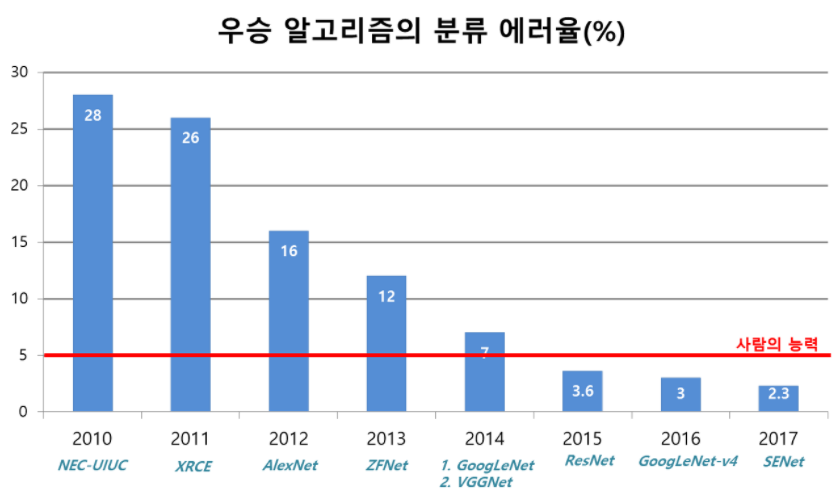
오늘 리뷰할 논문은 ILSVRC 2017에서 우승한 SENet 논문이다. 논문은 “Squeeze-and-Excitation” (SE) block를 소개함으로써 channel relationship에 집중한다. SE block은 channel간 상호의존성을 명시적으로 modeling하여 channel-wise feature responses를 adaptively recalibrate한다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문 읽기] SENet(2018) 리뷰, Squeeze-and-Excitation Networks
- [논문 리뷰] SENet 설명 (Squeeze-and-Excitation Networks)(2018)
Summary
lightweight gating mechanism을 구성하는 SE block은 global information을 사용하는 channels 간 dynamic, non-linear dependencies를 명시적으로 modeling하여 learning process를 편하게 하고 network의 representational power를 상당히 향상시킨다.
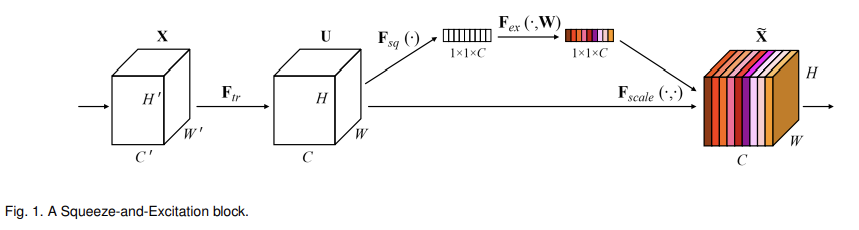
SE building block의 구조는 위와 같다. input X가 어떤(any) transformation F_tr을 거쳐(그러니까 layer 몇 개를 통과한 결과라는 의미인듯, 다시말해 F_tr은 convolutional operator) feature U가 된 후, squeeze와 excitation을 거쳐 feature recalibration를 한다.
squeeze operation은 feature map의 spatial dimensions (H × W)을 종합하여 channel descriptor을 생성하는 것이다. 이 descriptor의 기능은 channel-wise feature responses의 global distribution의 embedding을 생성하여 모든 layer에서 global receptive field에서 온 정보가 사용될 수 있게 하는 것이다.
excitation operation은 embedding을 input으로 삼고 per-channel modulation weights을 생성하는 단순한 self-gating mechanism이다. 이 weights은 U에 적용되어 SE block의 output을 생성하고, 이 output이 다음 layer로 전해진다.
SE block을 쌓은 걸 SENet이라 부르고, 깊이에 따라 SE block의 역할이 다르다. earlier layers에서 SE block은 class-agnostic manner로 informative features를 촉발해 shared low-level representations를 강화한다. later layers에선 SE block들이 specialised되며, 몹시 class-specific manner로 서로 다른 input에 반응한다. 결과적으로 SE block들로 수행된 feature recalibration의 이익이 network를 통해(through) 축적될 수 있다.
SE block은 구조가 단순하고 기존의 모델들에서 대응하는 부분을 SE block으로 교체하는 것만으로 쉽게 이용할 수 있다. 또 computationally lightweight하여 model complexity와 computational burden를 조금만 올린다.
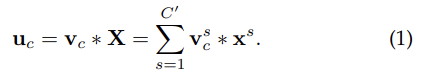
일반적인 convolution을 표현한 식은 위와 같다. v_c는 c번째 kernel을 의미하며 *는 convolution operator이다. output이 모든 channel을 거친 summation으로 계산되기 때문에 channel dependencies는 v_c 안에 implicitly embedded되어 있으며 filter에 의해 포착된 local spatial correlation와 얽혀있다. 즉 convolution으로 model된 channel relationships은 선천적으로 implicit하고 local하다. 그래서 SE block을 사용하는 것이다.
