
오늘 리뷰할 논문은 CycleGAN이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- CycleGAN
- [논문리뷰] Cycle GAN: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
코드를 실습해 봐도 좋을 것 같다.
Summary
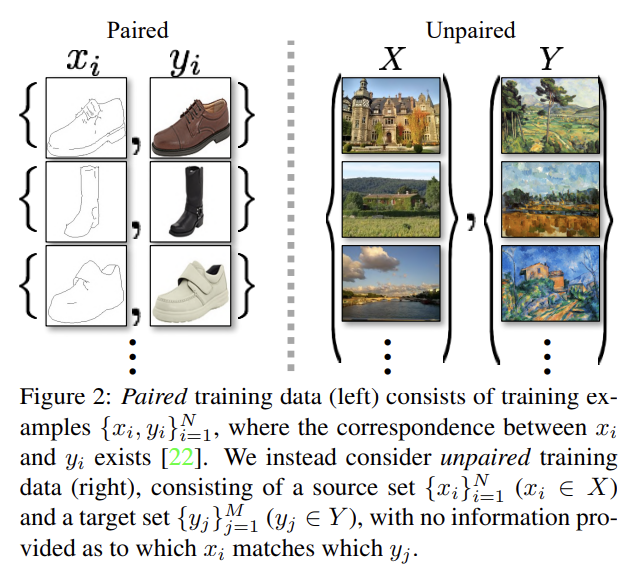
논문은 image-to-image translation을 목표로, paired training data가 없는 상황에서 source domain X에서 target domain Y로 mapping하는 G : 를 학습하고자 한다. 다시 말해 adversarial loss를 사용해 G(X)의 distribution과 Y의 distribution이 구분불가능하도록 하는 것이다. mapping이 매우 under-constrained이기 때문에 inverse mapping F : 와 함께 쌍으로 사용해 F(G(X)) ≈ X, G(F(y)) ≈ y를 강제하는 cycle consistency loss를 소개한다.
논문은 CycleGAN을 collection style transfer, object transfiguration, season transfer, photo enhancement 등에 적용해본다. 그리고 style과 content의 hand-defined factorizations이나 shared embedding functions에 기반하는 기존의 방법들과 비교해 이 baseline보다 CycleGAN의 성능이 뛰어남을 확인한다.
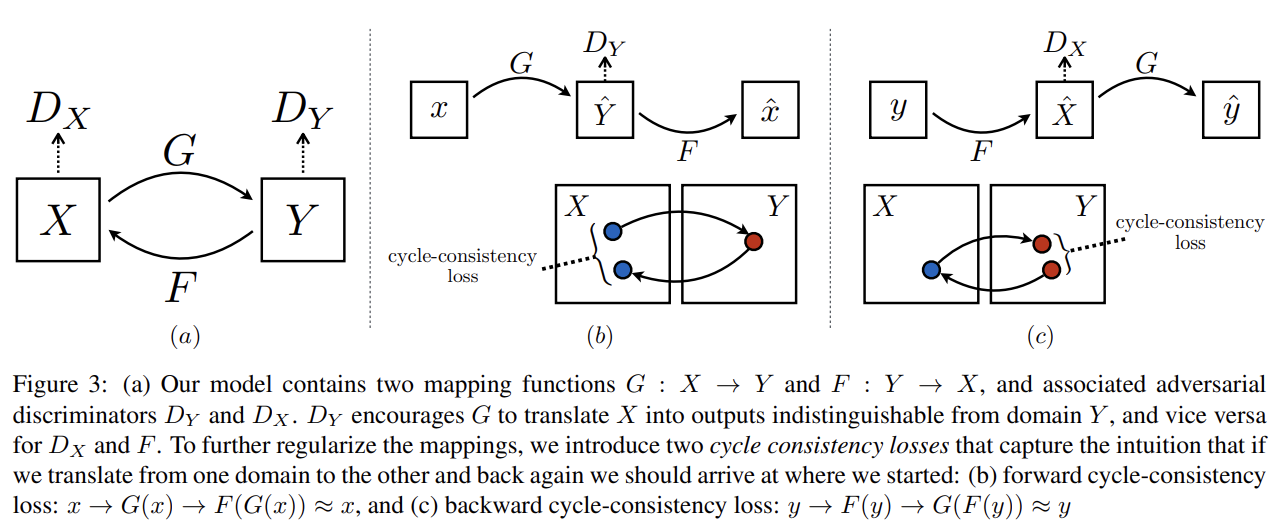
논문은 두 개의 discriminator 를 사용한다. 는 images x와 translated images F(y)를 구분하고 는 y와 D(x)를 구분한다. objective은 두 종류 항, adversarial losses과 cycle consistency losses를 사용한다. adversarial loss는 generated image의 분포를 target domain의 분포와 matching하고 cycle consistency loss는 G와 F가 서로 모순되는 것을 방지한다.
