
1. 계층형 아키텍처의 문제점은 무엇일까?
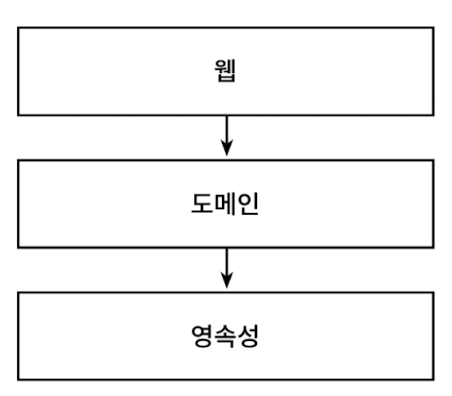
웹 계층: 요청을 받아 도메인 혹은 비즈니스 계층에 있는 서비스로 요청을 보낸다.
서비스: 필요한 비즈니스 로직 수행, 도메인 엔티티 상태 조회 또는 변경을 위해 영속성 계층의 컴포넌트 호출
계층형 아키텍처는 견고한 아키텍처 패턴이다. 계층을 잘 이해하고 구성한다면 웹 계층, 영속성 계층에 독립적으로 도메인 로직을 작성할 수 있다.
즉, 도메인 로직에 영향을 주지 않고 웹 계층, 영속성 계층에 사용된 기술을 변경할 수 있다. 기존 기능에 영향을 주지 않고 새로운 기능 추가가 가능하다.
하지만 계층형 아키텍처는 코드에 나쁜 습관들이 스며들기 쉽고 시간이 지날수록 소프트웨어를 점점 더 변경하기 어렵게 만든다.
계층형 아키텍처는 데이터베이스 주도 설계를 유도
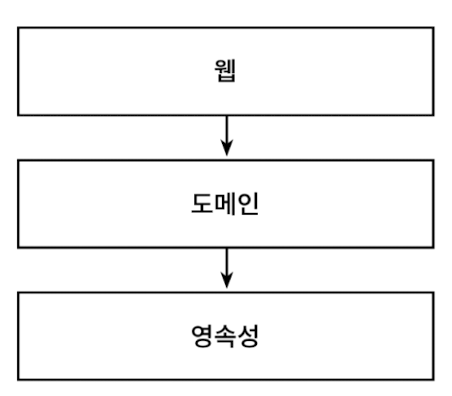
웹 계층 -> 도메인 계층 -> 영속성 계층
이런게 의존하기 때문에 자연스레 데이터베이스에 의존하게 된다. 모든 것이 영속성 계층을 토대로 만들어진다.
이런 방식이 왜 문제가 될까?
우리가 만드는 애플리케이션은 상태(state)가 아니라 행동(behavior)을 중심으로 모델링한다. 행동이 상태를 바꾸는 주체이기 때문에 행동이 비즈니스를 이끌어 간다.
우리는 왜 데이터베이스를 토대로 아키텍처를 만들까?
이는 계층형 아키텍처에 합리적인 방법이다. 의존성의 방향에 따라 자연스럽게 구현한 것이기 때문이다. 하지만 비즈니스 관점에서 전혀 맞지 않는 방법이다.
도메인 로직을 먼저 만들어야 로직을 제대로 이해했는지 확인할 수 있다. 도메인 로직 검증 후 이를 기반으로 영속성 계층과 웹 계층을 만들어야 한다.
데이터베이스 중심적인 아키텍쳐가 만들어지는 가장 큰 원인은 ORM 프레임워크를 사용하기 때문이다. ORM 프레임워크를 계층형 아키텍처와 결합하면 비즈니스 규칙을 영속성 관점과 섞고 싶은 유혹을 받기 쉽다.
