오늘 리뷰할 논문은 VLP survey 논문이다.
포스트는 논문 요약/정리보다는 내 마음대로 메모하는 식이다.
논문은 5가지 측면 feature extraction, model architecture, pre-training objectives, pre-training datasets, downstream tasks에서 VLP의 최근 발전을 리뷰한 후 특정 SOTA VLP 모델들을 살펴본다.
- Image Feature Extraction
(1) OD-based Region Features (OD-RFs)
대부분 연구는 visual features 추출을 위해 pre-trained object detectors를 활용. 가장 흔히 사용되는 object detection model은 bottom-up attention을 가진 Faster R-CNN. Faster R-CNN을 통해 VLP 모델은 OD-based Region feature embedding을 얻는다. 성능은 인상적이지만 region feature 추출이 time-consuming해서 pre-trained object detectors는 pretraining 중 얼려지지만 이는 VLP 모델의 능력을 제한할 수 있다.
(2) CNN-based Grid Features (CNN-GFs)
grid features를 얻기 위해 CNN을 활용.
(3) ViT-based Patch Features (ViT-PFs)
ViT에 영감을 받아 image를 flattened 2D patches의 sequence로 입력한다.
- Video Feature Extraction
video clip은 M frames (images)로 표기된다. VLP 모델은 위의 방법들 중 주로 CNN-GFs와 ViT-PFs를 사용해 frame features를 추출한다. 이 features는 visual features로서 concatenate된 후 FC layer에 넣어서 token embedding과 동일한 lower-dimensional space에 투영된다.
- Text Feature Extraction
먼저 input sentence를 sequence of subwords로 segment한다. 그 다음 sequence의 처음과 끝에 start-of-sequence token and an end-of-sequence token을 삽입해 input text sequence을 생성한다. 상응하는 word embedding, text position embedding, text type embedding을 합침으로써 Text input representations이 계산된다.
uni-modal pre-trained models를 활용하기 위해 visual/text features를 transformer encoder에 넣어 visual/text representation을 생성한다. 논문은 이런 transformer를 Xformer라고 칭한다.
논문은 model architecture을 2가지 관점에서 분류한다.
(1) Single-stream versus Dual-stream from multi-modal fusion perspective
(2) Encoder-only versus Encoder-decoder from the overall architectural design perspective.
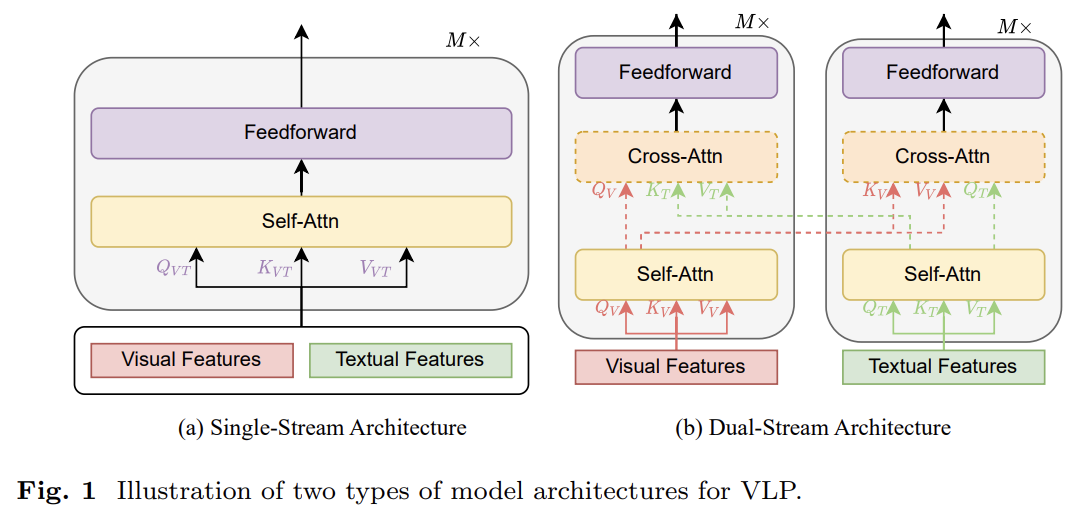
single-stream architecture는 text와 visual features가 concatenate된 후 single transformer block에 먹여지는 것이다. multimodal input을 융합하기 위해 merged attention을 활용한다. 두 modality에 같은 parameter를 사용하므로 parameter-efficient하다.
dual-stream은 concatenate하지 않고 parameter를 공유하지 않는 두 독립적인 transformer block에 각각을 넣는 것이다. cross-modal interaction을 위해 cross-attention을 활용한다. 효율을 높이기 위해 cross-attention을 사용하지 않기도 한다.
