이번 논문은 meta의 SONAR 논문으로, 직전에 리뷰한 LCM의 이전 연구이다. LCM 기능에 SONAR이 핵심적인 듯해서 더 자세히 알아보려고 읽게 되었다.
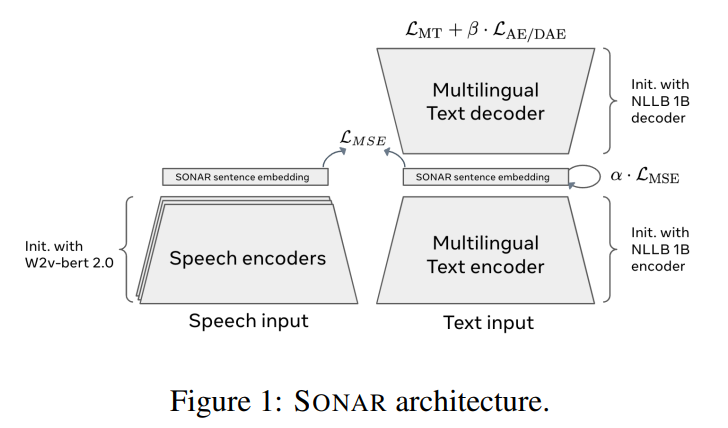
논문의 포인트는 encoder-decoder 형식 text-text translator를 먼저 만들고, 그 fixed size embedding space와 일치하도록 speech encoder를 만드는 것이다(teacher-student approach). 임베딩 공간이 공유되니 학습되지 않은 언어 쌍에도 zero-shot 번역이 가능하다. single encoder, decoder가 200개 언어를 다룰 수 있다.
1. Abstract
SONAR는 multilingual, multimodal fixed-size sentence embedding space다.
200개 언어를 다루는 논문의 single text encoder는 LASER3, LabSE 같은 기존 sentence embeddings보다 xsim, xsim++ multilingual similarity search tasks에서 뛰어나다.
speech segments도 (speech transcription data에 teacher-student setting으로 학습된) language-specific speech encoders를 사용해 같은 SONAR embedding space로 embed할 수 있다.
200개 언어의 text decoder를 제공해 text-to-text, speech-to-text machine translation이 가능하다.
2. Introduction
multilingual fixed-size sentence representations을 만들고자 한다.
기존에는 Encoder-only approaches, Encoder-decoder approaches, Teacher-student approaches가 있다. Teacher-student 방식은 이미 존재하는 sententce embedding space를 가지고(teacher) 새로운 언어에 대한(student) encoder를 학습시키겠다는 것이다. 이 방식으로 text-only multilingual sentence embedding을 speech modality로 확장할 수도 있다.
논문은 encoder-decoder 방식으로 text data에 sentence embedding을 만들고, 거기에 teacher-student 방식을 사용해 같은 공간에 speech encoder를 학습한다.
논문의 기여는 이렇다.

3. Related work
- Multilingual sentence representations
-variable-length representations of sentences, learning high-level contextual representations for each sub-word like multilingual BERT (Devlin et al., 2018) or XLM-R (Conneau et al., 2020).
- fixed-size sentence representations by integrating sentence-level objectives in the training. sentence-BERT (Reimers and Gurevych, 2019)
- Bitexts can also be used in other ways to train multilingual sentence embedding spaces. LASER (Artetxe and Schwenk, 2019)
- Joint speech/text sentence representations
-unsupervised representation learning for monolingual (Baevski et al., 2020) and multilingual speech (Babu et al., 2021), with recently w2v-bert (Chung et al., 2021) that combines contrastive learning and masked language modeling to learn selfsupervised representations from speech.
- multilingual and multimodal (speech/text) pre-training methods, including mSLAM (Bapna et al., 2022)
-Duquenne et al. (2021), followed by Khurana et al. (2022), introduced multilingual and multimodal sentence embeddings, extending a pre-existing multilingual text sentence embedding space to the speech modality with a distillation approach
4. Methodology
- Multilingual sentence representations for text
bidirectional LSTM을 사용하는 LASER와 달리 SONAR는 pre-trained MT model weights로 initialize된 Transformer encoder-decoder를 사용한다. 그러나 standard sequence-to-sequence architectures와 달리 문장 전체를 표현하는 single vector bottleneck를 통과하고 token-level cross-attention을 사용하지 않는다. encoder의 token-level outputs을 pooling하여 fixed-size representation을 계산한다. 그래서 decoder는 가변 길이 sequence output이 아닌 single vector를 attend하면 된다. pooling은 mean, max 등을 사용할 수 있다. 또 LASER와 달리 MT objective뿐만 아니라 여러 objective의 조합을 실험했다.
