오늘 리뷰할 논문은 Vision-and-Language BERT, ViLBERT 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [Multimodal #1] ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks (NeurIPS, 2019)
- ViLBERT & LXMERT
Summary
논문은 image content와 natrual language의 task-agnostic joint representations을 학습하는 ViLBERT를 소개한다. BERT 모델을 multi-modal two-stream model로 확장하며 visual input과 textual input을 co-attentional transformer layers을 통해 상호작용하는 별개의 streams에 처리한다. 크고 자동으로 수집된 Conceptual Captions dataset에 두 proxy tasks를 사용해 pretrain하며 base architecture에 작은 수정만 가해 여러 유명한 vision-and-language tasks에 transfer한다. 기존의 task-specific models에 비해 상당한 향상이 있었고 모든 네 tasks에서 SOTA를 달성한다. 논문의 연구는 vision과 language 사이 grounding을 오직 task training의 일부로써 학습하는 것을 넘어 visual grounding을 pretrainable, transferable 능력으로 다루는 것으로 지평을 넓힌다.
introduction 부분을 요약하면 기존의 vision-and-language tasks은 pretrain-then-transfer 학습 방식을 쓰는데, vision과 language를 각각 따로 pretrain한 후 transfer할 때 task training의 일부로 visual grounding(=vision과 language를 align하는 것)을 학습한다는 것이다. 그런데 이런 방식은 paired visiolinguistic data가 제한적이거나 편향되어 있을 때 일반화를 잘 못한다. 예를 들어 아무리 개의 종류에 대한 visual representation을 완벽하게 학습했더라도 beagle이나 shepherd 같은 적절한 단어를 모른다면 downstream vision-and-language model은 둘을 연관시키는 데 실패할 것이다. 따라서 논문은 visual grounding을 위한 common model에 관심이 있으며 이런 연관성을 학습하고자 한다. 즉, visual grounding을 pretrain하고자 한다.
이 joint visual-linguistic representations을 배우기 위해 모델이 이른바 'proxy' tasks를 수행하도록 학습시킴으로써 large, unlabelled data sources에서 풍부한 semantic, structural information을 포착한 self-supervised learning의 최근 성공에 주목한다. 이 proxy tasks는 자동으로 supervised tasks을 생성하도록 data 내의 structure을 leverage한다.
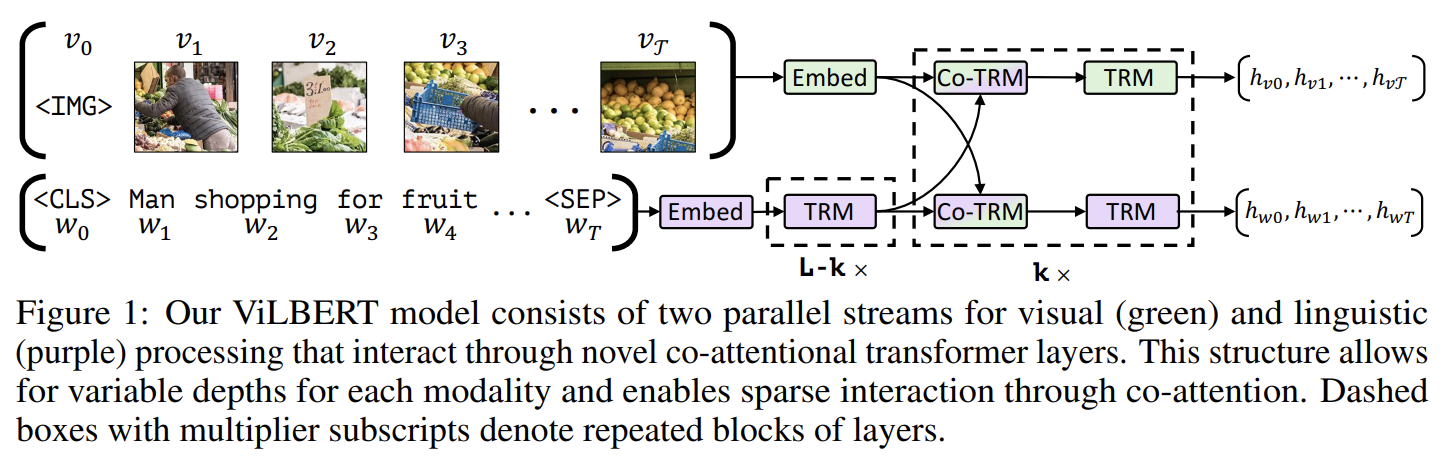
ViLBERT의 핵심적인 혁신은 co-attentional transformer layers을 통해 소통하는, vision과 language processing을 위한 별개의 streams을 도입한 것이다. 이 구조는 각 modality의 서로 다른 processing needs를 수용할 수 있고 다양한 representation depths에서 modalities 사이 상호작용을 제공한다. 실험을 통해 이 구조가 single-stream unified model보다 뛰어남을 보인다.