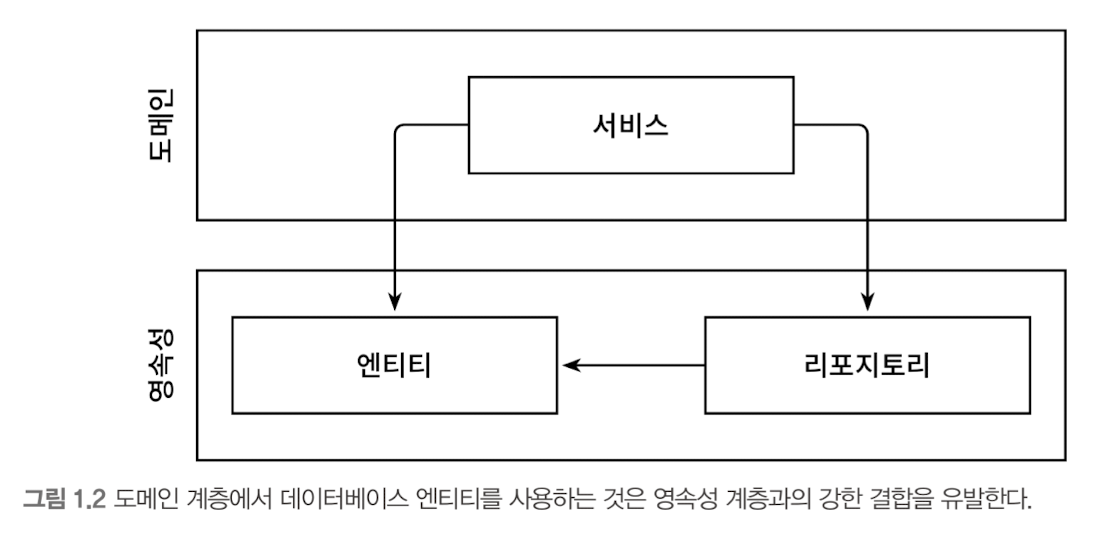
그림 1.2 와 같이 ORM에 관리되는 엔티티들은 일반적으로 영속성 계층에 둔다. 하지만 이렇게 되면 영속성 계층과 도메인 계층 사이에 강한 결합이 생긴다. 서비스는 영속성 모델을 비즈니스 모델처럼 사용하게 되고 이로 인해 도메인 로직뿐만 아니라 즉시로딩, 지연로딩, DB 트랜잭션, 캐시 플러시 등등 영속성 계층과 관련된 작업들을 해야만 한다.
영속성 코드가 도메인 코드에 녹아들어가서 둘 중 하나만 바꾸는 것이 어려워진다.
지름길을 택하기 쉬워진다.
계층형 아키텍처에서 전체적으로 적용되는 규칙은, 특정 계층에서는 같은 계층에 있는 컴포넌트나 아래 계층에만 접근 가능하다는 것이다.
따라서 상위 계층에 위치한 컴포넌트에 접근해야 한다면 간단하게 컴포넌트를 계층 아래로 내려버리면 된다. 그러면 접근 가능하게 되고 문제가 해결된다.
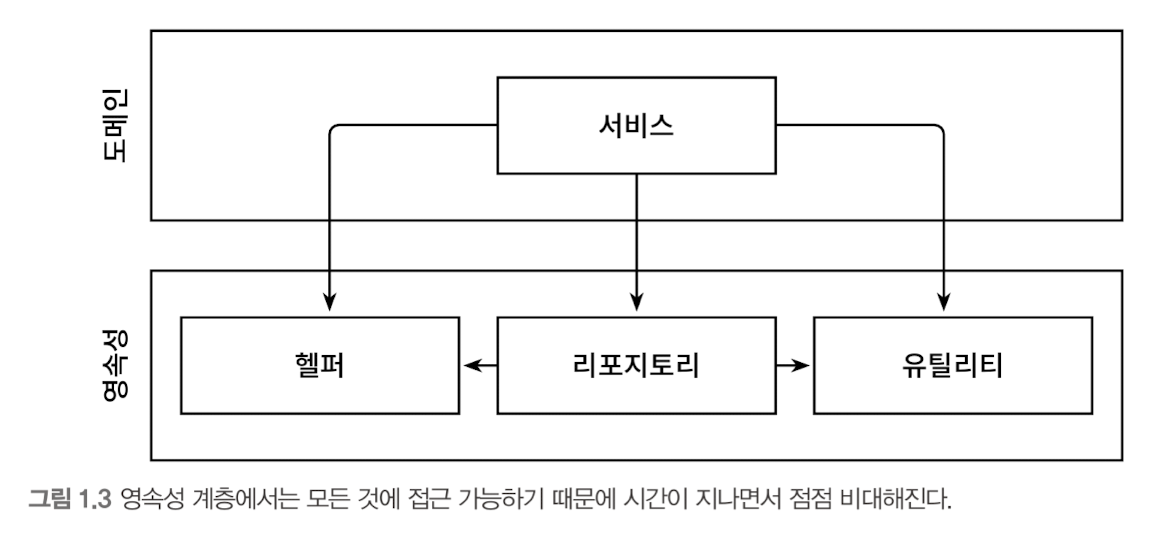
영속성 계층은 수년에 걸친 개발과 유지보수로 그림 1.3과 같이 될 확률이 높다. 그러니 아키텍처의 지름길 모드를 끄고 싶다면, 추가적인 아키텍처 규칙을 강제하지 않는 한 계층은 최선의 선택은 아니다. 여기서 강제란 해당 규칙이 깨졌을 때 빌드가 실패하도록 만드는 규칙을 의미한다.