- Translation objective
LASER를 따라 encoder-decoder architecture를 translation objective로 학습할 때 parallel data를 사용했다. 즉 triplet of translation x, y, z를 데이터로 사용하는데, 같은 의미지만 서로 다른 언어인 문장 x, y를 인코딩해서 영어 문장 z로 디코딩해야하는 것이다. 이때 embedding space 상에서 x, y가 가까우면 decoder가 쉽게 번역할 수 있다. 이렇게 번역이 비슷하게 encoding되는 식으로 translation objective가 (좋은 의미에서) local minima에 도달할 수 있는데, 문제는 Translation objective 만으로는 좋은 local minimum에 도달한다는 보장이 없다는 것이다. 이러면 embedding space 상에서는 먼데 decode하면 같은 문장으로 번역되는 나쁜 경우가 생길 수 있다. 이를 완화하기 위해 LASER 논문이 사용한 shallow decoder를 사용하는데, deep decoder는 embedding이 멀어도 같은 문장으로 번역할 수 있지만 shallow decoder는 두 embedding이 가까워야 같은 문장으로 번역 가능하기 때문이다.
- Auto-encoding and denoising auto-encoding objective
이 objective는 input의 fine-grained details을 encode하게 해주지만, 이 자체만으로는 문장의 semantic representation을 배우지 못한다. 또 이 objective는 translation objective보다 훨씬 쉬워서 두 objective를 조합하기 어렵게 한다. 이를 완화하기 위해 Liu et al. (2020)은 denoising auto-encoding task를 도입한다.
- MSE loss objective in the sentence embedding space
Teacher-student approaches의 기존 연구에 따르면 번역이 같은 문장이 embedding space 상에서 MSE가 작게 하는 게 잘 작동한다. 하지만 pre-existing teacher embedding space를 freeze하지 않으면 모든 input이 동일한 임베딩으로 매핑되는 collapse 문제가 발생하게 된다. 하지만 MSE loss를 translation objective나 denoising auto-encoding objective와 결합하면 collapse를 방지할 수 있다.
- Decoder finetuning
Duquenne et al. (2022b)는 existing sentence embedding space(LASER)에 deep decoder를 학습시키는 게 translation, auto-encoding 성능을 향상시킴을 보였다. 이런 decoder는 existing embedding space를 변화시키지 않으면서 디코딩 성능만 향상시킬 수 있다. 이는 zero-shot (possibly cross-modal) translation에 유용하다.
논문은 random interpolation decoding이라는 decoder fine-tuning 방법을 소개한다. encoder weight을 freeze한 후 decoder weight만 fine-tune한다. bitext x, y를 인코딩한 후 x, y 사이 random interpolation으로 z를 랜덤하게 뽑아 z를 y로 decode하도록 학습한다. 이는 translation와 auto-encoding tasks의 continous combintaion이라고 볼 수 있다.
- Multilingual sentence representations for speech
Duquenne et al. (2021)은 multilingual speech에 대한 첫번째 semantic sentence embedding을 소개했다. 그들의 방식은 teacher-student approach를 사용한다. 논문은 앞서 학습한 text sentence embedding space를 teacher로 삼아 동일한 방식을 적용한다. transcription sentence embeddings와 trained speech sentence embeddings의 MSE loss를 최소화한다. speech encoder training은 w2v-bert pretrained model로 초기화한다.
5. Evaluations & Experiments
- Evaluations on text
FLORES-200 devtest set에 평가한다.
xsim : Cross-lingual similarity search, language 간 sentence embeddine cosine similarity를 평가한다.
xsim++ : more semantically challenging similarity search task (Chen et al., 2023). hard negative examples로 augment.
Translation tasks : spBLEU (flores200) scores와 COMET scores를 측정. 얼마나 많은 정보가 임베딩에 인코딩되는지 측정. 그러나 디코더가 정보를 임베딩 자체에서가 아닌 자체적으로 복구했을 가능성에 유의해야함.
Auto-encoding task : 임베딩을 동일한 언어로 decode.
