
2. 의존성 역전하기
이번 장에선 대안에 대해 이야기한다. 먼저 단일 책임 원칙(Single Responsibility Principle, SRP)과 의존성 역전 원칙(Dependency Inversion Principle, DIP)에 대해 이야기하는 것으로 시작하자.
단일 책임 원칙
이 원칙의 일반적인 해석은 다음과 같다.
하나의 컴포넌트는 오로지 한 가지 일만 해야 하고, 그것을 올바르게 수행해야 한다.
이는 좋은 조언이지만 단일 책임 원칙의 실제 의도는 아니다.
단일 책임 원칙의 실제 정의는 다음과 같다.
컴포넌트를 변경하는 이유는 오직 하나뿐이어야 한다.
만약 컴포넌트를 변경할 이유가 오로지 한 가지라면 컴포넌트는 딱 한 가지 일만 하게 된다. 하지만 이보다 더 중요한 것은 변경할 이유가 오직 한 가지라는 그 자체다.
이것이 아키텍처에서 어떤 의미를 띄나면 우리가 어떤 다른 이유로 소프트웨어를 변경하더라도 이 컴포넌트에 대해서 전혀 신경 쓸 필요가 없다. 소프트웨어가 변경되더라도 여전히 우리가 기대한 대로 동작할 것이기 때문이다.
변경할 이유라는 것은 컴포넌트 간의 의존성을 통해 쉽게 전파된다. 그림 2.1을 보자.
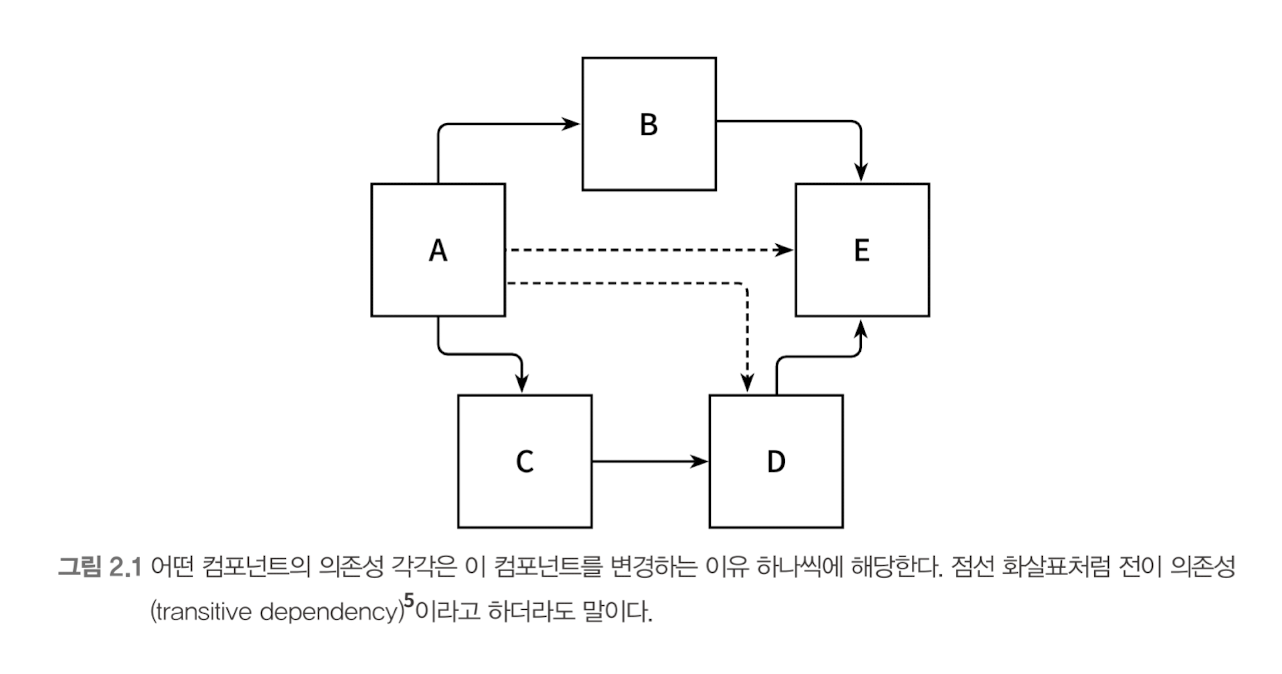
그림 2.1에서 컴포넌트 A는 다른 여러 컴포넌트에 의존하는(직접적이든 전이된 것이든) 반면 컴포넌트 E는 의존하는 것이 전혀 없다.
