오늘 리뷰할 논문은 마이크로소프트의 Oscar 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks 논문 리뷰
- 초 간단 논문리뷰| OSCAR (Object-Semantics Aligned Pre-training for Vision-Language Tasks)
- [논문리뷰] Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
Summary
image-text pairs에 cross-modal representation을 배우는 large-scale pre-training이 인기다. 기존 방법들은 단순히 image region features와 text features을 concatenate해서 input으로 삼고 image-text semantic alignments을 배우기 위해 self-attention을 억지로(brute force manner) 사용한다. 그러나 명시적인 alignment 정보가 부족해 weakly-supervised learning task가 되고, 흔히 visual regions가 over-sampled, noisy, ambiguous한 문제가 있다.

논문은 alignment의 학습을 상당히 쉽게 해주기 위해 이미지 내에 감지된 object tags를 anchor points로 사용하는 Oscar를 제안한다. Oscar는 training sample을 triple로 정의하며, 각 triple이 word sequence, set of object tags, set of image region features로 구성된다. Oscar는 두드러진 사물들이(salient objects) 정확하게 감지될 수 있으며 보통 paired text에 언급된다는 점에 착안한다.
논문의 기여는 다음과 같다.
- V+L understanding과 generation tasks을 위한 generic image-text representations을 학습하는 Oscar을 소개한다.
- 여러 V+L benchmarks에 SOTA를 달성한다.
- cross-modal representation learning와 downstream tasks을 위해 object tags를 anchor points로 사용하는 것의 효과에 대한 통찰을 제공하기 위해 광범위한 실험과 분석을 한다.
기존 VLP 방법들은 두 가지 문제를 겪는다.
- Ambiguity
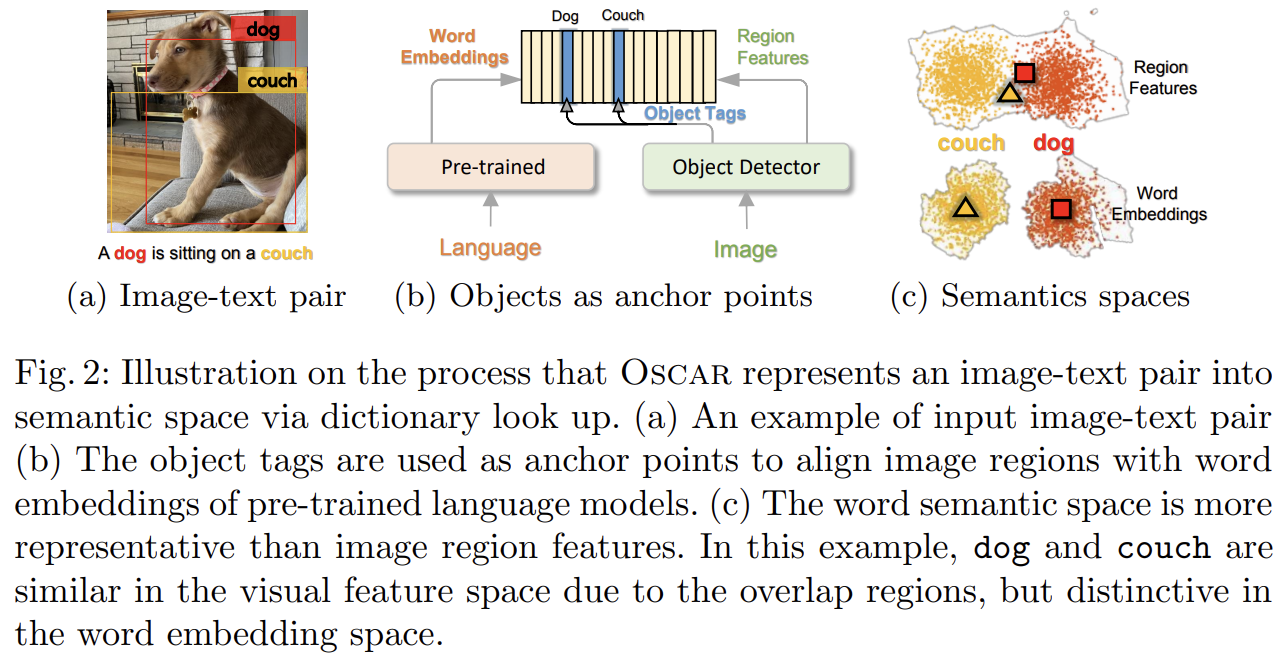
visual region features는 주로 Faster R-CNN object detectors를 통해 over-sampled regions에서 추출된다. 이는 불가피하게 서로 다른 positions의 image regions 사이 overlap을 발생시킨다. 이는 extracted visual embeddings에 대해 애매성을 만든다. 예를 들어 Fig 2(a)에서 dog와 couch의 region이 매우 겹치기 때문에 둘을 구분하기 쉽지 않다.