- Evaluations on speech
FLEURS test set (Conneau et al., 2023)에 평가한다.
xsim for speech : Duquenne et al. (2021)를 따라 FLEURS speech translation test set (Conneau et al., 2023)에 cross-modal, -lingual similarity search를 측정.
xsim++ for speech
Zero-shot speech-to-text translation : Duquenne et al. (2022b)를 따라 inference 시 speech student encoders는 text decoders와 결합될 수 있다. speech encoder는 ASR data에만 학습됐고 SONAR text decoder는 text에만 학습됐으니 둘을 연결시키는 건 zero-shot speech-to-text translation이라 볼 수 있다.
Zero-shot Automatic Speech Recognition : speech recognition을 수행하기 위해 speech embeddings을 동일한 언어로 decode한다.
- Text 실험
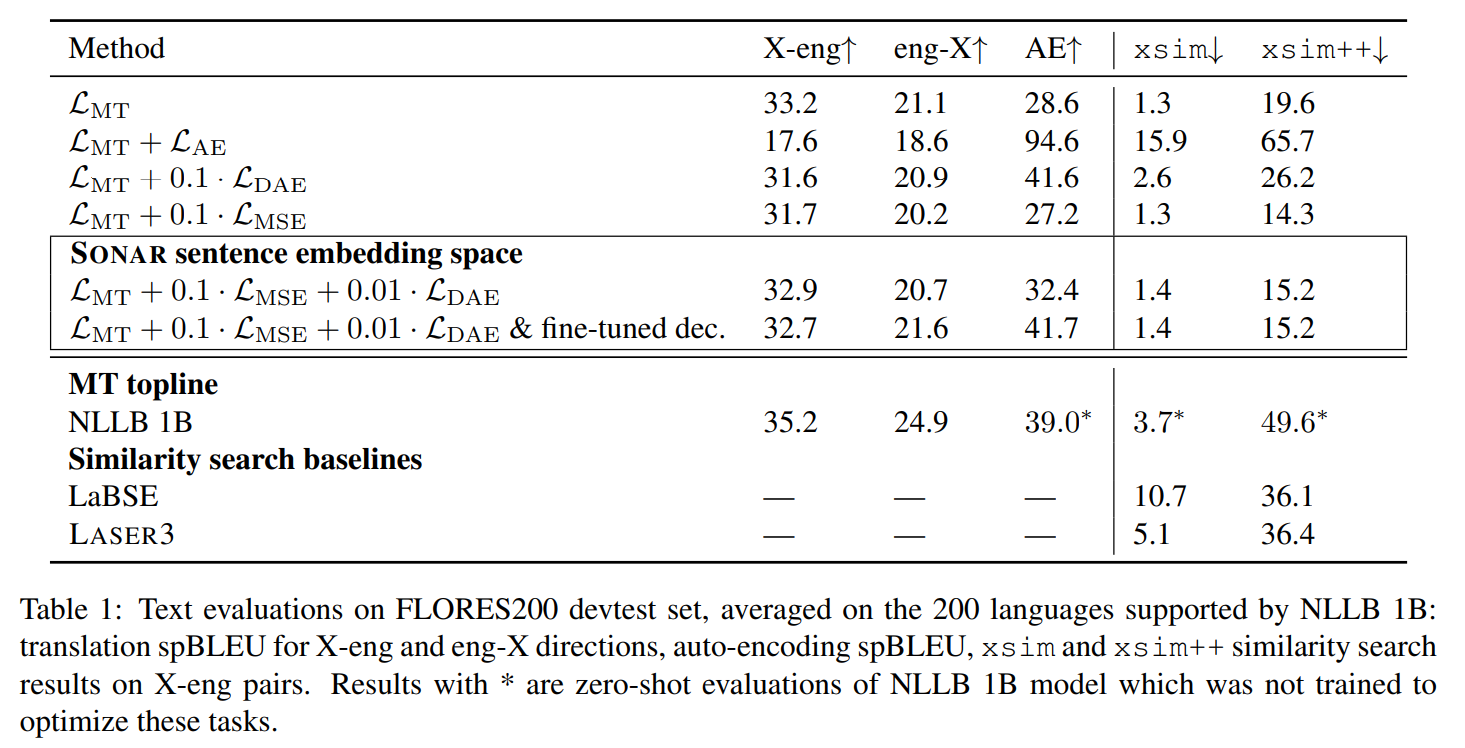
Base Model: NLLB 1B dense model
- 24층 Transformer encoder + 24층 Transformer decoder
- 이미 200개 언어의 번역 데이터로 사전훈련됨
- Full cross-attention 방식으로 훈련됨 (표준 seq2seq 방식)
encoder output에 pooling하여 fixed size SONAR embedding을 만들며, mean pooling, max pooling, EOS pooling이 있다. EOS pooling은 문장 마지막에 있는 EOS special token의 output representation을 사용하는 것이다. mean, EOS 방식과 달리 max는 결과 범위가 NLLB training 때와 달라서 초기 실험에서 결과가 나빴다. 또 EOS pooling은 training 중 불안정해서 이후 실험에는 mean pooling을 사용했다.
