오늘 리뷰할 논문은 최초의 knowledge distillation 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- Distilling the Knowledge in a Neural Network 논문 리뷰
- [논문 리뷰] Distilling the Knowledge in a Neural Network
- [논문 리뷰] Distilling the Knowledge in a Neural Network (NIPS 2014 Workshop)
Summary
ensemble 방식은 cumbersome하고 연산이 비싸다. Caruana와 동료들은 ensemble의 지식을 single model로 압축할 수 있음을 보였는데 논문은 다른 compression technique을 사용해 이를 발전시킨다.
cumbersome model의 일반화 능력을 small model로 전이하는 명백한 방법은 cumbersome model이 생성한 class probabilities를 small model을 학습하기 위한 "soft targets"로 사용하는 것이다. 이 transfer 단계에서는 동일한 training set이나 별개의 "transfer" set을 사용할 수 있다. cumbersome model이 간단한 모델들의 ensemble이라면 그들 각각의 predictive distributions의 arithmetic/geometric mean을 soft targets으로 사용할 수 있다. soft targets가 high entropy를 가진다면 그들은 hard targets보다 training case 당 더 많은 정보를 제공하고 training cases 간 gradient가 variance가 더 작으니 small model은 original cumbersome model보다 더 적은 data로 훈련될 수 있고 더 큰 learning rate를 사용할 수 있다.
MNIST를 예시로 들면 cumbersome model은 높은 신뢰도로 거의 항상 정확한 답을 생성하는데 많은 정보가 soft targets 내 아주 작은 확률의 비율에 들어있다. 예를 들어 숫자 2를 10e−6의 확률로 3으로 예측하고 10e−9의 확률로 7로 예측할 수 있는데 이는 2가 3, 7과 비슷한 구조를 가진다는 귀중한 정보를 포함하는 것이다. 그러나 이는 transfer stage 중에 cross-entropy cost function에 아주 작은 영향만 미치는데 확률이 0에 너무 가깝기 때문이다. Caruana와 동료들은 이 문제를 (small model을 학습할 때 softmax가 생산한 확률을 targets로 사용하는 대신) logits (= inputs to the final softmax)를 사용함으로써 피하는데 cumbersome model이 생산한 logits와 small model이 생산한 logits 사이 squared difference를 최소화한다. 논문의 더 일반화된 해결책인 "distillation"은 cumbersome model이 suitably soft set of targets를 생산할 때까지 final softmax의 temperature을 올린다. 그 다음 small model을 학습시킬 때 이 soft targets를 match하기 위해 동일한 high temperature을 사용한다.
small model 학습을 위한 transfer set은 전부 unlabeled data로 구성할 수도 있고 original training set을 사용할 수도 있다. original training set을 사용해도 잘 작동했는데, 특히 objective function에 small model이 soft target뿐 아니라 true targets(hard targets)도 예측하게 격려하는 작은 항을 추가할 때 잘 작동했다.

neural network는 일반적으로 softmax layer를 사용해 logit 를 다른 logits와 비교함으로써 class probability 로 변환한다. T는 temperature이고 보통 1이다. T 값이 클수록 classes에 대한 softer probability distribution을 생성한다. small model을 학습할 때는 cumbersome model과 동일한 high temperature을 사용하지만 학습이 끝난 후엔 1을 사용한다.
transfer set의 전부나 일부에 correct labels을 알고 있다면 distilled model이 correct labels을 생성하도록 훈련함으로써 성능을 향상시킬 수 있다. 논문은 2가지 objective functions을 weighted average했다. 첫째 objective function은 soft targets에 대한 cross entropy이고 cumbersome model이 soft targets을 생성할 때 사용한 것과 동일한 high temperature을 softmax에 사용한다. 둘째 objective function은 correct labels에 대한 cross entropy다. 이는 distilled model의 softmax 내 정확히 동일한 logits을 사용해 계산하지만 temperature은 1이다. 둘째 objective function에 상당히 더 낮은 weight을 사용해야 성능이 좋았다. soft targets로 생성한 gradients의 크기가 배로 scale되므로 hard와 soft targets 모두를 사용할 때 soft targets로 생성한 gradients를 배 해주는 것이 중요하다.
cumbersome model은 soft target probabilities p_i를 생산하는 logits v_i를 가질 때 각 logit z_i에 대한 cross-entropy gradient, dC/dzi는 다음과 같다.
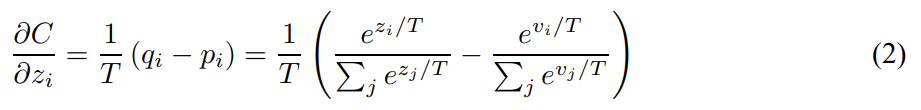
T가 logits의 크기에 비해 커서 로 근사된다면 다음과 같다.
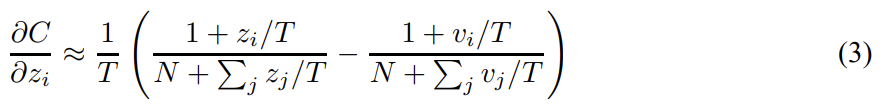
이제 각 transfer case에 대해 각 logits가 zero-meaned이라고 가정한다.