테스트하기 어려워진다
계층형 아키텍처를 사용할 때 일반적으로 나타나는 변화의 형태는 계층을 건너뛰는 것이다. 엔티티의 필드를 단 하나만 조작하면 되는 경우에 웹 계층에서 바로 영속성 계층에 접근하면 도메인 계층을 건드릴 필요가 없지 않을까?
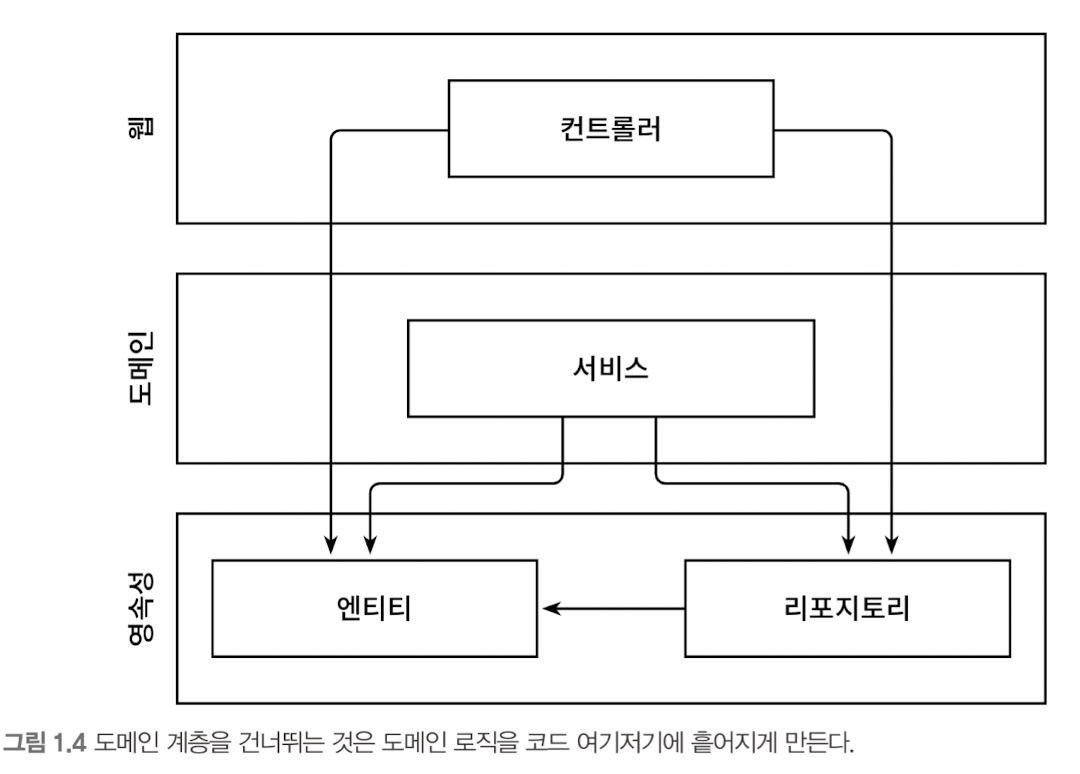
문제점 1. 단 하나의 필드를 조작하는 것에 불과하더라도 도메인 로직을 웹 계층에 구현하게 된다. 만약 앞으로 유스케이스가 확장된다면 더 많은 도메인 로직을 웹 계층에 추가해 애플리케이션 전반에 걸쳐 책임이 섞이고 핵심 도메인 로직들이 퍼져나갈 확률이 높다.
문제점 2. 웹 계층 테스트에서 도메인 계층뿐만 아니라 영속성 계층도 모킹(mocking) 해야 한다는 것이다. 이렇게 되면 단위 테스트의 복잡도가 올라간다. 그리고 테스트 설정이 복잡해지는 건 테스트를 작성하지 않는 방향으로 갈 수 있다. 왜냐하면 복잡한 설정을 할 시간이 없기 때문이다.
유스케이스를 숨긴다
개발자들은 새로운 유스케이스 구현에 새롭게 코드를 짜는 걸 선호한다. 그러나 실제로는 새로운 코드를 짜는 데 시간을 쓰기보다는 기존 코드를 바꾸는 데 더 많은 시간을 쓴다. 이것은 레거시 프로젝트 뿐만 아니라, 신규 프로젝트도 마찬가지다.
기능을 추가, 변경할 적절한 위치를 찾는 일이 빈번하기 때문에 아키텍처는 코드를 빠르게 탐색하는 데 도움이 돼야 한다.