BERT 논문의 training tasks와 유사하게 ViLBERT를 두 proxy tasks에 학습시킨다. unmasked inputs이 주어졌을 때 masked words와 image regions의 semantic을 예측하는 것과 image와 text segment가 대응되는지 예측하는 것이다. pretrained model을 네 개의 유명한 vision-and-language tasks인 visual question answering, visual commonsense reasoning, referring expressions, caption-based image retrieval에 적용하여 모두 SOTA를 달성한다. ViLBERT 구조는 수정이 간단해서 여러 vision-and-language tasks에 visual grounding을 위한 common foundation의 역할을 한다.
(BERT 설명 생략)
BERT에 최소한의 수정만 가하는 한 가지 간단한 방법은 단순히 clustering을 통해 visual inputs의 space를 discretize해서 이 visual 'tokens'을 text input처럼 다루어 pretrained BERT model에서 시작하는 것이다(=VideoBERT). 그러나 이 architecture은 여러 단점이 있다. 첫째로 initial clustering이 discretization error을 초래해 중요한 visual details을 잃을 수 있다. 둘째로 두 modalities로부터 온 inputs을 동일하게 취급하고 둘이 (내재적인 복잡도나 그들의 input representations의 abstraction의 initial level 때문에) 서로 다른 수준의 processing이 필요하리란 사실을 무시한다. 예를 들어 image regions는 문장 내 단어들보다 약한 relation을 가지며, 보통 visual features은 그 자체로 이미 very deep network의 output이다. 마지막으로 pretained weights가 large set of additional visual ‘tokens’을 수용하도록 강요하는 것은 학습된 BERT language model을 손상시킬 수 있다.
대신 논문은 two-stream architecture을 개발해 두 modality를 따로 modeling하고 그 다음 small set of attention-based interactions을 통해 둘을 융합한다. 이 방식은 각 modality에 대해 가변적인 network depth를 허용하며 다양한 깊이에서 cross-modal connections을 가능하게 한다.
Fig 1에서 볼 수 있듯 ViLBERT는 image regions와 text segments 위에 작동하는 두 parallel BERT-style models로 구성된다. 각 stream은 transformer blocks (TRM)와 (modalities 간 정보 교환을 허용하기 위해 도입한) novel co-attentional transformer layers (Co-TRM)의 연속(series)이다. set of region features 로 표현되는 image I와 text input 가 주어졌을 때, ViLBERT는 final representations 와 을 output한다. 두 streams 간 정보 교환이 특정 layers 사이에서만 있도록 제한되며 text stream이 visual features와 상호작용하기 전에 상당히 더 많은 processing을 가진다는 것에 주의하라. 이는 chosen visual features이 이미 상당히 high-level이며 문장 내 단어에 비하면 limited context-aggregation을 요구한다는 직관에 부합한다.
