방지
💾 File : Filestore
-
File Store: 계층 구조 형태의 완전 관리형 파일 서버
-
종류: SAP, Web 컨텐츠 전송, 미디어, 엔터테인먼트, 헬스케어
-
등급
- Basic : low performance, 1GB
- High scale : high read, max 100tb, 대용량에 최적화
- Enterprise : 고가용성이 중요한 워크로드
Google Kubernetes Engine 시작하기
발표자: 이기원, Customer Engineer
🚢 Container
소프트웨어의 배포는 Physical Server/Dedicated Server → Virtual Machine → Container → Serverless 순서로 발전했다.
-
Physical Server / Dedicated Server
- 애플리케이션은 Dedicated Server 위에 직접 배포/구축
- 애플리케이션 실행을 위해선 물리 하드웨어, OS, Dependecies(middleware..) 설치, 애플리케이션 배포 진행
- 배포와 관리를 위해서 많은 시간과 리소스가 소요되며 이식성과 확장성이 떨어지는 단점을 갖고 있다.
-
Virtual Machine
- 하이퍼바이저를 사용하여 동일 하드웨어에서 여러 서버 및 OS 실행
- 하드웨어의 가용성, 배포 시간, 이식성 향상
- VM을 사용하면 애플리케이션, 미들웨어, OS가 번들로 묶여야 하는점이 존재
-
Container
- 추상화 수준을 한 단계 높이고 OS를 가상화
- 이식성이 매우 뛰어나며, 환경에 제약 없이 실행
- OS를 탑재하지 않아 가볍고, 인프라 리소스를 애플리케이션에서 사용하는 리소스에 최적화 가능
- 시작 속도가 빨라 OS에서 프로세스를 시작하는 것과 유사
Docker를 활용하여 컨테이너 이미지를 생성고, 컨테이너 이미지를 저장소(Artifact Registry)에 저장한다.
🕸 Kubernetes
💡 Challenge
1. 수 많은 노드에 컨테이너들을 어느 노드에 어떻게 배포할 것인가요?
2. 특정 노드가 실패되면 어떻게 조치 할 것 인가요?
3. 특정 컨테이너가 실패되면 어떻게 조치 할 것인가요?
4. 배포된 애플리케이션들의 업그레이드는 어떻게 배포할 것인가요?
위와 같은 챌린지 상황에서, 컨테이너 워크로드를 관리 실행하기 위한 컨테이노 오케스트레이셔 서비스로 Kubernetes가 de facto standard가 되었다.
쿠버네티스 아키텍처
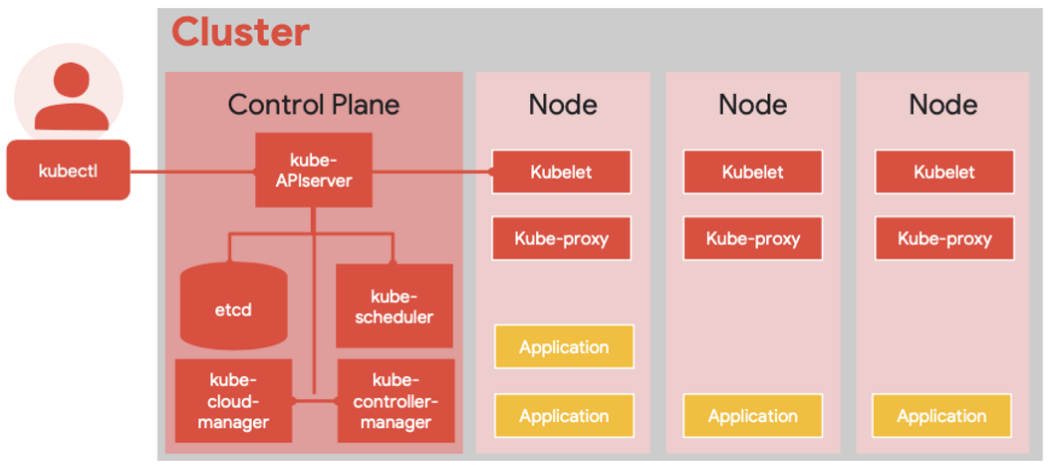
기능
-
스케줄링(Scheduling): 파드들이 실행될 노드를 결정
-
라이프사이클과 상태 유지(Lifcycle and health): 오류가 발생되더라도 컨테이너의 실행을 보장
-
스케일링(Scaling): 요청에 따라 컨테이너들을 확대/축소
-
로드 밸런싱(Load balancing): 컨테이너들에 트래픽을 분산
-
네이밍과 검색(Naming and discovery): 컨테이너들이 어디에서 동작되고 있는지 찾기
-
스토리지 볼륨(Storage volumes): 컨테이너에 데이터 저장소 제공
-
로깅과 모니터링(Logging and Monitoring): 컨테이너 운영을 위한 로깅과 모니터링
-
디버깅과 검사(Debuging and introspection): Enter of attach to containers
-
인증과 권한 부여(Identity and authorization): 컨테이너에 작업을 할 수 있는 사용자의 인증과 액세스 관리
🤖 GKE
Google은 Kubernetes는 내부의 클러스터 관리 시스템인 Brog로 부터 영감을 받아 개발했고, 2014년에 오픈 소스로 출시되었다. Google의 컨테너화된 워크로드를 15년 이상 실행한 경험을 기반으로 구축되었으며, 오픈소스 Kubernetes의 가장 큰 엔지니어링 기여자이다. Kubernetes는 GKE에서 빌드되고 배포되며, 모든 테스트는 GKE에서 실행된다.