따라서 high termperature limit에서 distillation은 각 transfer case에 독립적으로 logits이 zero-meaned일 때 을 최소화하는 것과 동등한 것이다. lower temperatures에서 distillation은 average보다 negative한 logits을 matching하는 데 덜 신경쓴다. 이는 잠재적 장점인데 이런 logits는 cumbersome model을 학습할 때 사용한 cost function에 의해 거의 무제약적이기 떄문에 noisy하기 때문이다. 반면 very negative logits는 cumbersome model이 획득한 지식에 대한 아주 유용한 정보를 전달할 수도 있다. 논문은 distilled model이 cumbersome model의 지식을 모두 포착하기엔 너무 작을 때 intermediate temperatures가 가장 잘 작동함을 보여 large negative logits를 무시하는 게 유용할 수 있음을 보인다. 다시 말해 아까 MNIST를 예시로 들면 T가 크면 3, 7 같은 작은 logits도 강조되어 정보를 얻을 수 있는데 noisy한 정보가 내포될 수도 있다는 것이고 T가 작으면 3, 7이 덜 강조되고 hard target으로 학습할 때처럼 원본 osftmax와 비슷해진다는 것이다.
(Preliminary experiments on MNIST, Experiments on speech recognition 생략)
개별 모델이 크고 dataset이 커서 연산량이 클 때 ensemble은 비효과적이다. 논문은 그런 dataset의 경우 서로 다른 confusable subset of the classes 각각에 집중하는 specialist models을 학습하는 것이 ensemble을 학습하는 데 전체 연산량을 감소시킬 수 있음을 보인다. fine-grained distinctions을 만드는 데 집중하는 specialists의 주요 문제는 그들이 쉽게 overfit한다는 점이며, 이를 soft target으로 어떻게 예방하는지 알아보자.
JFT는 100 million labeled images with 15,000 labels를 가진 Google 내부 데이터셋이다.
class 수가 매우 많으면 ensemble을 위해 모든 데이터에 학습된 하나의 generalist model와 헷갈리기 쉬운 클래스의 subset 데이터에 대해서 훈련된 많은 specialist models을 사용하는 것이 합리적이다.
overfitting을 줄이고 lower level feature detectors 학습을 공유하기 위해 각 specialist model은 generalist model의 weight으로 초기화된다. 이 weight를 절반은 special subset에서, 절반은 나머지 training set에서 랜덤하게 sample한 example로 훈련시킨다. training 이후, oversample된 specialist class 비율의 log 값으로 dustbin class의 logit을 증가시킴으로써 biased training set을 수정한다.

specialist를 만들기 위한 groupings of object categories를 결정하기 위해 full network가 자주 헷갈리는 categories에 집중했다. generalist model의 predictions의 covariance matrix에 clustering algorithm를 적용해서 자주 함께 예측되는 set of classes 이 specialist models 중 하나인 m의 target으로 사용되게 했다. covariance matrix의 columns에 K-means algorithm의 on-line version을 적용해서 합리적인 clusters를 획득했다.
먼저 specialists를 포함하는 ensemble이 얼마나 잘 작동하는지 확인해보자. specialist models에 더불어 항상 generalist model를 가지는데 그래야 specialist가 없는 class를 다룰 수 있고 어떤 specialist를 사용할지 결정할 수 있기 때문이다. input image x가 주어질 때, 다음 2단계에 걸쳐 top-one classification을 한다.
-
각 test case에 대해 generalist model로 n most probable classes를 찾는다. 이 set of classes를 k라고 부른다. 실험에선 n=1을 사용했다.
-
special subset of confusable classes 와 k가 교집합이 존재하는 모든 specialist models m을 골라 이를 active set of specialists 라고 부른다(이 집합은 공집합일 수도 있다). 그 다음 모든 classes에 대해 다음 식을 최소화하는 full probability distribution q를 찾는다.
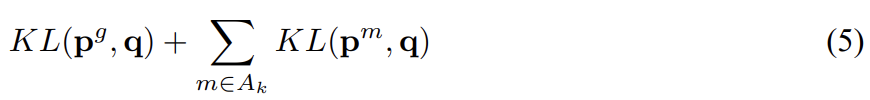
KL은 KL divergence이고 는 specialist model과 generalist full model의 probability distribution이다. distribution 은 m의 모든 specialist classes와 single dustbin class에 대한 distribution이며 full q distribution로부터 KL divergence를 계산할 때 full q distribution이 m의 dustbin 내 모든 classes에 할당하는 probabilities를 모두 합한다.

