지난 포스팅까지 정의 수준에서 자료를 찾아봐서 그런지
인공지능이 도대체 무엇인가에 대한 의문이 계속 남아있었다.
여전히 부족한 자료조사이지만
자꾸만 벗어나려하는 요놈의 지식을 좀 가둬둘 필요가 있겠다 싶어 기록을 남긴다.
인공지능?
보편적으로 인공지능하면 생각나는게
스스로 판단하고 행동하는 시스템 정도로 생각할 수 있는데
이번 자료조사 과정을 통해서 데이터를 생성, 학습, 분석을 하는 과정을 거쳐 새로운 추론을 해내는 시스템 으로도 인공지능이 사용된다는 점을 짚고 넘어가고 싶다.
인공지능 뒀다가 어따 써
이번 자료조사를 하며 한가지 흥미로웠던 점은 빅데이터를 분석하는 즉
데이터 마이닝 분야에 인공지능이 활발하게 쓰인다는 것이다.
기본적으로 데이터를 분석할 때 주안점 중
데이터들의 분포가 어떤 의미를 가지는가?
데이터들 사이에 어떤 관계가 있을까?
현재까지 수집된 정보를 바탕으로 어떤 정보를 추론해낼 수 있을까
의 세가지는 인공지능의 머신러닝 분야의 학습목표와도 정확히 일치한다.
데이터마이닝? 머신러닝?
데이터 마이닝
대용량의 데이터, 특히 비정형의 데이터에서 특정한 패턴을 찾아 유의미한 정보를 찾아내는 것
비약일 수 있으나 마치 1년 365일 중 블프, 광군제, 연말특가 등등 우리는 은연중에 제품들의 가격이 떨어지는 기간(패턴)을 발견하는 것과 같은 이치이다.
다만 데이터 마이닝은 조금 더 복잡하고, 365일 처럼 체계적이지 않은(비정형의) 데이터들 사이에서도 어떤 가치있는 정보를 찾아내야할 뿐이다.
머신러닝
데이터 마이닝을 실현시키기 위해서 대용량의 데이터들 사이에서 유의미한 정보를 추론해낼 시스템(혹은 모델)이 필요한데, 이러한 시스템을 만들어가는 과정을 머신러닝 이라고 할 수 있다.
머신러닝의 방법에는 지도학습, 비지도학습, 강화학습 그리고 최근 MLP 를 활용한 딥러닝까지 크게 네가지로 나눌 수 있다.
이번 포스팅에서는 지도학습과 비지도학습에 대해서 다뤄보려고 한다.
SEMMA Process
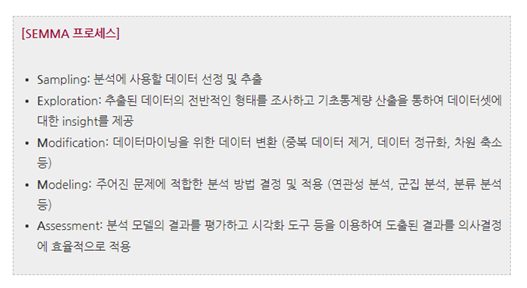
SEMMA Process는 데이터 마이닝의 핵심과정을 보여준다.
데이터의 수집(내/외장 데이터)이 선행된 후
위의 5단계를 거쳐 데이터를 분석하고 결과를 도출해낼 수 있는데,
Sampling : 대용량의 데이터에서 머신러닝에 필요한 데이터를 추출
Exploration : 추출된 데이터가 학습에 적합한지 분포를 살피는 것
Modification : 데이터 후처리에 가까운 과정(reduce)
Modeling : 실제 모델을 학습하고, 분석하는 과정
Assessment : 분석결과를 시각화, 결과를 바탕으로 한 모델평가 과정
지도학습/비지도학습 알고리즘

지도학습
입력과 출력에 대한 데이터가 있을 때 그 데이터를 사용하여 새로운 입력데이터에 대한 출력값을 예측하기 위함
출력값이라는 것은 부류가 될 수도 있고, 수치값이 될 수도 있다.
class 를 나누는건 classification(분류) 알고리즘을 통해,
수치값을 예측하는 것은 regression(회귀) 알고리즘을 통해 수행된다.
분류 : 새로운 데이터의 label을 결정하는 것
Decision Tree
입력데이터들에 대한 분류속성을 구하기 위하여 엔트로피를 계산하여 정보이득비가 가장 높은(엔트로피가 가장 낮은) 속성을 선택한다.
전체적인 트리가 완성되면 새로운 데이터에 대하여 트리를 탐색하여 만나는 단말노드가 해당 데이터의 출력값이 된다.