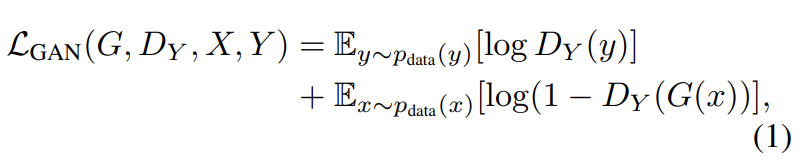
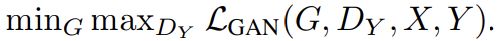
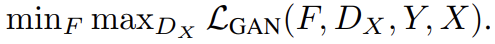
adversarial loss는 식 (1)과 같다. G는 domain Y와 비슷한 G(x)를 생성하려하고, 는 translated samples G(x)와 real samples y를 구분하려 한다. G는 식을 최소화하려하고 D는 최대화하려한다. F의 adversarial loss도 비슷한 형태다.
adversarial training은 G, F가 target domain과 비슷한 분포의 결과를 산출할 수 있게 해준다. 하지만 충분히 큰 capacity를 가진 네트워크는 동일한 set of input images를 target domain의 그 어떤 random permutation of images으로도 map할 수 있다. 즉, output의 distribution이 target과 동일한 mapping이 무수히 많이 존재할 수 있다는 것이다. 따라서 adversarial loss 혼자로는 individual input x가 desired output y로 map될 것을 보장할 수 없다.

가능한 mapping function의 space를 축소하기 위해서 논문은 학습된 mapping function들이 cycle-consistent할 것을 주장한다. image translation cycle이 x를 복원하는 x → G(x) → F(G(x)) ≈ x를 forward cycle consistency, y를 복원하는 y → F(y) → G(F(y)) ≈ y를 backward cycle consistency라고 부른다.
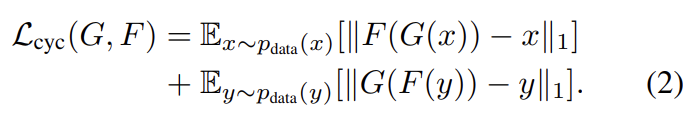
식 (2)의 cycle consistency loss가 두 consistency를 장려한다. L1 norm 대신 F(G(x))와 x 사이 adversarial loss도 사용해봤지만 성능 향상은 관찰되지 않았다.
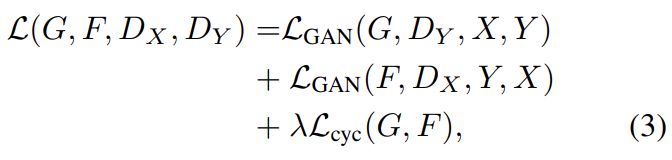
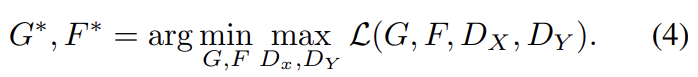
전체 objective는 위와 같다. λ는 두 종류 objective 사이 상대적인 중요도를 조절한다. 논문의 실험에선 λ = 10으로 두었다. CycleGAN은 두 autoencoder, F ◦ G : X → X와 G◦F : Y → Y를 학습하는 것으로 해석할 수도 있다. 그러나 중간에 상대 domain으로의 translation을 거친다는 특별한 구조가 있다. 이는 “adversarial autoencoders”의 특별한 형태로 생각할 수 있으며 임의의 target distribution을 match하기 위해 adversarial loss를 사용해 bottleneck layer of an autoencoder를 학습하는 것으로 볼 수 있다. 이 경우에 X → X autoencoder의 target distribution은 domain Y가 된다.
network architecture은 Johnson et al. [23]의 것을 조정했다. 이 네트워크는 3 convolutions, 여러 residual blocks, 2 fractionally-strided convolutions with stride 1/2, features를 RGB로 map하는 하나의 convolution으로 이루어진다. 128 × 128 images에는 6 blocks을 사용하고 256 x 256 이상의 해상도에서는 9 blocks을 사용한다. Johnson et al.과 비슷하게 instance normalization을 사용한다. discriminator networks는 70 × 70 PatchGANs을 사용해 70 × 70 overlapping image patches를 real/fake인지 분류한다. patch-level discriminator architecture은 full-image discriminator보다 parameter가 적고 fully convolutional fashion으로 임의의 크기의 image에 작동할 수 있다.
training을 안정화하기 위해 최신 연구의 2개 기법을 적용했다. 첫째로 식 (1)의 에서 negative log likelihood objective를 least-squares loss로 교체했다. 이 loss는 training 중에 더 안정적이고 s higher quality results를 생성한다. 구체적으로는 GAN loss 에 대해 G가 를 최소화하도록 학습하고 D가 를 최소화하도록 학습했다.
둘째로, model oscillation을 줄이기 위해 Shrivastava et al.의 전략을 사용해서 latest generators가 생성한 images대신 50 previously created images를 저장할 수 있는 buffer를 두어 history of generated images를 사용한다.
실험은 우선 ground truth input-output pairs이 존재하는 paired datasets에 CycleGAN을 다른 최신 방법들과 비교했다. 그리고 adversarial loss과 cycle consistency loss의 중요성을 확인했다. 마지막으로 paired data가 존재하지 않는 여러 application에서 모델의 generality를 입증했다.