- Lack of grounding
image 내 regions/objects와 text 내 words/phrases 사이 명시적으로 label된 alignments가 없기 때문에 VLP는 본질적으로 weakly-supervised learning problem이다.

논문은 semantic level에서 channel-invariant (=modality-invariant) factors을 포착하는 representation을 학습하는 Oscar을 제안한다. Fig 3에서 볼 수 있듯 Oscar는 input image-text pairs가 표현되는 방식과 pre-training objective에서 기존 VLP 방식들과 다르다.
- Input
Oscar은 각 input image-text pair을 Word-Tag-Image triple (w, q, v)로 표현한다. w는 text의 word embeddings의 sequence고 q는 image에서 감지된, text 내의 object tags의 word embedding sequence고 v는 image의 region vectors의 집합이다.
기존 VLP 방식은 input 쌍을 (w, v)로 표현하는데 Oscar은 image-text alignment 학습을 쉽게 하기 위해 q를 anchor points로 도입하는 것이다. (둘 다 text 내에 있는) q와 w 사이 alignment은 (Oscar에서 VLP를 위한 initialization으로 사용되는) pretrained BERT models을 사용해 상대적으로 식별이 쉽기 때문에, text 내에서 의미적으로 연관된 words에 query되었을 때 object tags가 감지된 image regions는 다른 regions보다 attention weight가 높다.
구체적으로 v와 q는 다음과 같이 생성된다. (보통 over-sampled되고 noisy한) K regions of objects를 가진 image가 주어졌을 때, Faster R-CNN은 각 region의 visual semantics를 (v', z)로 추출한다. region feature 는 P-dimensional vector고(즉 P=2048), region position z는 R-dimensional vector다(즉 R=4 또는 6). position-sensitive region feature vector를 형성하기 위해 v'와 z를 concatenate한다. 이는 word embeddings와 같은 차원으로 맞추기 위해 linear projection을 사용해 v로 변환된다. 한편 동일한 Faster R-CNN을 사용해 set of high precision object tags을 감지한다. q는 그 object tags의 word embeddings의 sequence다.
- Pre-Training Objective
Oscar input은 다음과 같은 두 관점으로 볼 수 있다.
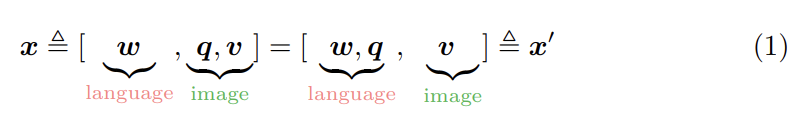
x는 text와 image 사이 representation을 구분하기 위한 modality view고, x'는 (input이 표현되는) 서로 다른 두 semantic spaces를 구분하기 위한 dictionary view다. 이 two-view perspective은 새로운 pre-training objective를 디자인하게 해준다.
- Dictionary View: Masked Token Loss
다른 dictionaries의 사용은 다른 sub-sequences를 표현하기 위해 활용되는 semantic spaces를 결정한다. 구체적으로 object tags and word tokens는 같은 linguistic semantic space에 공유하며 image region features는 visual semantic space에 놓인다. discrete token sequence을 로 정의하고 pretrainig을 위해 Masked Token Loss (MTL)을 적용한다. 각 iteration마다 h 내의 각 input token을 15% 확률로 랜덤하게 mask하고 masked된 를 special token [MASK]로 대체한다. 목표는 주변 tokens 와 모든 image features v로 negative log likelihood를 최소화함으로써 masked tokens을 예측하는 것이다. 이는 BERT의 MLM과 유사하다.