컴포넌트 E를 변경할 유일한 이유는 새로운 요구사항에 의해 E의 기능을 바꿔야 할 때뿐이다. 반면 컴포넌트 A의 경우에는 모든 컴포넌트를 의존하고 있기 때문에 다른 어떤 컴포넌트가 바뀐다면 같이 바뀌어야 한다.
의존성 역전 원칙
계층형 아키텍처에서 계층 간 의존성은 항상 다음 계층인 아래 방향을 가리킨다. 단일 책임 원칙을 고수준에서 적용할 때 상위 계층들이 하위 계층들에 비해 변경할 이유가 더 많다는 것을 알 수 있다.
그러므로 영속성 계층에 대한 도메인 계층의 의존성 때문에 영속성 계층을 변경할 때마다 잠재적으로 도메인 계층도 변경해야 한다. 그러나 도메인 코드는 애플리케이션에서 가장 중요한 코드다. 영속성 코드가 바뀐다고 해서 도메인 코드까지 바꾸고 싶지 않다.
그럼 이 의존성을 어떻게 제거할 수 있을까?
의존성 역전 원칙(Dependency Inversion Princilple, DIP)이 답을 알려준다.
코드상의 어떤 의존성이든 그 방향을 바꿀 수(역전시킬 수) 있다.
사실 의존성의 양쪽 코드를 모두 제어할 수 있을 때만 의존성을 역전시킬 수 있다. 만약 서드파티 라이브러리에 의존성이 있다면 해당 라이브러리를 제거할 수 없기 때문에 이 의존성을 역전시킬 수 없다.
의존성 역전은 어떻게 동작할까? 도메인 코드와 영속성 코드 간의 의존성을 역전시켜서 영속성 코드가 도메인 코드에 의존하고, 도메인 코드를 '변경할 이유’의 개수를 줄여보자.
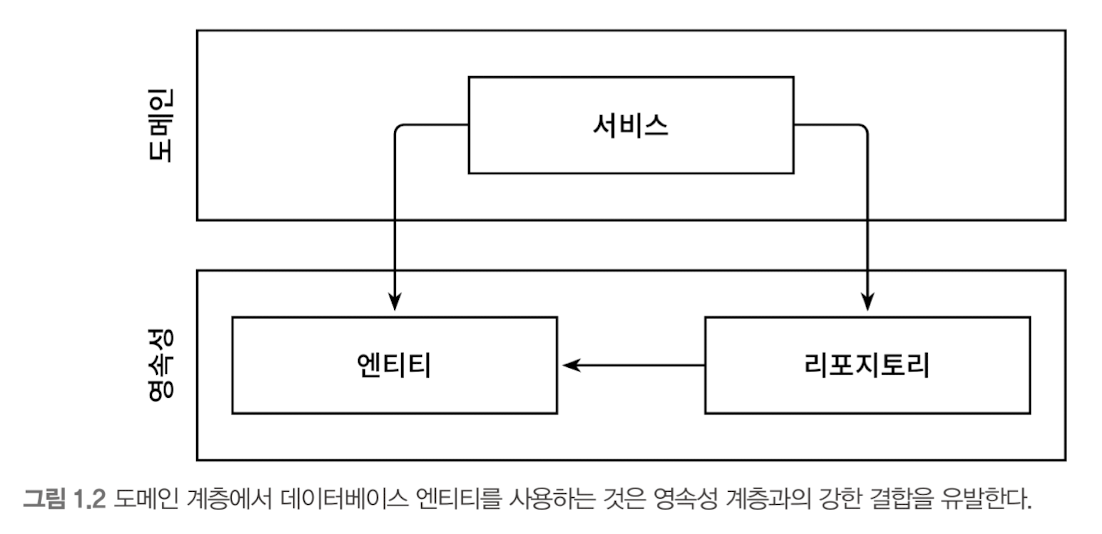
1장의 그림 1.2에 나왔던 구조부터 시작해보자. 도메인 계층에 영속성 계층의 엔티티와 레포지토리와 상호작용하는 서비스가 하나 있다.
엔티티는 도메인 객체를 표현하고 도메인 코드는 이 엔티티들의 상태를 변경하는 일을 중심으로 하기 때문에 먼저 엔티티를 도메인 계층으로 올린다.