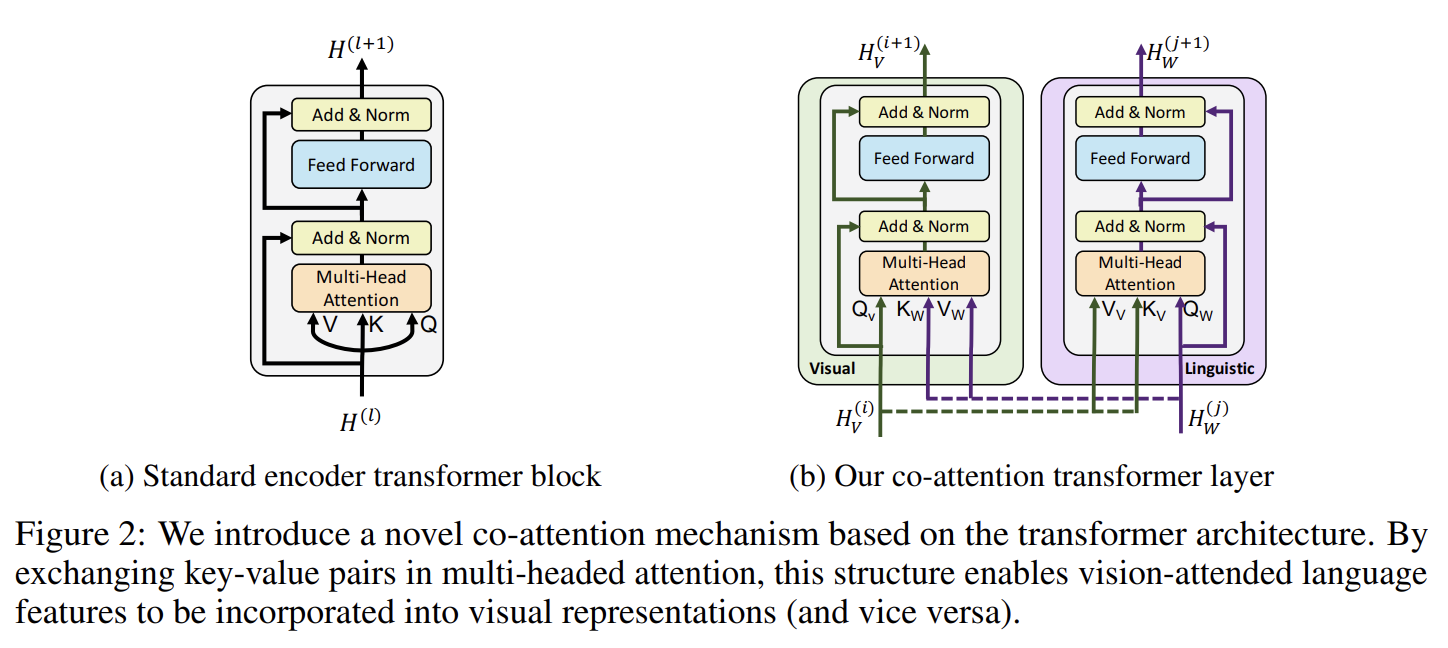
Fig 2b의 Co-Attentional Transformer Layers을 도입한다. intermediate visual/linguistic representations 가 주어졌을 떄 모듈은 일반적인 transformer block처럼 query, key, value matrices을 계산한다. 그러나 각 modality에서 온 keys와 values는 다른 modality의 multi-headed attention block에 input으로 전달된다. 결과적으로 attention block은 각 modality에 대해 상대방에 condition된 attention-pooled features을 생성한다. 사실상 visual stream에선 image-conditioned language attention을 하고 linguistic stream에선 language-conditioned image attention을 수행하는 것이다. 후자는 vision-and-language models에서 발견되는 common attention mechanism을 모방한다. 나머지 transformer block은 (initial representations에 residual add를 포함해) 이전과 같이 진행되며(proceed) multimodal feature을 만든다.
pre-trained object detection network에서 bounding boxes와 그들의 visual features을 추출하는 것으로 image region features을 생성한다. text 내의 단어와 달리 image regions은 natural ordering가 부족하다. 대신 spatial location을 encode하는데, region position (normalized top-left & bottom-right coordinates)과 fraction of image area covered에서 5-d vector을 구성한다. 이는 visual feature의 dimension에 맞게 project된 후 visual feature에 더해진다.
