오늘 리뷰할 논문은 conditional GANs, CGAN 논문이다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
- [논문 리뷰 및 실습]Conditional GAN
- [논문 리뷰] Conditional Generative Adversarial Nets
- [논문리뷰]Conditional Generative Adversarial Nets(CGAN)
Summary
논문은 기존 GAN에 class label 같은 추가적인 정보를 제공해서, 즉 conditioning해서, 생성되는 sample을 조절하는 CGAN을 제안한다.
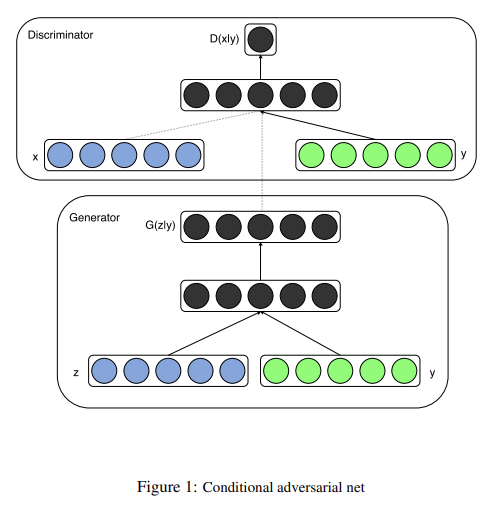
generator와 discriminator이 둘 다 extra information y에 condition되어 있다면 GAN을 conditional model로 확장할 수 있다. y는 class label이나 다른 modalities에서 온 data 등 아무 종류의 auxiliary information이 될 수 있다. conditioning은 G, D의 additional input layer에 y를 feed함으로써 수행할 수 있다.
Generator에는 prior input noise 와 y가 joint hidden representation에 묶이고 discriminator에는 x와 y가 discriminative function의 input으로 사용된다.
GAN의 objective은 식 (1), CGAN의 objective은 식 (2)와 같다.
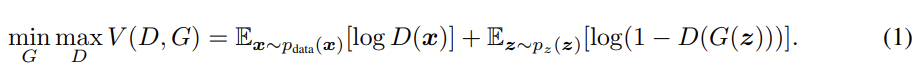
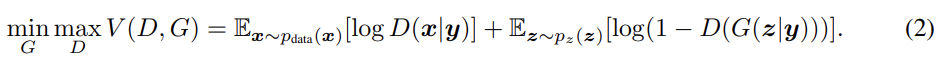
논문은 one-hot vector로 encoding한 class label을 condition으로 사용하여 MNIST 데이터셋을 학습시킨다.
G에서 100-d noise prior z는 unit hypercube 내의 uniform distribution에서 뽑았고 z와 y는 둘 다 ReLU activation을 거쳐 각각 200, 1000 layer size의 hidden layers로 map된 후 1200-d의 hidden ReLu layer로 map됐다. 그리고 마지막으로 final sigmoid unit layer을 거쳐 784-dimensional MNIST samples을 생성했다.
D는 x를 240 units, 5 pieces의 maxout layer로 map하고 y를 50 units, 5 pieces의 maxout layer로 map한다. 둘의 hidden layers은 240 units, 4 pieces의 joint maxout layer에 map되고 sigmoid layer에 feed된다.
학습은 size 100의 mini-batch로 SGD를 사용했다. G, D 모두 0.5 확률로 dropout를 사용했다. validation set에 log-likelihood estimate가 가장 좋은 순간 학습을 끝냈다. Fig 2는 생성 결과다.