그러나 이제는 영속성 계층의 리포지토리가 도메인 계층에 있는 엔티티에 의존하기 때문에 두 계층 사이에 순환 의존성(circular dependency)이 생긴다. 이 부분이 바로 DIP를 적용하는 부분이다. 도메인 계층에 리포지토리에 대한 인터페이스를 만들고, 실제 리포지토리는 영속성 계층에서 구현하게 하는 것이다.
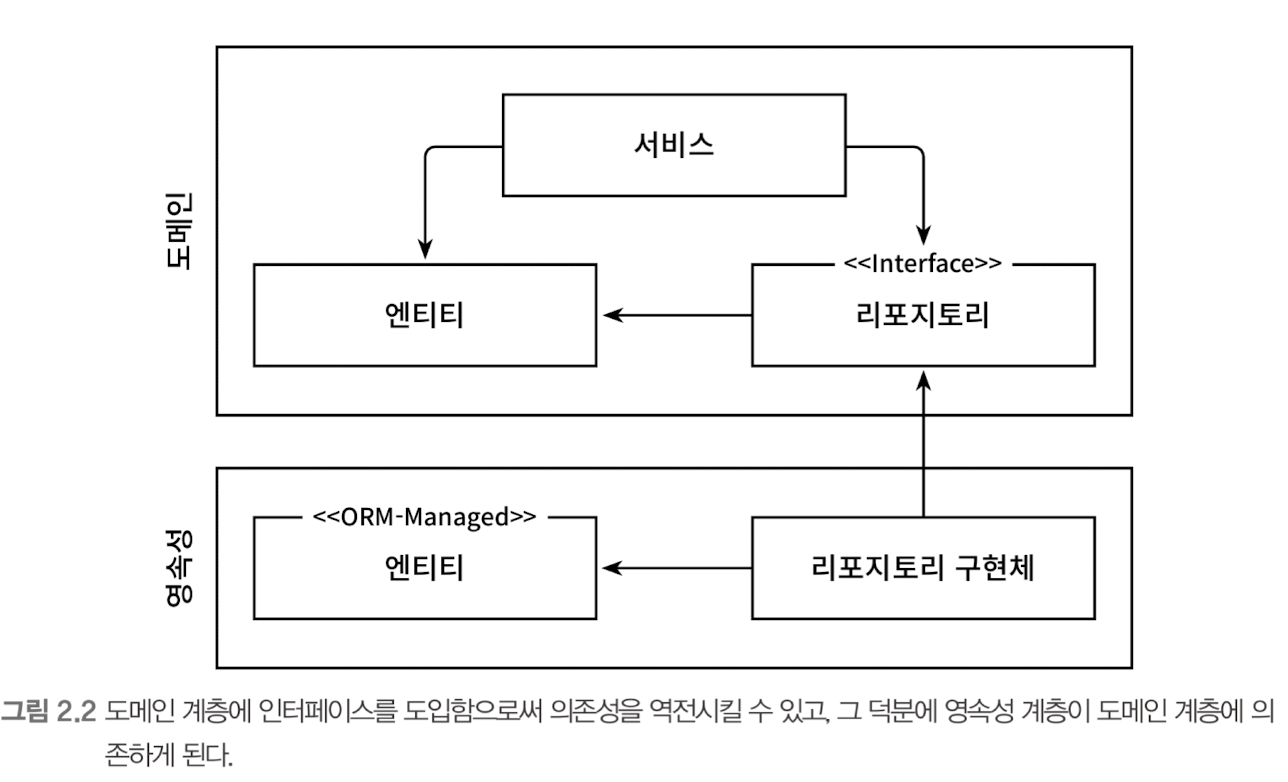
이 묘수로 영속성 코드에 있는 숨막히는 의존성으로부터 도메인 로직을 해방시켰다. 이것이 바로 다음 절에 살펴볼 두 가지 아키텍처 스타일의 핵심 기능이다.
클린 아키텍처
'클린 아키텍처’라는 책에서는 설계가 비즈니스 규칙의 테스트를 용이하게 하고, 비즈니스 규칙은 프레임워크, 데이터베이스, UI 기술, 그 밖의 외부 애플리케이션이나 인터페이스로부터 독립적일 수 있다고 이야기했다.
이는 도메인 코드가 바깥으로 향하는 어떤 의존성도 없어야 함을 의미한다. 대신 의존성 역전 원칙의 도움으로 모든 의존성이 도메인 코드를 향하고 있다.
그림 2.3은 클린 아키텍처가 어떻게 생겼는지 추상적으로 보여준다.