앞서 언급했듯 objective는 y translation objective (MT), auto-encoding objective (AE), denoising auto-encoding objective (DAE), Mean Squared Error loss (MSE)를 섞어 실험했다.
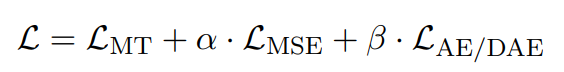
Table 1 결과를 보면 translation objective only 경우, fixed size representation이란 병목에도 불구하고 좋은 translation 성능을 보인다. xsim 점수가 기존 LASER3, LaBSE 대비 크게 향상됐다. 그러나 Auto-encoding 성능이 NLLB 1B 대비 크게 낮은데, 이는 full cross-attention을 가진 sequence-to-sequence architecture의 inductive bias 때문으로 추측된다.
auto-encoding objectives도 추가할 경우 학습이 빨랐고 auto-encoding 성능은 대폭 향상됐는데, 이는 fixed size representation 안에 많은 정보가 효과적으로 저장될 수 있으며 이 bottleneck이 hard limitation이 아님을 의미한다. 그러나 X-eng 방향 번역 성능이 크게 감소했고(-15,6 BLEU) xsim, xsim++도 악화해 더이상 language-agnostic representation을 학습하지 않았다. AE 난이도가 쉬워서 모델이 편향된 것이다.
이를 완화하기 위해 denoising auto-encoding criterion으로 바꿨고, objective를 0.1배로 scale down했다. 이는 translation task의 성능 감소를 완화하면서 auto-encoding을 늘렸다. 하지만 이는 xsim, xsim++ 점수를 여전히 크게 악화시켰다. 이는 auto-encoding이 sentence embedding space에서 서로 다른 언어가 distinct representations을 학습하게 함을 보여준다.
번역들이 embedding space 상에서 가깝도록 명시적으로 제약하기 위해 auxiliary MSE loss를 추가했다. 이는 translation과 auto-encoding tasks 모두에서 decoding 성능을 낮췄다. 그러나 only translation objective 경우에 비해 xsim++ 점수는 상당히 개선됐다.
이 결과를 바탕으로 translation loss, auxiliary MSE loss, denoising auto-encoding loss를 결합했다. denoising auto-encoding loss는 downscale됐다. MSE loss에 denoising auto-encoding을 추가하니 xsim++ 점수가 살짝 악화됐다. denoising auto-encoding 계수를 증가시키면 점수가 더 악화돼서 scaling factor는 0.01로 고정했다. 또 현재 loss 조합은 MT, MSE loss를 사용할 때보다 translation task 성능이 향상됐다. 이는 denoising auto-encoding objective 덕분에 MSE loss로 발생할 수 있는 collapse를 완화했기 때문으로 추측된다. 이 조합이 sentence embedding space organization (xsim, xsim++ scores)와 decoding performance (translation, auto-encoding evaluations)에서 최고의 조합으로 생각된다.

SONAR는 기존 SOTA인 LaBSE, LASER3의 성능을 뛰어넘는다.
그 다음, decoding 성능을 높이기 위해 embedding space, multilingual encoder는 freeze하고 decoder만 fine-tuning했다. 앞서 설명한 random interpolation decoding 방법을 썼고, 그 결과 X-eng 방향은 translation 결과가 비슷했지만 eng-X 방향은 +0.9BLEU 점수 상향이 있었다. 그리고 auto-encoding 성능은 9.3 BLEU 향상됐다.