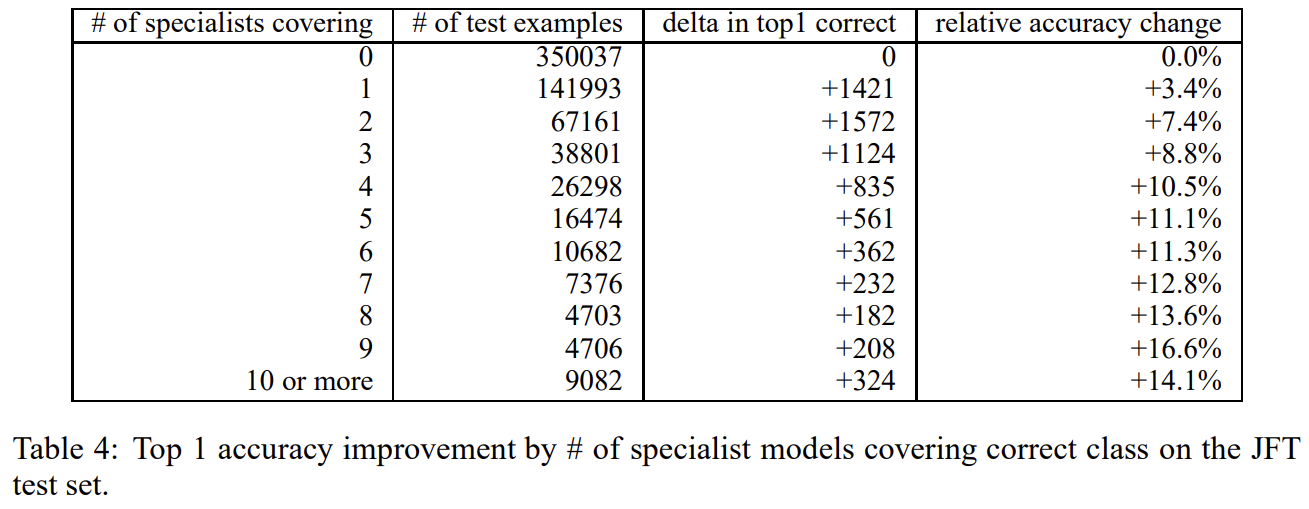
61 specialist models를 가지고 test 정확도가 4.4% 향상됐다. specialist 학습은 매우 빠르고, 병렬적으로 학습 가능하다.

soft targets이 single hard target이 encode할 수 없는 유용한 정보를 담음을 보였다.
specialist model은 non-specialist classes을 single dustbin class로 합친다(collapse). specialist가 모든 classes에 대한 full softmax를 가지도록 허용하면 early stopping보다 좋은 overfitting 예방법이 존재할 지도 모른다.
Strengths
- 쉬운 class는 generalist가 해결하고 헷갈리는 건 specialist를 두는 ensemble 아이디어가 좋았다.
- 정보를 더 풍부하게 전달할 수 있는 soft target 아이디어가 좋았다.
- Preliminary experiments on MNIST에서 transfer set에서 3을 제외하고 전이학습시켰는데도 3에 대한 오류가 적은 걸 보니 soft target으로 좀 더 풍부한 정보를 제공했기 때문에 3에 대한 정보가 간접적으로 전달된 것 같다. 그러니까 (3을 제외한) 다른 숫자 간 분포가? 명확하기 때문에 3은 빈자리(공백)로서의 정보가 전달된 것 같다.
Weaknesses
- 그런데 soft target은 softmax를 target으로 사용하지 않는 다른 형식의 task에 적용하기 힘든 것 같다. distillation 가능한 task가 제한적이다.

다른 포스트에선 위와 같이 지적했다.
label smoothing과도 관련 있는 듯하다.