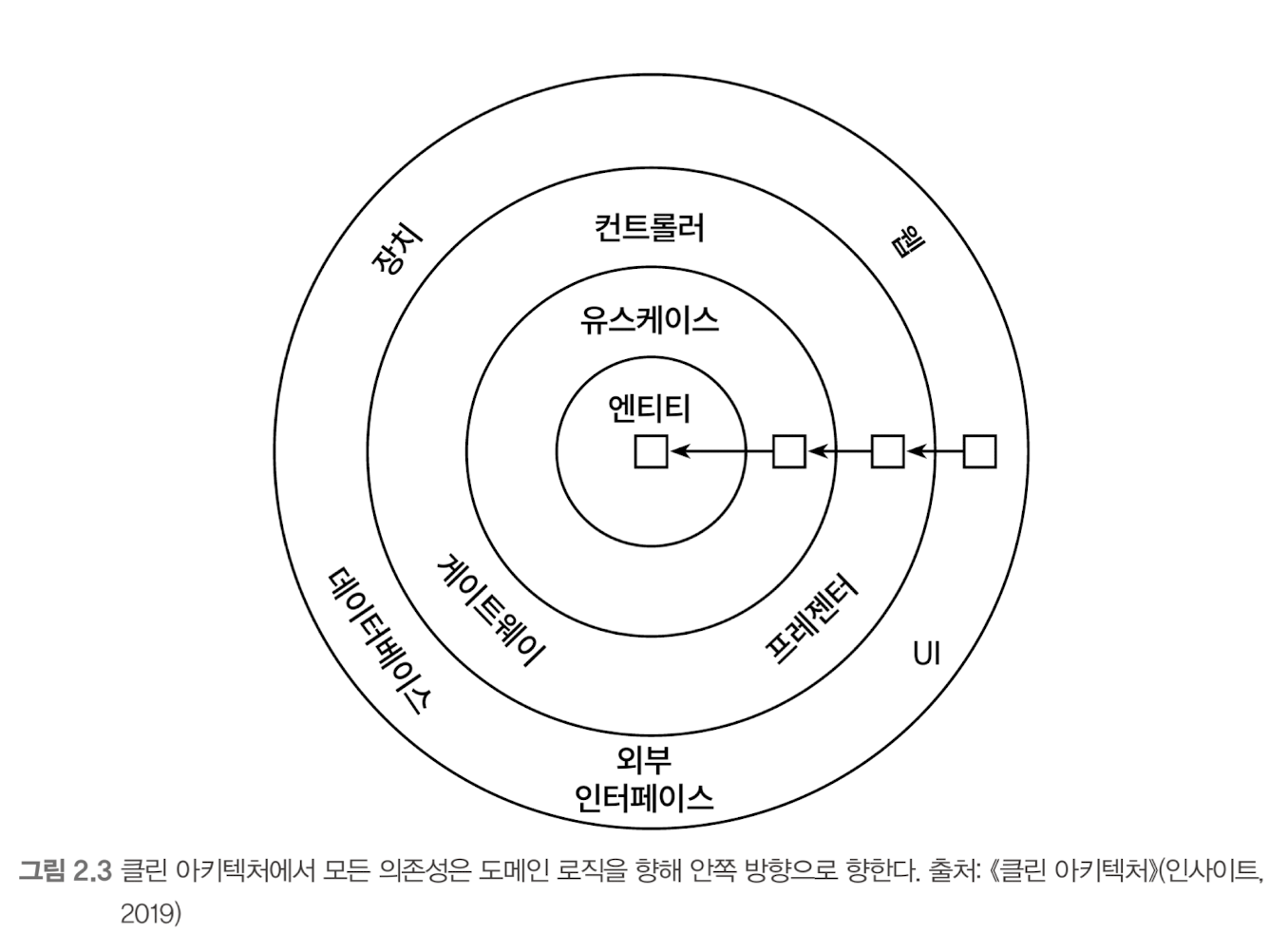
이 아키텍처에서 계층들은 동심원으로 둘러싸여 있다. 이 아키텍처에서 가장 주요한 규칙은 의존성 규칙으로, 계층 간의 모든 의존성이 안쪽으로 향해야 한다는 것이다.
이 아키텍처의 코어(core)에는 주변 유스케이스에서 접근하는 도메인 엔티티들이 있다. 유스케이스는 앞에서 서비스라고 불렀던 것들인데, 단일 책임(즉, 변경할 단 한가지의 이유)을 갖기 위해 조금 더 세분화돼 있다. 이를 통해 이전에 이야기했던 넓은 서비스 문제를 피할 수 있다.