GKE의 특징 및 기능
-
완전 관리형: 단순성과 자동화, 비즈니스에 집중
- GKE Autopilot를 갖춘 최초의 완전 관리형 Kubernetes 플랫폼
- 몇 분만에 운영 환경에서 실행 가능한 GKE 클러스터를 쉽게 생성 가능
- 자동 업그레이드와 노드 자동 복구, 백업/복구를 포함한 자동화된 클러스터 수명 주기 관리
- GKE에서 저동화된 CI/CD 환경 구축 가능
- 설치나 설정 없이 기본적으로 로깅과 모니터링 통합, 완전 관리형 Prometheus 서비스 지원
-
보안적 설계: 실제 환경에서 테스트 되고 강화된 보안 설정
- 보안 강화된 노드 (COS, Confidental Node, Shileded Node)
- 보안이 강화된 구성으로 클러스터를 보호하고 외부에서의 접근을 방지
- 사용자의 추가 작업 없이, 자동 보안 업그레이드
- 다른 Google Service와의 인증을 안전하고 쉽게 하기 위한 Workload Identity
- 보안 권장 사항을 제공하여 보안 상황을 개선하기 위한 Security Posture Dashboard
-
워크로드 최적화: 자동화된 워크로드의 확장
- 4방향 자동 확장
- (Only Autopilot) 실제 워크로드(Pod) 리소스에 대한 과금
- Spot VM 및 T2D VM과 같은 효율적인 컴퓨팅 옵션 지원
- (Only Standard) 다중 인스턴스 GPU, 시간 공유 GPU로 AI/ML 워크로드를 비용 효율적으로 확장
- 워크로드의 비용과 성능을 분석하기 위한 기본 제공 비용 최적화 통찰력(cost-optimization insights)
✈️ GKE Autopilot
GKE는 두 가지 운영 모드가 있다.
- GKE Standard Mode: 유연한 설정을 할 수 있는 관리형 쿠버네티스 서비스
- GKE Autopilot Mode: 최적화된 완전 관리현 쿠버네티스(Serverless)
- GKE의 권장 운영 모드
- Standard + 부가 기능(자동 업그레이드, 스케일링 등)
- cOS만 지원
특징
- K8s 전문가처럼 프로덕션 환경에 최적화된 설정
- 기본적으로 강력한 보안 설계
- Google is your SRE(Reduce day 2ops)
- 리소스 효율성 향상
광범위한 기능 지원
- (Deployment) Stateless 웹 애플리케이션
- (StatefulSet) 일반적인 데이터베이스
- (Job) 장 시간 동작되는 배치 잡
- (DaemonSet) 노드마다 동작하는 로깅/모니터링 에이전트
- (Spot Compute) 높은 MEM/CPU 집약 워크로드, ARM 아키텍처, 고 비용 효율적인 이프라
- GPU 사용이 필요한 AI/ML training and interface, video transcoding과 같은 애플리케이션
Wrap up
- 컨테이너 빌드, 컨테이너 이미지를 저장소(Artifact Registry)에 푸시한다.
- GKE 클러스터 생성(Standard / Autopilot)한다.
- GKE 클러스터에 워크로드 배포한다.
- GCP GUI
- K8S Obeject(Yaml)
- Kubustl (Command)
- GKE 클러스터 모니터링
- 배포된 워크로드의 로깅/모니터링
맺음말
Google Cloud OnBoard 라는 세미나의 제목을 통해 알 수 있듯이, Google Cloud에 대한 소개와 다양한 제품들에 대한 설명을 들었습니다. 개발자로서 중요하지 않은 내용이라고 생각할 수도 있지만, Google Cloud에 대한 관심과 구글 엔지니어들에 대한 막연한 궁금증으로 인해 참여했습니다.
연사 중에 나왔던 Planet Scale(행성 차원에서의 Auto-Scaling) 이라는 용어는 엔지니어로서 도전 의식을 심어주는 거 같습니다. 또한, Google Cloud Engineer의 기술에 대한 이해와 Product에 대한 자부심은 듣는 이로 하여금 신뢰감을 주며 프로다움을 느낄 수 있었습니다.
마지막 세션 주제였던 GKE 관련 발표를 들으며 IT 분야에 Silver Bullet은 없다지만, Kubernetes는 알면 알수록 Siver Bullet이라는 생각이 들었습니다. (오죽하면 De facto standard..)
요즘 유행하는 중꺾마(중요한 건 꺾이지 않는 마음)라는 말을 아시나요? 저는 그보다 공감이 됐던 건 개그맨 박명수님 말했던 중요한 건 꺾였는데도 그냥 하는 마음 입니다. 빠르게 변화하는 기술과 직장에서의 현실적인 업무 환경 사이에 때론 괴리감이 들기도 합니다. 따라서, 마음이 꺾일지라도 엔지니어로서 새로운 기술을 수용하고, 더 나은 아키텍처를 구상하며 지속적인 학습을 하는 것이 중요하다고 생각합니다.

출처
할명수
Google Cloud OnBoard