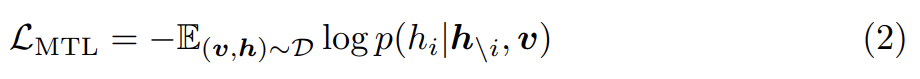
- Modality View: Contrastive Loss
각 input triple에 대해 image modality를 표현하기 위해 를 group하고 w를 language modality로 고려한다. 그 다음 50% 확률로 q를 (dataset D에서 랜덤으로 sample한) 다른 tag sequence로 대체함으로써 set of “polluted” image representations을 sample한다. special token [CLS]에 대한 encoder output은 (h', v)의 fused vision-language representation이므로, pair가 original image representation (y=1)을 가지는지 polluted ones (y=0)을 가지는지 예측하기 위해 그 꼭대기에 fully-connected (FC) layer을 binary classifier f(.)로 적용한다. contrastive loss는 다음과 같이 정의된다.
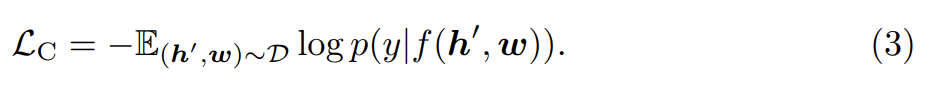
cross-modal pre-training 중에는 BERT의 word embedding space을 adjust하기 위해 object tags을 proxy of images로 활용한다. 전체 pre-training objective는 다음과 같다.
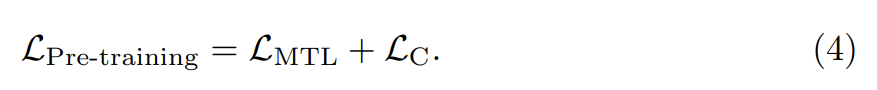
pre-training corpus는 기존 V+L datasets에 기반하며 COCO [21], Conceptual Captions (CC) [31], SBU captions [26], flicker30k [44], GQA [13] 등을 포함한다. unique image set은 4.1 million이고 corpus는 6.5 million text-tag-image triple로 구성된다.
두 모델 와 을 만드는데 각각 BERT base (H = 768)와 large (H = 1024)의 parameter 로 초기화된 것이다. BERT처럼 image region features가 input embedding과 같은 크기를 갖게 하기 위해 matrix W를 통한 linear projection으로 position-sensitive region features를 변환한다. trainable parameters는 다. AdamW Optimizer을 사용한다. (이하 implementation detail 생략)
5 understanding tasks와 2 generation tasks를 포함한 7개의 V+L task에 모델을 적용한다. Image-Text Retrieval, Image Captioning, Novel Object Captioning (NoCaps), VQA, GQA, Natural Language Visual Reasoning for Real (NLVR2)이다. 설명은 생략한다.
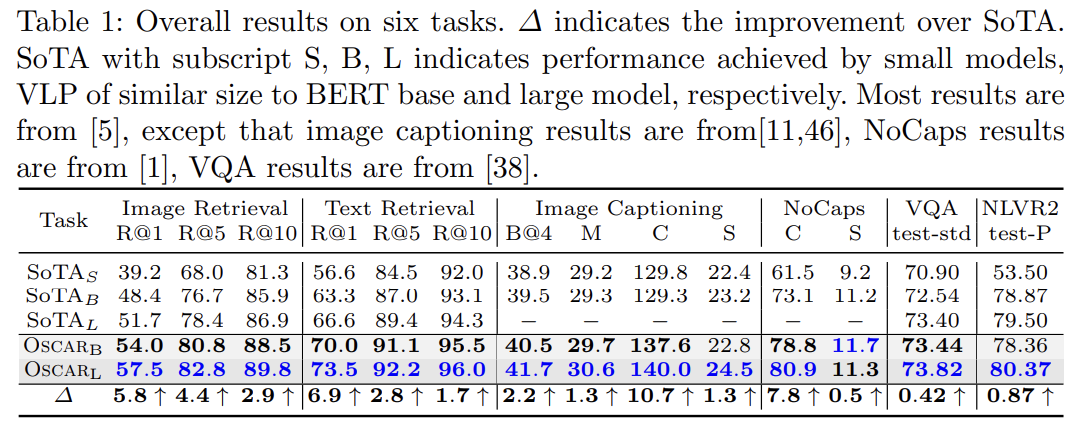
parameter efficiency를 고려하기 위해 Oscar를 세 종류 SOTA와 비교한다. 1. 는 Transformer-based VLP models 이전의 small models로 달성된 best performance고 2. 는 BERT base와 비슷한 크기의 VLP models로 달성된 best performance고 3. 은 BERT large와 비슷한 크기의 모델로 달성된 best performance다. 저자들이 아는 한 UNITER가 BERT large size의 유일한 모델이다.