Squeeze: Global Information Embedding
각 filter는 local receptive field와 계산되므로 그 영역 밖의 contextual information은 사용할 수 없다. 이 문제를 완화하기 위해 global spatial information을 channel descriptor로 squeeze한다. channel-wise statistics(=channel descriptor)를 만들기 위해 global average pooling을 사용하며, spatial dimensions H × W를 따라 U를 압축시켜 statistic z를 만든다. z의 c번째 element는 다음 사진과 같이 계산한다. (이는 전체 image의 정보를 채널 별로 압축했다고 볼 수 있다)
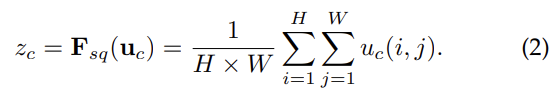
Excitation: Adaptive Recalibration
이제 squeeze로 얻은 정보를 바탕으로 channel-wise dependencies를 capture한다. 이를 위해 function이 2가지 기준을 만족해야 하는데, 1. flexible해야 하며, 다시 말해 channel 간 non-linear interaction을 학습할 수 있어야 하며, 2. (one-hot activation을 하는 게 아니라 multiple channels가 emphasize될 수 있어야 하니) non-mutually-exclusive relationship을 학습해야 한다. 논문에서는 sigmoid activation와 함께 simple gating mechanism을 사용해 이 기준을 통과한다.
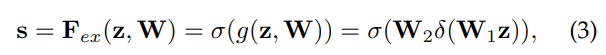
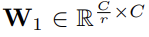
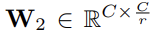
δ는 ReLU다. model complexity를 제한하고 generalisation를 돕고자 2층의 two fully-connected (FC) layers 사이에 bottleneck을 형성한다. W1, W2의 차원을 보면 ratio r만큼 dimension reduction이 일어났다가 ReLU를 통과한 후 다시 dimension increase를 해서 C차원으로 복구된 것을 볼 수 있다.
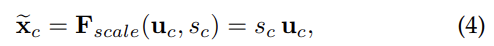
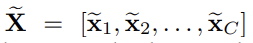
SE block의 최종 output은 위와 같다. Fscale은 channel-wise multiplication을 한 것이다. 즉, channel 별로 excitation에서 구한 가중치(s)를 U에 곱해준 것이다. 맨 위의 사진을 보면 (가중치를 의미하는) 색깔이 U의 각 채널에 입혀진 걸 볼 수 있다.
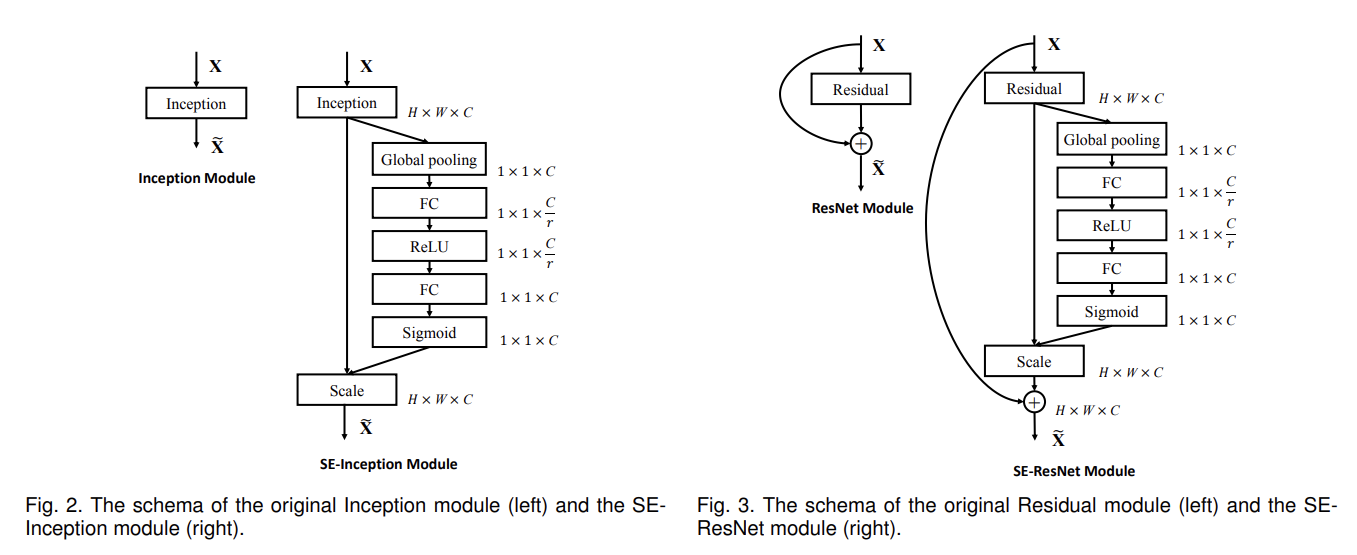
SE block은 flexible한데, 기존의 architecture에서 바꾸거나 끼워넣을 수 있다는 의미다. 위의 사진에선 inception module과 resnet module을 예시로 보여준다.