image region sequence의 시작부분을 전체 이미지를 대표하는 special IMG token으로 표기한다. (즉, 전체 이미지에 상응하는, spatial encoding을 가진 mean-pooled visual features)
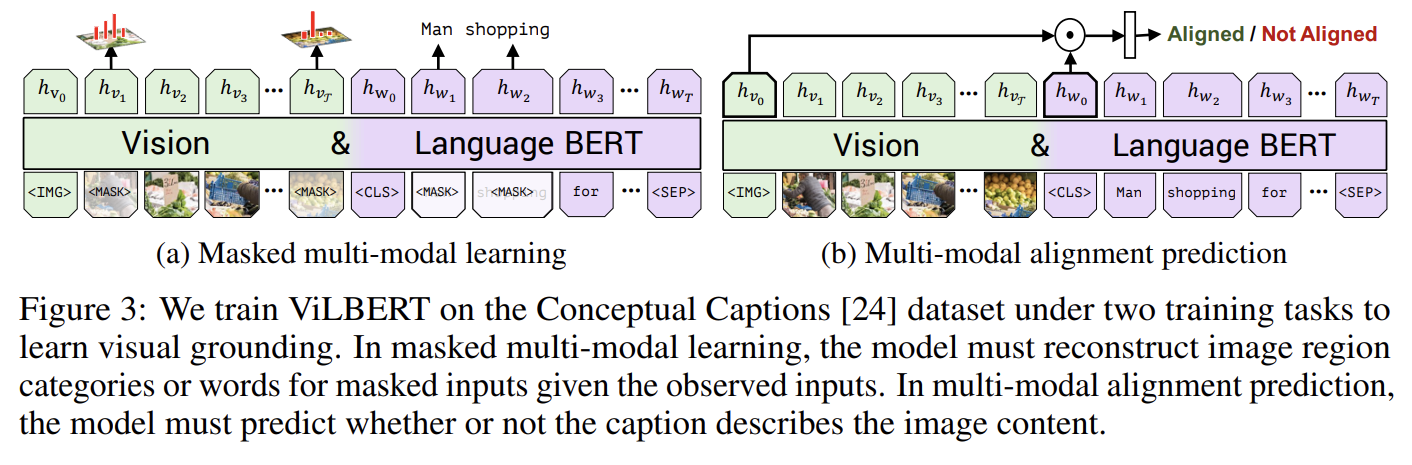
pretraining task는 masked multi-modal modelling와 multi-modal alignment prediction로 두 개다. Fig 3a의 masked multi-modal modelling task은 BERT의 MLM을 따라했는데, words와 image region inputs 둘 다의 약 15%를 mask하고 모델이 재구성하게 하는 것이다. Masked image regions은 90%로 image features이 zero out되고 10%로 변하지 않는다. Masked text inputs은 BERT처럼 처리된다. masked feature values을 직접 regress하기보다 모델은 상응하는 image region에 대한 semantic classes의 distribution을 예측한다. 이를 감독(supervise)하기 위해 feature extraction에 사용된 것과 같은 pretrained detection model에서 온 region에 대한 output distribution을 사용한다. 이 두 distributions 사이 KL divergence를 최소화하도록 모델을 학습한다. 이 선택은 language가 보통 visual content의 high-level semantics만 식별하고 정확한 image features을 재구성하지 않는다는 개념(notion)을 반영한다. 더욱이 regression loss를 사용하면 masked image/text inputs로 발생한 losses를 balance하기 힘들 수 있다.
Fig 3b의 multi-modal alignment task에는 image-text pair이
형태로 model에 주어지고 model은 image와 text가 align되어있는지, 즉 text가 image를 묘사하고 있는지 예측해야 한다. outputs 와 를 visual/linguistic inputs의 holistic representations으로 가진다. (vision-and-language
models의 다른 흔한 구조를 빌려) overall representation을 와 사이 element-wise product으로 계산하고 image와 text가 align되었는지 binary prediction를 만드는 linear layer을 학습한다. 그러나 Conceptual Captions [24] dataset은 aligned image-caption pairs만을 포함한다. 그래서 negatives을 생성하기 위해 랜덤으로 image나 caption을 다른 것과 교체한다.
ViLBERT의 linguistic stream은 BookCorpus와 English Wikipedia에 pretrain된 language model을 사용한다. region features을 추출하기 위해서는 Visual Genome dataset에 pretrain된 Faster R-CNN을 사용한다.
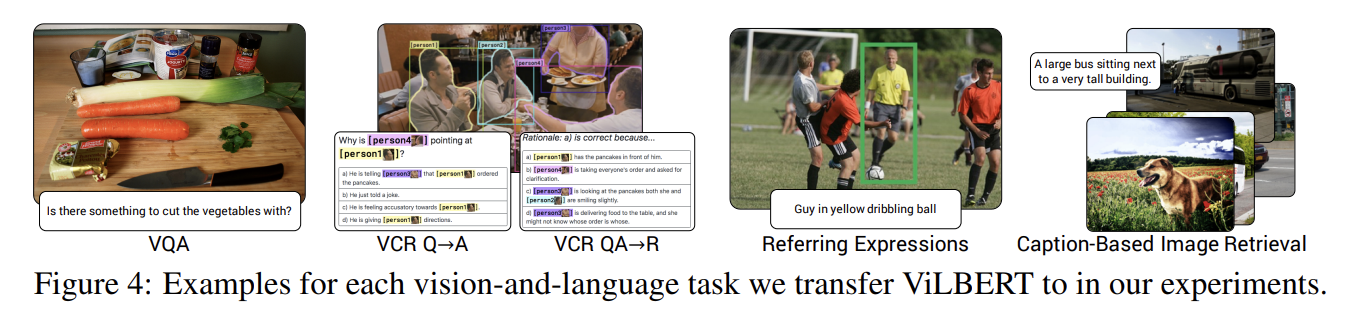
실험은 Fig 4처럼 네 유명한 vision-and-language tasks와 하나의 diagnoistic task에 transfer한다. Visual Question Answering (VQA), Visual Commonsense Reasoning (VCR), Grounding Referring Expressions, Caption-Based Image Retrieval, ‘Zero-shot’ Caption-Based Image Retrieval이다.