Tab 1에서 볼 수 있듯 Oscar base model은 대부분 task에서 이전의 large model보다 성능이 좋다. 이는 object tags를 anchor points로 사용한 것이 image와 text 사이 semantic alignments 학습을 쉽게 하기 때문에 Oscar가 몹시 parameter-efficient함을 보여준다.
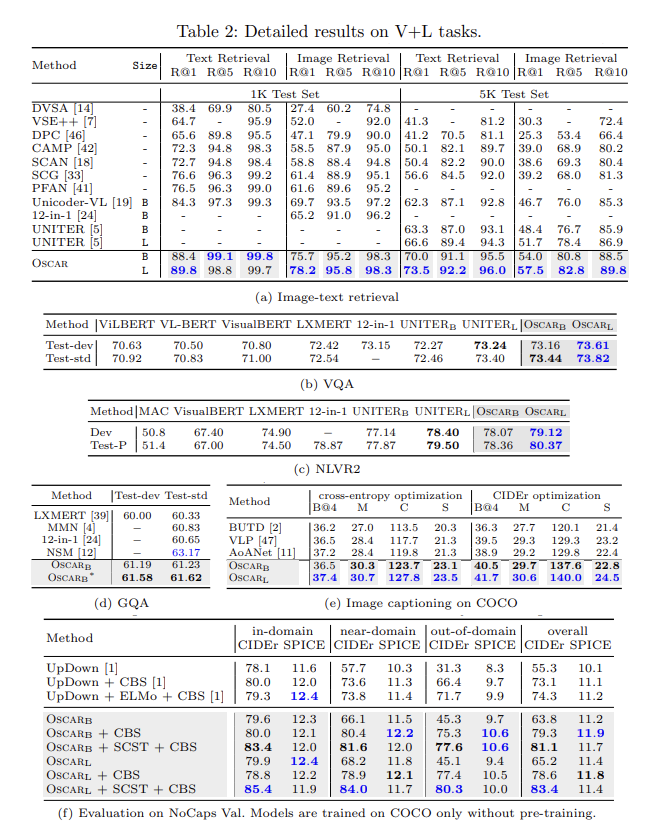
(자세한 설명 생략)
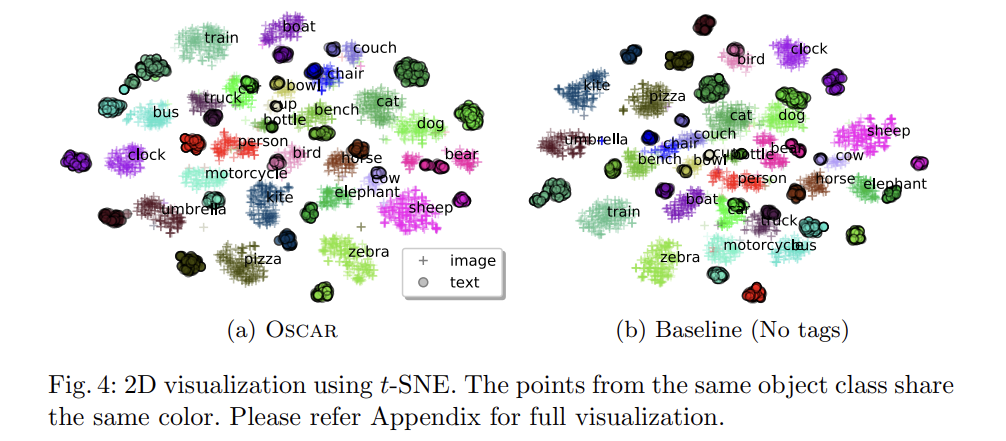
질적 평가도 한다. t-SNE를 사용해 2D map에 COCO test set의 learned semantic feature space of image-text pairs를 시각화한다. 각 image region과 word token에 대해 model을 통과시킨 후 last layer output을 feature로 사용한다. tags를 가진 pertrained model과 가지지 않는 model을 비교한다. Fig 4는 몇 가지 흥미로운 사실을 보여준다.