ablation study에서 흥미로웠던 점 몇가지만 짚어보겠다. 실험은 ResNet-50을 backbone architecture로 사용했으며, excitation operation의 FC layer에서 bias를 없애는 게 channel dependency를 촉진하는데 더 도움이 되서(경험적으로 알아냄) 그렇게 했다고 한다.
reduction ratio r의 경우, 성능과 연산량의 tradeoff를 결정하는 hyper-parameter중 하나다. 그런데 서로 다른 층에서 SE block의 역할이 다르기 때문에 하나의 r값을 전체 network에서 통일시키는 것은 optimal하지 않을 수 있다.
Squeeze Operator의 경우 여기선 global average pooling을 사용했는데, global max pooling도 그에 비해 성능이 별로 나쁘지 않았다. 논문에서는 SE block의 성능이 특정 aggregation operator 선택에 robust하다고 설명한다.
반면 Excitation Operator의 변경은 성능에 큰 차이를 일으켰는데, sigmoid 대신 ReLU와 tanh를 사용해보니 tanh는 성능을 약간 떨어뜨리지만 ReLU는 많이 떨어뜨려서 SE-ResNet-50의 성능을 비교대상(baseline)인 ResNet-50보다 낮게 나타났다. 이를 통해 SE block에 excitation operator를 조심스럽게 설정하는 것이 중요하다는 것을 알았다.
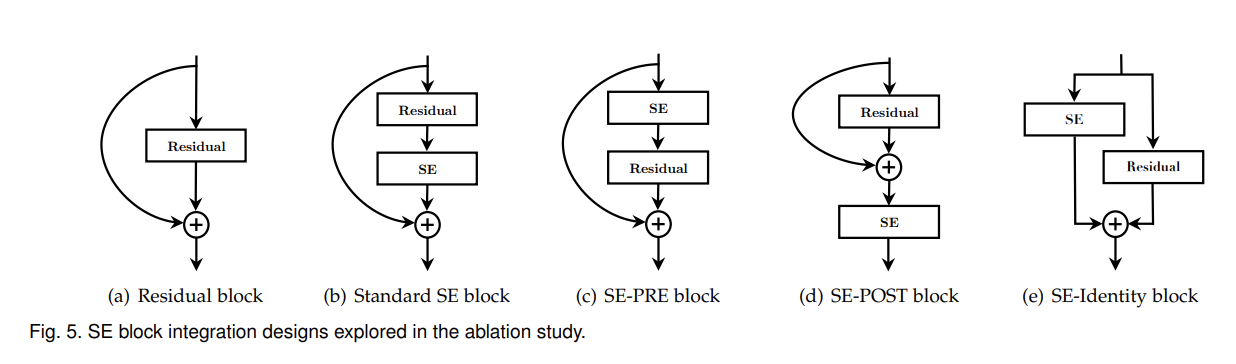
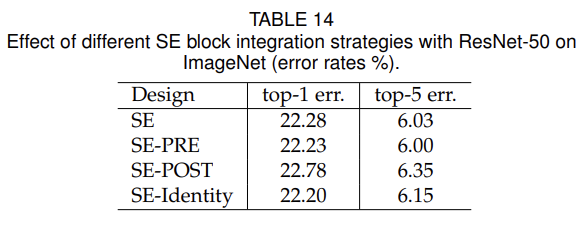
또 SE block을 Residual block에 끼워넣을 때 그 위치가 어디있느냐에 따라 성능이 어떻게 달라지는지도 실험했다. 결과는 Table 14와 같다. SE-PRE, SE-Identity, SE block은 비슷하게 성능이 좋았고 SE-POST block는 성능이 약간 떨어졌다. Fig 5처럼 SE block을 Residual block 밖에 넣는 게 아니라 안에도 (3x3 filter 사이에) 끼워넣어서 실험해 봤는데, 리뷰에선 생략하겠다.
Strengths
- squeeze의 성능이 좋은 이유에 대한 수학적 기반/설명이 부족한 걸 인정하고 대신 경험적으로, 실험으로 squeeze의 효과를 보였다. pooling operation을 없애고 2개 FC layer를 상응하는 1x1 convolutions로 대체하여 'NoSqueeze'와 squeeze를 비교했다.
- 기존의 network에 끼워넣거나 교체하는 식으로 호환가능하여 적용이 유연하다는 장점이 있다.
- ablation study가 흥미로웠다.