많은 VLP 모델이 encoder-only architecture를 취하는데 cross-modal representations이 final output을 생성하기 위해 곧바로 output layer에 먹여진다. 다른 VLP 모델은 transformer encoderdecoder architecture을 사용하는데 cross-modal representations가 먼저 decoder에 넣은 후 output layer에 먹여진다.
pre-training objective도 4가지로 분류한다.

-
prefix language modeling 알아보기 (SimVLM)
-
vision에서 Masked Features Regression은 이미지 영역을 가려 놓고 그걸 맞추게 하는 건데 너무 빡센 조건 아닌가? 주차장 사진에서 차를 가려놓으면 거기 차가 있다는건 알 수 있지만 버스인지 승용차인지 경차인지 이런건 맞추는게 불가능한 것 아닌가. 그래서 대신 masked feature의 object semantic class를 예측하는 Masked Feature Classification가 있네. hard label을 cross entropy로 예측할 수도 있고 soft label을 KL divergence로 예측할 수도 있다.
- Datasets for Image-language Pre-training
SBU, Flickr30k, COCO, CC3M, CC12M, Visual Genome (VG), VQA, GQA.
특수 목적 : Matterport3D, Fashion-Gen
- Datasets for Video-language Pre-training
Kinetics-400, HowTo100M, WebVid-2M, TVQA
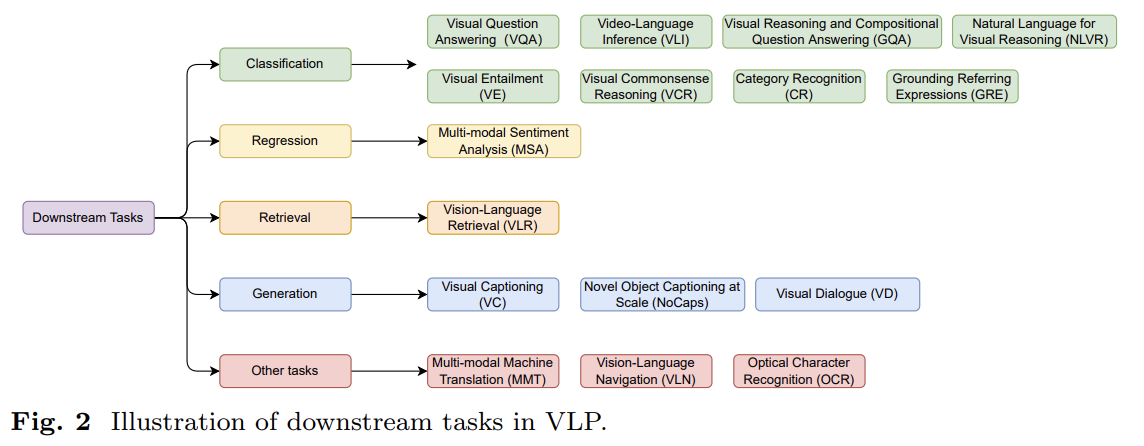
downstream task로는 다음과 같은 게 있다. Visual Question Answering (VQA), Visual Reasoning and Compositional Question Answering (GQA), Video-Language Inference (VLI), Visual Entailment (VE), Visual Commonsense Reasoning (VCR), Natural Language for Visual Reasoning (NLVR), Grounding Referring Expressions (GRE), Category Recognition (CR), Multi-modal Sentiment Analysis, Vision-Language Retrieval (VLR), Visual Captioning (VC), Novel Object Captioning at Scale (NoCaps), Visual Dialogue (VD), Multi-modal Machine Translation (MMT), Vision-Language Navigation (VLN), Optical Character Recognition (OCR).
VisualBERT가 최초의 image-text pre-training model이다.
VideoBERT가 최초의 video-text pre-training model이다.
-
SOTA에 대한 설명은 빈약하다. 이 survey는 2023년 논문인데 SOTA라는 모델들이 2021년 쯤인데다 인용수도 몇백 수준이라 읽어볼 가치가 있는 논문은 아닌 것 같다. 덩달아 이 논문의 신뢰도도 좀 의심이 된다...
-
multimodal 논문들을 제법 읽고 survey 논문을 읽으니 이해/정리가 잘 됐다. 옛날엔 survey 읽어도 절반은 이해 못한 것 같은데...
-
알아볼 것들
Prompt Tuning
model pruning
model quantization -
읽어볼 논문
T5 (논문 기니까 리뷰라도 읽어보기)
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
Photorealistic text-to-image diffusion models with deep language understanding
Networks of spiking neurons: the third generation of neural
network models