또 논문은 mulitmodal에 CGAN을 적용한다. 구체적으로는 사진의 user-generated metadata (UGM), 그러니까 유저가 사진에 붙인 태그를 사용하는 것이다. 논문은 multi-label predictions을 가지고 automated tagging of images을 하고자 CGAN을 사용해 image features에 condition된 tag-vectors의 distribution을 구한다.
image features를 위해 21,000 labels을 지닌 ImageNet dataset에 convnet [13]을 pre-train하고 마지막 FC layer에서 얻은 4096 units을 image representation으로 사용한다.
word representation을 위해선 YFCC100M dataset metadata에서 user-tags, titles, descriptions을 concatentate하여 text corpus을 모은다. text를 pre-processing, cleaning한 후 200 word vector size의 skip-gram model를 훈련시킨다. 200번보다 적게 나타나는 단어는 vocabulary에서 제외했고 그 결과 247465 size의 dictionary를 얻었다.
CGAN 학습 중 convolutional model과 language model은 fix된 상태로 둔다.
실험에는 MIR Flickr 25,000 dataset을 convolutional model, language model에 사용해서 images와 tags features를 구한다. 여러 tag를 가진 image는 training set 내에서 각 tag마다 한번씩 반복됐다.
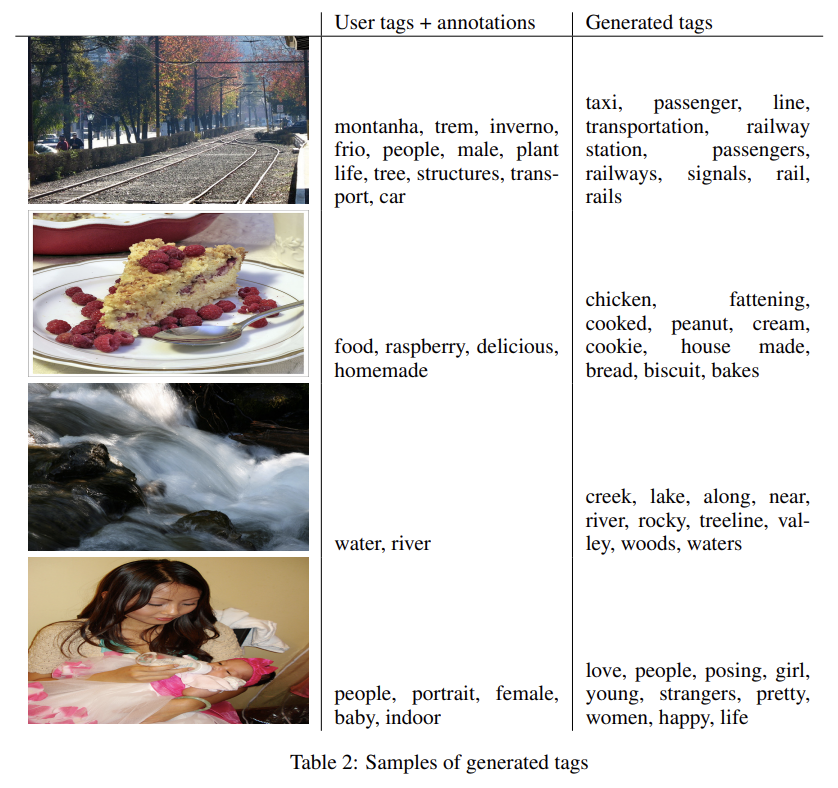
평가를 위해 image마다 100 samples을 생성하고 cosine
similarity of vector representation를 사용해 top 20 closest words를 찾았다. 그리고 100 samples 중 top 10 most common words을 골랐다.
Strengths
- GAN에 추가 정보를 넣어 생성되는 결과를 조절할 수 있다.
- 향후 발전 가능성이 다양하다.
- 추가 정보의 종류가 제한이 없기 때문에 multi-modality에도 적용할 수 있다.
GAN 논문이 2014년 6월에 나왔는데 이 논문은 11월에 나왔다. 5개월 만에 나온 만큼 내용이 쉽고 길이도 짧아서 읽기 편했다. 물론 길이나 난이도와 별개로 아이디어는 굉장히 중요하고 핵심적이었다.
CGAN도 실습을 해보면 좋을 것 같다.