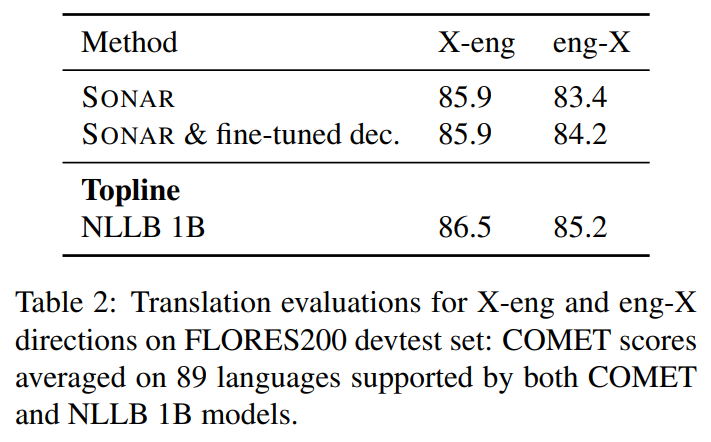
번역 품질을 평가하는 데 BLEU 점수만으로는 부족할 수 있어 COMET 점수도 실험했으며 NLLB 1B 모델과 1점 차이밖에 나지 않았다.
- Speech 실험
teacher-student approch로 speech로 확장하는 것은 먼저 5개 언어 English (eng), Spanish (spa), French (fra), Russian (rus) and Swahili (swh)에 실험한 후 37개 언어로 확장했다.
speech encoder는 pre-trained w2v-bert 600 million parameter model로 초기화했고 Common Voice 12 ASR training set (Ardila et al., 2019)에 학습했다. English speech encoder는 Must-C (Di Gangi et al., 2019), Voxpopuli (Wang et al., 2021), Librispeech (Panayotov et al., 2015)의 ASR training data도 사용했다. mean, max, attention pooling을 실험했는데 attention-pooling에서 최고의 결과가 나왔다. attention-pooling은 speech encoder output에 cross-attention을 하는 3 layer transformer decoder로 수행되어 single vector speech sentence embedding을 만든다.
LASER3 MSE text encoder를 teacher 삼아 학습한 speech encoder를 SONAR speech encoder와 비교할 baseline으로 삼았다.
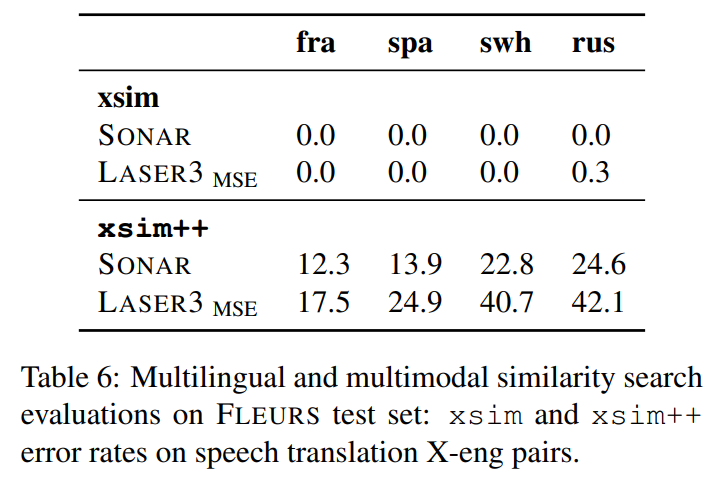
xsim 점수는 전부 0으로 saturate해서 분석에 유용하지 않았고, hard negative가 많은 xsim++에선 SONAR을 teacher 삼을 때가 LASER을 teachr 삼을 때보다 xsim++ 점수가 낮았다.