앞서 논의했듯이 계층형 아키텍처에서는 도메인 로직이 여러 계층에 걸쳐 흩어지기 쉽다. 유스케이스가 간단하여 도메인 계층을 생략한다면 도메인 로직이 웹 계층에 존재할 수 있고, 도메인 계층과 영속성 계층 모두 접근하도록 특정 컴포넌트를 아래로 내렸다면 영속성 계층에 존재할 수 있다. 이럴 경우 새로운 기능을 추가할 적당할 위치를 찾는 일은 이미 어려워진 상태다.
계층형 아키텍처는 도메인 서비스의 '너비’에 관한 규칙을 강제하지 않는다. 그렇기 때문에 시간이 지나면 그림 1.5처럼 여러 개의 유스케이스를 담당하는 아주 넓은 서비스가 만들어지기도 한다.
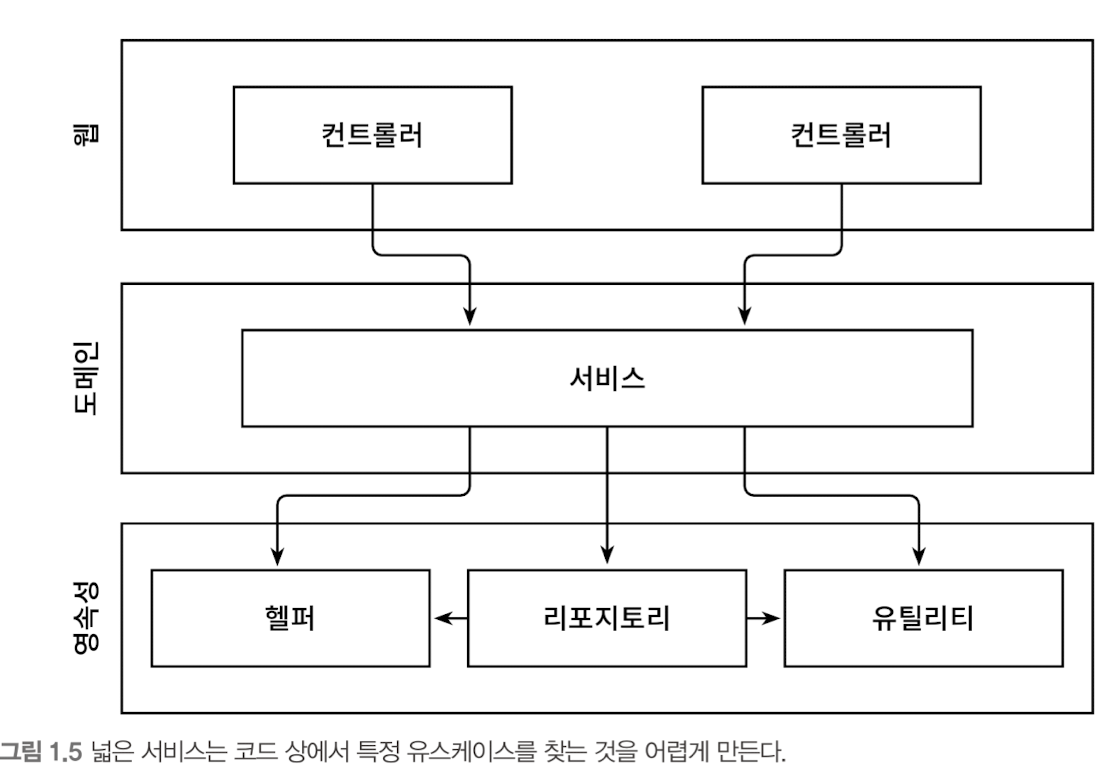
넓은 서비스는 영속성 계층에 많은 의존성을 갖게 되고, 다시 웹 레이어의 많은 컴포넌트가 이 서비스에 의존하게 된다. 그럼 서비스를 테스트하기 어려워지고 작업해야 할 유스케이스를 책임지는 서비스를 찾기도 어려워진다.
극한으로 좁은 도메인 서비스가 유스케이스 1개만 담당하게 한다면 UserService에서 사용자 등록 코드를 찾는 대신 RegisterUserService를 바로 열어서 작업할 수 있게 될 것이다.
동시 작업이 어려워진다
코드에 넓은 서비스가 있다면 서로 다른 기능을 동시에 작업하기가 더욱 어렵다. 서로 다른 유스케이스에 대한 작업을 하게 되면 같은 서비스를 동시에 편집하는 상황이 발생하고, 이는 병합 충돌(merge conflict)과 잠재적으로 이전 코드로 되돌려야 하는 문제를 야기하기 때문이다.