Cityscapes dataset으로 semantic labels↔photo, Google Maps에서 scrape한 데이터로 map↔aerial photo를 변환했다. map↔aerial photo task은 Amazon Mechanical Turk (AMT)로 perceptual study를 했다. 알고리즘 당 25 participants를 불러 real, fake (=generated image)로 이루어진 이미지 쌍을 준 후 어느 게 진짜 사진인지 맞추게 한 것이다.
Cityscapes labels→photo task를 평가하기 위해선 FCN score을 사용했다. FCN metric은 off-the-shelf semantic segmentation algorithm을 이용해 generated photos가 얼마나 interpretable한지 평가하는 것이다. (자세한 내용 생략)
baseline으로는 CoGAN, SimGAN, Feature loss + GAN, BiGAN/ALI, pix2pix을 사용했다. Fig 5, 6을 보면 다른 baseline들은 다 좋은 결과를 얻는 데 실패했지만 CycleGAN은 종종 fully supervised pix2pix와 비견되는 결과를 만들었다.
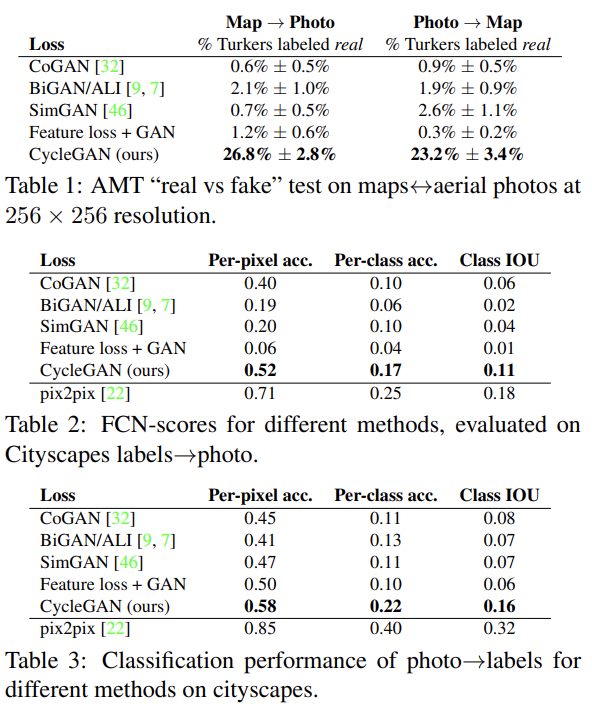
Table 1은 다른 baseline들이 participants를 거의 속이지 못한 반면 CycleGAN은 1/4 정도 속였음을 보여준다. Table 2, 3도 CycleGAN이 baseline보다 성능이 우수함을 보여준다.
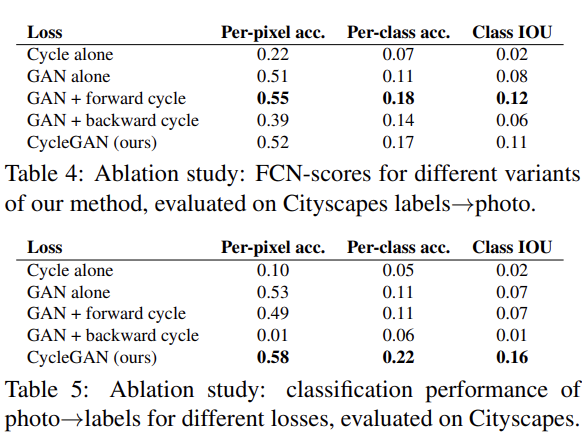
Table 4, 5는 각 loss의 중요성을 알기 위해 ablation study를 한 결과다. GAN loss와 cycle-consistency loss가 모두 중요하며 cycle-loss가 한쪽 방향만 있을 경우, 즉 forward cycle loss나 backward cycle loss 둘 중 하나만 있으면 training instability를 유발해 mode collapse를 초래함을 알 수 있었다.
논문은 paired training data가 존재하지 않는 여러 application에 CycleGAN을 적용해본다. single selected piece of art 대신 entire collection of artworks의 style을 transfer하는 Collection style transfer 과제, ImageNet의 한 object class를 다른 class로 바꾸는 Object transfiguration 과제, 사진에서 겨울, 여름을 바꾸는 Season transfer 과제, Photo generation from paintings 과제, Photo enhancement 과제를 테스트한다. Gatys et al.의 neural style transfer과 결과를 비교하기도 한다. 설명과 사진은 생략하겠다.

마지막으로 논문은 CycleGAN의 한계에 대해서도 설명한다. Fig 17처럼 결과물이 uniformly positive하지 못하며 training dataset의 distribution characteristics 때문에 failure이 발생하기도 한다. CycleGAN으로 구한 결과가 paired training data로 얻은 결과와 lingering gap을 보이기도 한다.
Strengths
- 비교적 간단한 architecture로 강력한 성능을 구현했다.
- paired training data가 없는 unsupervised 학습으로 supervised pix2pix와 비견할 만한 퀄리티다.