이 코어 주변으로 비즈니스 규칙을 지원하는 애플리케이션의 다른 모든 컴포넌트들을 확인할 수 있다. 여기서 '지원’은 영속성을 제공하거나 UI를 제공하는 것 등을 의미한다. 또한 바깥쪽 계층들은 다른 서드파티 컴포넌트에 어댑터를 제공할 수 있다.
도메인 코드에서는 어떤 영속성 프레임워크나 UI 프레임워크가 사용되는지 알 수 없기 때문에 특정 프레임워크에 특화된 코드를 가질 수 없고 비즈니스 규칙에 집중할 수 있다. 그래서 도메인 코드를 자유롭게 모델링할 수 있다.
하지만 클린 아키텍처에는 대가가 따른다. 도메인 계층이 영속성이나 UI 같은 외부 계층과 철저하게 분리돼야 하므로 애플리케이션의 엔티티에 대한 모델을 각 계층에서 유지보수해야 한다.
가령 영속성 계층에서 ORM(object-relational mapping, 객체-관계 매핑) 프레임워크를 사용한다고 해보자. 일반적으로 ORM 프레임워크는 엔티티 클래스를 필요로 한다. 도메인 계층은 영속성 계층을 모르기 때문에 도메인 계층에서 사용한 엔티티 클래스를 영속성 계층에서 함께 사용할 수 없고 두 계층에서 각각 엔티티를 만들어야 한다. 즉, 도메인 계층과 영속성 계층이 데이터를 주고 받을 때, 두 엔티티를 서로 변환해야 한다는 뜻이다. 이는 도메인 계층과 다른 계층 사이들에서도 마찬가지다.
하지만 이것은 바람직한 일이다. 이것은 바로 도메인 코드를 프레임워크에 특화된 문제로부터 해방시키고자 했던, 결합이 제거된 상태다. 가령 Java Persistence API(자바 세계의 표준 ORM-API)에서는 ORM이 관리하는 엔티티에 인자가 없는 기본 생성자를 추가하도록 강제한다. 이것이 바로 도메인 모델에는 포함해서는 안 될 프레임워크에 특화된 결합의 예다. 8장에서는 도메인 계층과 영속성 계층의 결합을 그대로 수용하는 '매핑하지 않기' 전략을 비롯한 여러 매핑 전략에 대해 살펴보겠다.
클린 아키텍처는 다소 추상적이기 때문에 클린 아키텍처의 원칙들을 조금 더 구체적으로 만들어주는 '육각형 아키텍처’에 대해 살펴보자.
육각형 아키텍처(헥사고날 아키텍처)