- Intra-class
object tags의 도움으로 두 modalities 간 동일한 사물의 거리가 상당히 감소됐다.
- Inter-class
tags를 추가한 후 관련된 semantics의 object classes가 (여전히 구분가능하지만) 더 가까워졌다. 이는 alignment learning에서 object tags의 중요성을 입증한다.

Fig 5에서 다양한 model로 생성한 caption도 비교한다. baseline은 object tag가 없는 VLP다. Oscar가 더 세세한 설명을 생성함을 볼 수 있다.
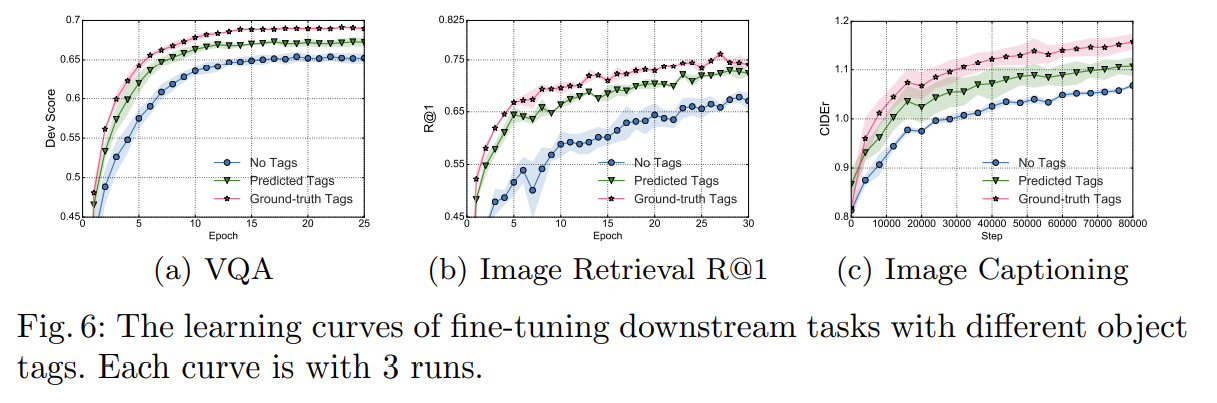
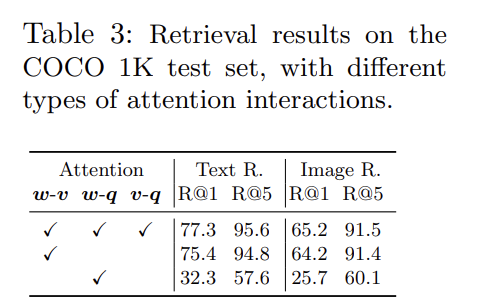
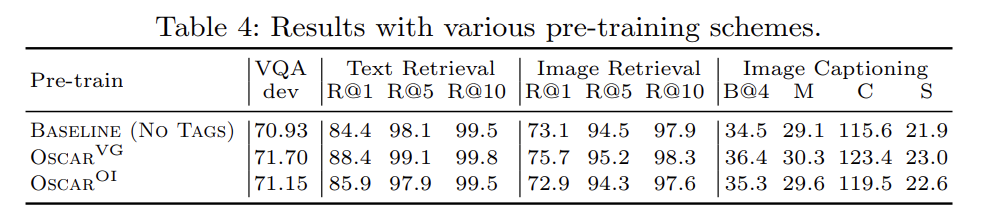
3가지 Ablation study도 한다. 설명은 생략한다.
Strengths
- object tags를 anchor points로 삼아 alignment 난이도를 쉽게 함으로써 더 좋은 representation을 학습할 수 있었다.
- (두드러지지는 않지만) parameter-efficient하다.
- architecture 변화가 크게 없는 것 같아서 다른 모델에서도 쉽게 적용할 수 있는 방법 같다.
object tag를 제공한 게 일종의 modality를 늘려준 셈이니 당연히 학습을 쉽게 만들어주는 건 맞지만 궁극적인 방법은 아니라고 생각했다.
논문 본론에는 계속 7 VLP tasks라고 하는데 결론에서는 6 VLP tasks라고 정정한다. image retrieval + text retrieval을 따로 치는 것 같다.