baseline으로 두 가지 ablative models을 사용했다. 첫째는 Single-Stream 모델로 visual/linguistic inputs을 같은 transformer blocks로 처리하는 single BERT architecture이다. 둘째는 모델로 논문이 제안한 pretraining tasks을 겪지 않은 ViLBERT다. 여전히 linguistic stream으로는 BERT initialization을 가지고 같은 Fast R-CNN 모델로 image regions을 나타낸다. task-specific baseline으로 각 task의 SOTA 모델들도 사용했다.
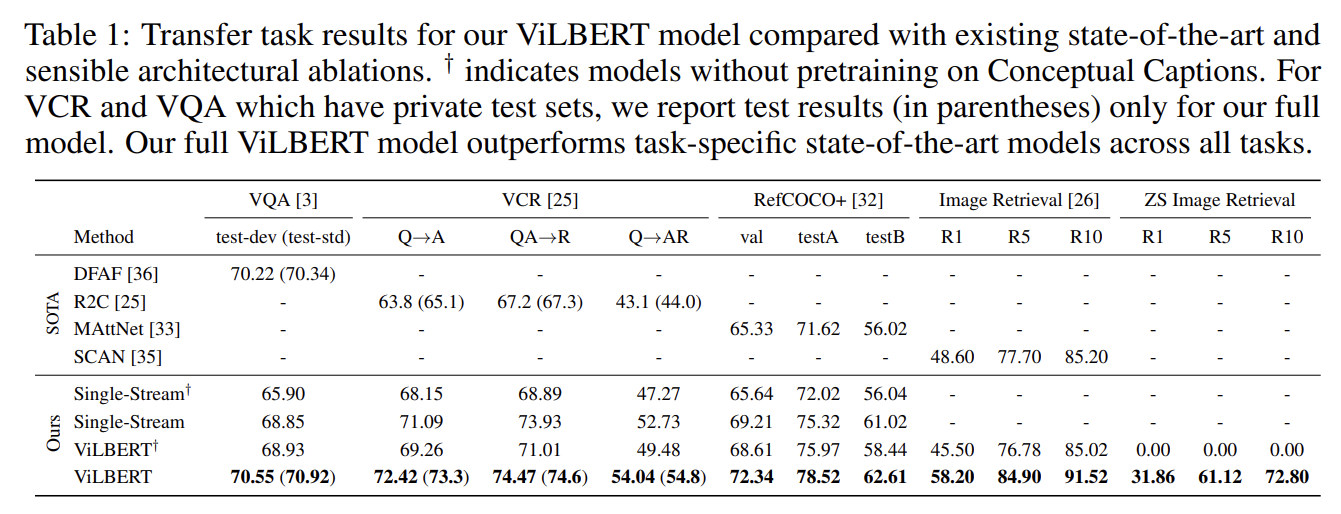
Tab 1에서 볼 수 있듯 실험 결과 1. ViLBERT가 single-stream model에 비해 성능이 향상됐고 2. pretraining tasks이 향상된 visiolinguistic representations을 낳았으며 3. ViLBERT에서 finetuning하는 것이 vision-and-language tasks에 강력한 전략이라는 사실을 관찰했다. 이 결과들은 ViLBERT가 downstream task에 활용될 수 있는 중요한 visual-linguistic relationships을 학습한다는 사실을 입증한다.