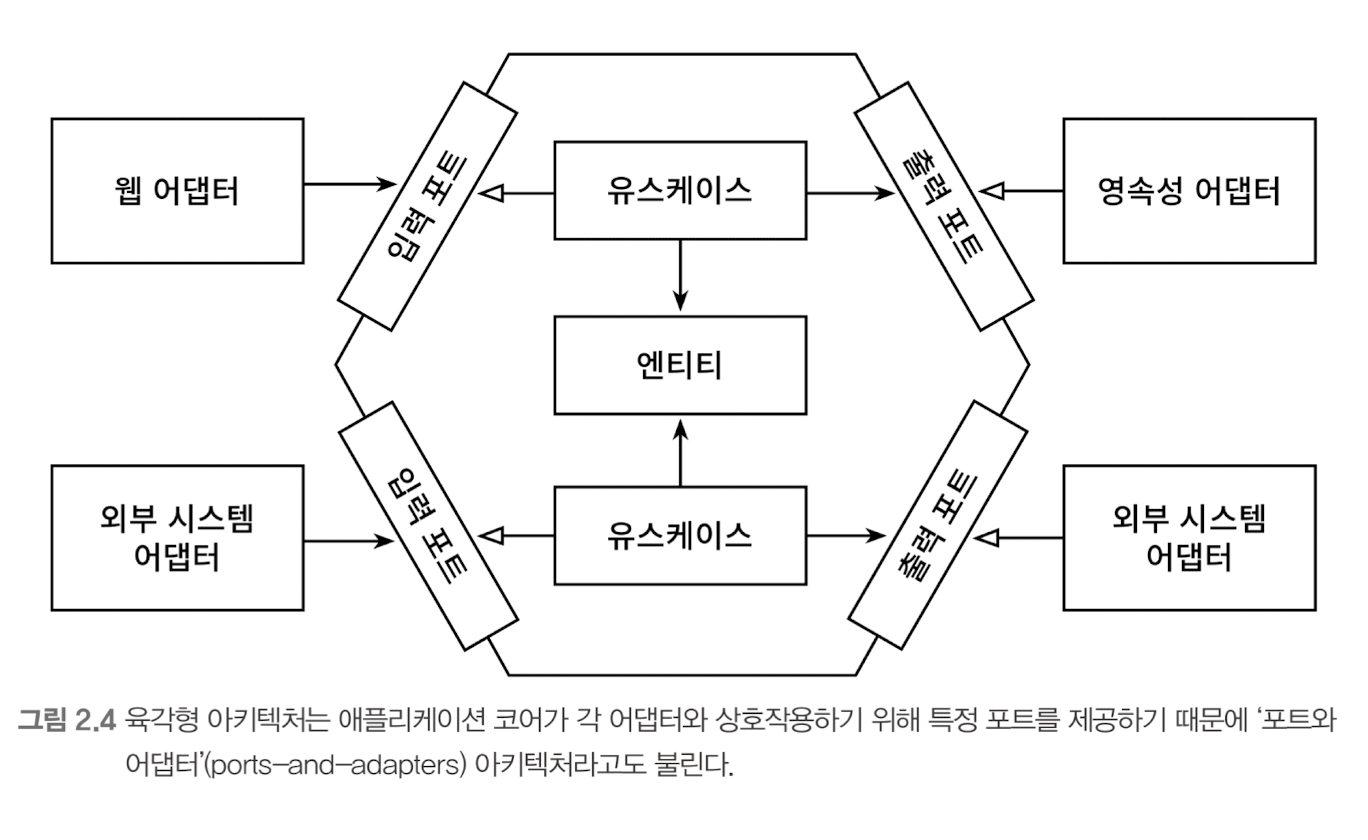
'육각형 아키텍처’라는 용어는 알리스테어 콕번이 만든 용어로, 꽤 오랫동안 사용돼 왔다. 애플리케이션 코어가 육각형으로 표현되어 이 아키텍처의 이름이 됐다.
육각형 안에는 도메인 엔티티와 이와 상호작용하는 유스케이스가 있다. 육각형에서 외부로 향하는 의존성이 없기 때문에 클린 아키텍처에서 제시한 의존성 규칙이 그대로 적용된다는 점을 주목하자. 대신 모든 의존성은 코어를 향한다.
왼쪽에 있는 어댑터들은 (애플리케이션 코어를 호출하기 때문에) 애플리케이션을 주도하는 어댑터들이다. 반면 오른쪽에 있는 어댑터들은 (애플리케이션 코어에 의해 호출되기 때문에) 애플리케이션에 의해 주도되는 어댑터들이다.
애플리케이션 코어와 어댑터들 간의 통신이 가능하려면 애플리케이션 코어가 각각의 포트를 제공해야 한다. 주도하는 어댑터(driving adapter)에게는 그러한 포트가 코어에 있는 유스케이스 클래스 중 하나에 의해 구현되고 어댑터에 의해 호출되는 인터페이스가 될 것이고, 주도되는 어댑터(driven adapter)에게는 그러한 포트가 어댑터에 의해 구현되고 코어에 의해 호출되는 인터페이스가 될 것이다.
이러한 핵심 개념으로 인해 이 아키텍처 스타일은 '포트와 어댑터(ports-and-adapters)' 아키텍처로도 알려져 있다. 클린 아키텍처처럼 육각형 아키텍처도 계층으로 구성할 수 있다.
유지보수 가능한 소프트웨어를 만드는 데 어떻게 도움이 될까?
클린 아키텍처, 육각형 아키텍처, 혹은 포트와 어댑터 아키텍처 중 무엇으로 불리든 의존성을 역전시켜 도메인 코드가 다른 바깥쪽 코드에 의존하지 않게 함으로써 영속성과 UI에 특화된 모든 문제로부터 도메인 로직의 결합을 제거하고 코드를 변경할 이유의 수를 줄일 수 있다. 그리고 변경할 이유가 적을수록 유지보수성은 더 좋아진다.
또한 도메인 코드는 비즈니스 문제에 맞도록 자유롭게 모델링될 수 있고, 영속성 코드와 UI 코드도 영속성 문제와 UI 문제에 맞게 자유롭게 모델링될 수 있다.