KNN(K Neareast Neighbor)
어떤 입력데이터와 그에 대한 출력데이터가 존재할 때 새로운 데이터가 들어오면 해당 데이터와 근접한 K개의 데이터를 살펴 다수의 부류에 속하는 것을 해당 데이터의 출력값으로 설정한다.

SVM(Support Vector Machine)
데이터를 분류할 수 있는 최적의 선형함수를 구하는 방법
최적의 선형함수는 결정경계와 선형함수 사이의 마진값이 가장 큰 것
데이터의 경계가 선형으로 분류가 안 될 경우도 생기는데, Kernel Trick 으로 2차원의 데이터를 3차원으로 확장시켜 초평면으로 분류하는 방법도 있다.
비지도 학습
입력에 대한 데이터만 존재할 때 데이터들의 분포 정보를 통해서 관계를 유추하고 특정한 패턴을 찾아내기 위함
비지도 학습의 종류 중 군집화, 밀도추정, 차원축소 세 가지가 존재한다.
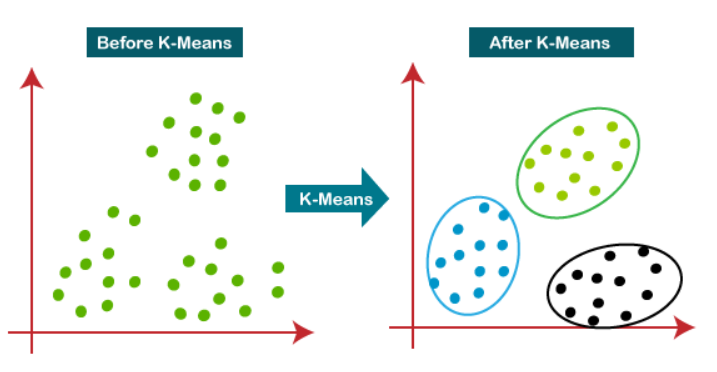
군집화
그래프 상에서 데이터들의 분포정보를 활용하여 데이터들을 여러 집합으로 나누는 방법
K Means Clustering
임의의 K 개의 점을 그래프상에 찍고 해당 점을 기준으로 가장 가까운 데이터들을 하나의 집합으로 묶는다. 다시 묶인 데이터들의 중심에 점을 찍고 앞의 과정을 반복하며 수렴되는 점들의 위치를 찾고 그 때의 데이터 집합을 하나의 연관성있는 데이터들로 판단을 하는 방법
밀도 추정
데이터의 입력값을 이용해 특정 모델에 학습시키는(모수적 밀도추정) 방법,
입력값 그 자체의 형태를 분석하는(비모수적 밀도추정) 방법이 존재한다.
모수적 밀도추정은 비교적 예측 가능한 데이터(학교 성적과 같은)에 대하여 적용이 가능하다. ex) 가우시안 함수
비모수적 밀도추정은 반대로 관찰하고자 하는 데이터의 분포 형태를 예측할 수 없을 때 시행한다. ex) 히스토그램, 커널 밀도추정
차원 축소
데이터들의 축이 많다면 데이터들간의 연결강도가 상당히 약해진다. 즉 데이터를 나누는 기준이 많아지니 하나의 집합으로 묶는데에 큰 어려움이 있다.
차원 축소는 위와같은 상황에서 하나의 축을 없애는데, 대상축을 기준으로 데이터들을 정사영 내렸을 때 분산이 가장 최대가 되는 축을 제거할 축으로 선택하는 방식이다.
마무리
데이터마이닝에서 머신러닝의 주안점은 가장 일반적인 상황에서 최적의 추론을 하는 분류기(classifier)를 도출해내는 것이며, 상황에 맞는 학습방법 선택과 효율적인 초기 학습 모델 선정과정은 필연적이다.
지도학습은 데이터의 label(혹은 value) 에 의해 모델의 형태가 결정되고,
비지도학습은 데이터의 분포 에 의해 결정된다.
참고자료
https://www.analyticsvidhya.com/blog/2021/04/k-means-clustering-simplified-in-python/
https://m.blog.naver.com/bestinall/221760380344
외 교내 학습자료