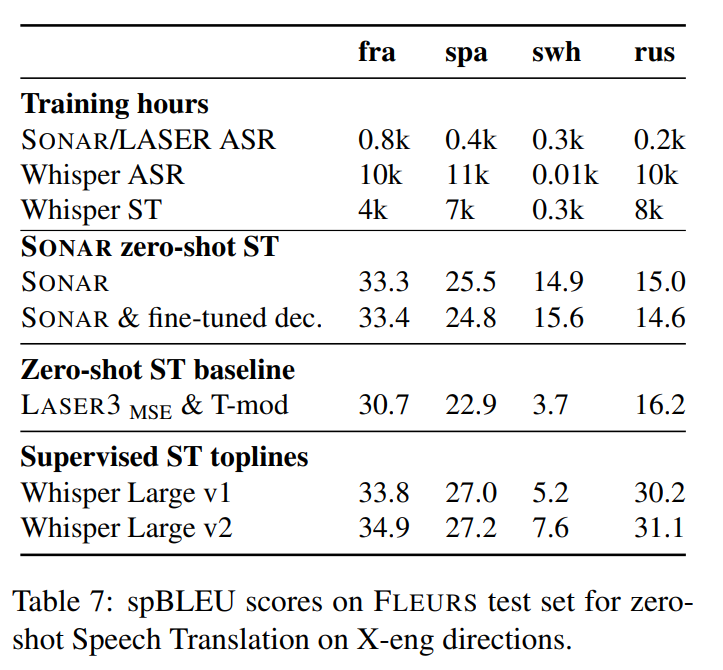
speech sentence embedding에 SONAR text decoder를 사용해 zero-shot speech-to-text translation을 실험했다. 더 많은 데이터로 supervised 학습된 SOTA speech-to-text translation과도 비교했다. 실험 결과, LASER baseline에 비해 BLEU 점수가 French, Spanish, Swahili에서 크게 상향됐고 Russian, English는 살짝 낮아졌다. 또 high resource language인 French, Spanish에서 성능이 Whisper Large v1 supervised 결과와 비슷했다. Swahili에선 크게 뛰어넘었다. 즉, 데이터가 많은 고자원 언어에선 supervised와 경쟁적이고 저자원 언어에선 더 잘 학습한다(학습 효율이 좋다).
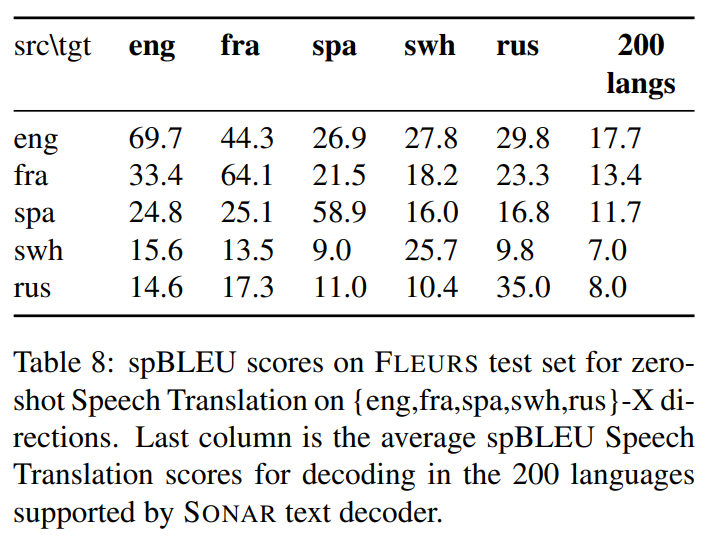
zero shot 번역을 200개 언어로 확장했을 때도 성능이 좋았다.
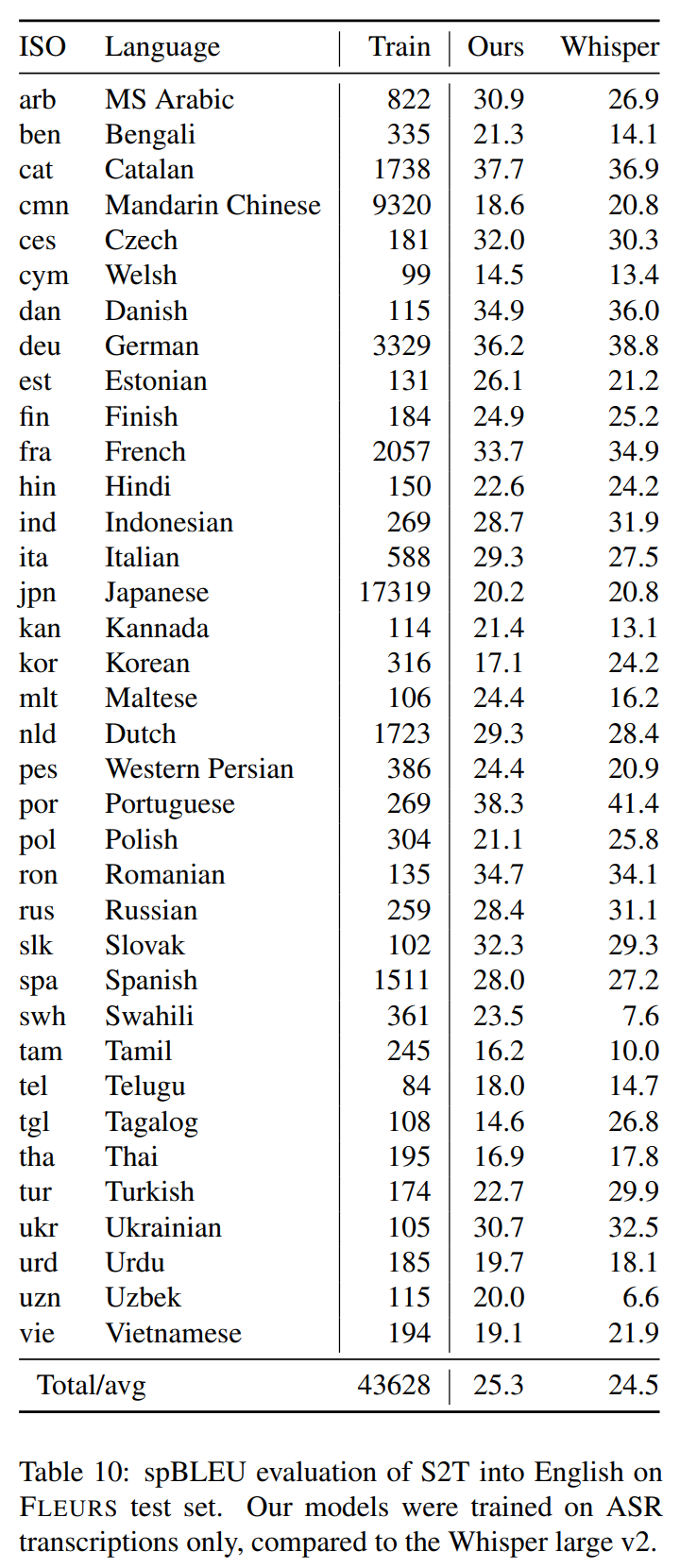
37개 언어로 확장했고, SOTA인 Whisper v2 large (Radford et al., 2022)와 성능이 경쟁적이다. 평균 BLEU 점수는 SONAR가 더 높고 고자원 언어는 supervised 방식인 Whisper가 더 높다.
6. Discussion
-
encoder, decoder 사이 fixe-size bottleneck에도 불구하고 auto-encoding task에 잘 작동함을 보면 fixed-size representation이 hard limitation이 아니며 많은 정보가 단일 벡터에 저장됨을 알 수 있다.
-
translation objective는 language-agnostic representations를 만드는데 알맞다. 동시에 인코더가 sentence embedding에 디코딩하기 충분한 정보를 담을 수 있다.