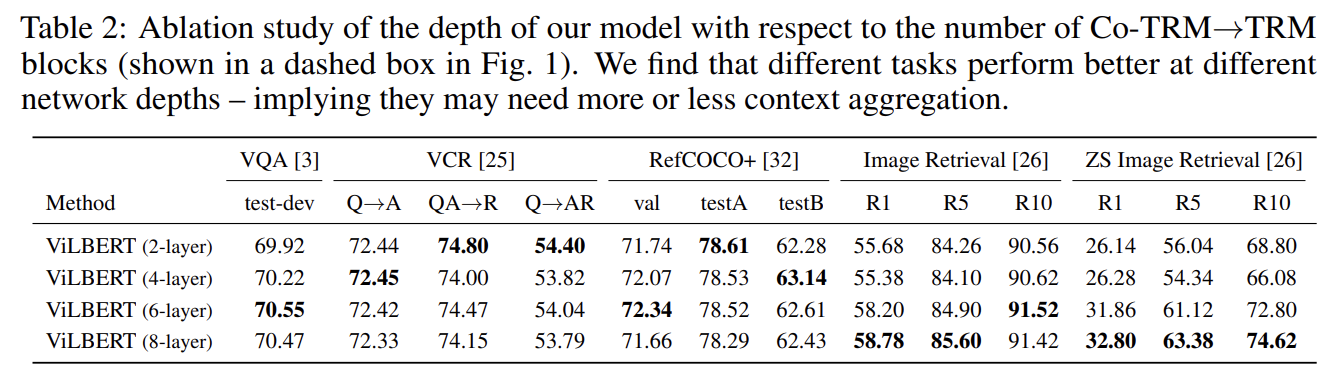
Tab 2는 다양한 depth의 ViLBERT를 비교한다. depth는 반복되는 CO-TRM→TRM blocks의 수로 고려한다. VQA, Image Retrieval tasks, zero-shot image retrieval은 depth가 깊을수록 성능이 향상됐지만 VCR과 RefCOCO+은 얕을수록 좋았다.
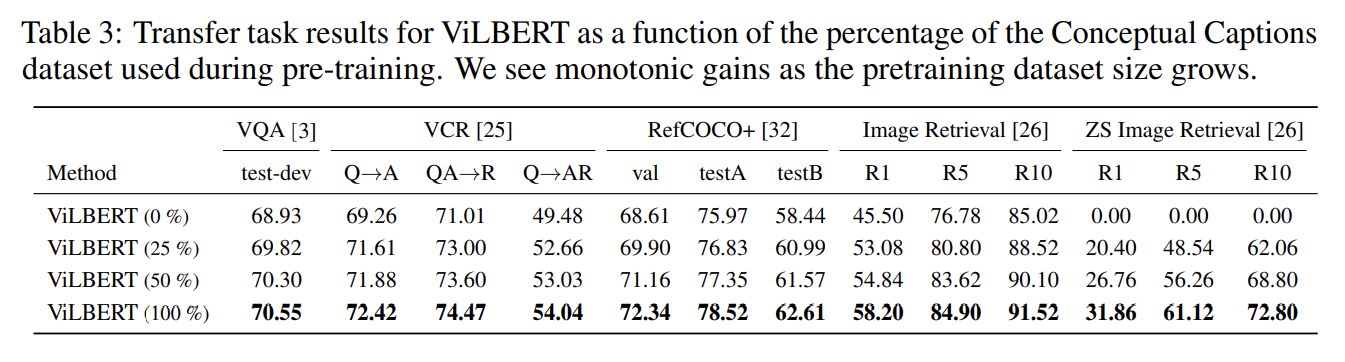
pretraining dataset 크기의 영향도 실험했다. 데이터가 많을수록 성능이 좋았다.

Conceptual Caption pretraining 도중 ViLBERT가 무엇을 배우는지 알기 위해 zero-shot caption-based image retreival와 몇가지 qualitative examples을 관찰한다. zero-shot performance가 fine-tuned model보다 꽤 낮긴 하지만 합리적으로(reasonably) 수행되는 것을 보아 ViLBERT가 pretraining 중에 vision과 language 간의 semantically meaningful alignment을 학습했음을 알 수 있다. 또 image를 input으로 넣고 image-conditioned text을 sample해서 pretrained ViLBERT model을 질적으로 조사한다. 이는 본질적으로 image captioning이다. 그러나 Conceptual Captions의 수집 절차로 인해 많은 caption이 사설이 많고(editorialized) non-visual concepts을 언급한다.
Strengths
- visual/linguistic input을 함께 처리하는 unified BERT architecture였던 VideoBERT의 단점을 지적하고 개선한다.
- vision과 language을 두 stream으로 구분하고 co-attentional transformer blocks을 통해 둘의 연관성을 pre-train하는 데 집중해서 좋은 성능을 낸다.
- downstream task에 transfer할 때 모델에 최소한의 변형만 가하면 되서 구현이 간단하다. 논문에서 실험할 때는 task 당 classifier 하나만 추가하면 됐다.
개인적으로 나도 modality 별로 따로 학습을 시키게 하는 방식이 맞다고 본다.