-
MSE loss는 embedding space에서 여러 언어들이 정렬되도록 명시적으로 장려해 더 좋은 language-agnostic representations을 만든다.
-
denoising auto-encoding은 MSE loss와 결합하여 decoding task 성능을 향상시킨다. 하지만 과도하면 language-agnostic 특성을 해친다.
-
teacher-student 방식으로 speech modality를 확장하는 방법이 효과적임이 또 한번 검증되었다.
7. 개인적인 생각
-
supervised 방식과 경쟁적인 성능을 내니 확실히 효과적인 방법이라고 느꼈다.
-
text로 space를 먼저 만들고, teacher-student 방식으로 modality를 확장하는 방법이 인상적이다. 그런데 이 방식은 multilingual도 똑같이 적용할 수 있지 않나? 고자원 언어인 영어를 가지고 먼저 embedding space 만들고(혹은 영어 + 다른 고자원 언어 1개) 언어를 하나씩 추가하면 되는 거 아닌가? 그러면 논문에서 언급된 같은 의미라도 language마다 따로(멀게) embed되는 문제도 자연스럽게 해결되는 것 같은데. 물론 학습이 더 길어진다던지, 언어마다의 밸런싱 문제라던지 부작용은 있을 것 같다.
-
encoder output에 pooling으로 강제로 fixed size embedding 만드는거 너무 naive한 방식 아닌가? 이게 가장 마음에 안 들었다. output에 인코딩된 정보를 손상입히는 짓 아닌가?
-
random interpolation decoding 테크닉이 흥미롭다.
-
auto encoding이 너무 쉬워서 모델이 편향되는 결과가 놀라웠다. 난이도가 서로 다른 여러 objective를 섞을 때 균형이 중요하다는 것을 알았다. 문자 그대로 복사하는 게 아닌 denoising하는 auto encoding이란 목표로 대체해서 문제를 완화할 수 있는 것도 배웠다.
