오늘 리뷰할 논문은 ActBERT 논문이다.
문법적으로 이상한 문장이 좀 보이는데 아무래도 오타 같다.
Summary
논문은 unlabeled data에서 joint video-text representations를 self-supervised learning으로 학습하는 ActBERT를 소개한다. 첫째로 linguistic texts와 local regional objects 사이 상호작용을 촉진시키기 위해 global action information을 leverage한다. 이는 detailed visual & text relation modeling을 위해 video sequences와 text descriptions의 쌍에서부터 global & local visual clues을 알아낸다. 둘째로 세 종류(source)의 정보, global actions, local regional objects, linguistic descriptions를 encode하기 위해 TaNgled Transformer block (TNT)을 도입한다. Global-local correspondences은 contextual information에서부터의 신중한 단서 추출(judicious clues extraction)을 통해 발견된다. 이는 joint video-text representation이 fine-grained objects와 global human intention을 잘 알아차리게 해준다. downstream video-and-language tasks, 즉 text-video clip retrieval, video captioning, video question answering, action segmentation, action step localization에 ActBERT의 일반화 능력을 검증하고 SOTA를 달성한다.
논문은 narrated instructional videos을 기반으로 video-text 관계를 이용하는데(exploit) video는 off-the-shelf automatic speech recognition (ASR) models으로 aligned text를 감지한다.
ActBERT에서 global, local visual signals은 둘다 semantic stream과 상호작용한다. ActBERT는 profound contextual information을 leverage하고 video-text joint modeling을 위해 fine-grained relations을 이용한다.
첫째로 ActBERT는 global actions, local regional objects, text descriptions을 joint framework에 통합한다. “cut”, “rotate”, “slice” 같은 action은 여러 video-related downstream tasks에 중요하다. human action의 인식은 motion understanding과 complex human intention reasoning에서 모델의 능력을 입증할 수 있다. pretrainig 중에 human action을 명시적으로 model할 수 있으면 이로울 것이다. Long-term action sequences는 instructional task에 대한 temporal dependencies을 제공한다. action clues은 중요하지만 action이 object와 동일하게 다루어진 기존의 self-supervised video-text training에서 크게 무시되었다. human action을 model하기 위해 논문은 먼저 text descriptions에서 동사(verbs)를 추출하고 original dataset에서 action classification dataset을 구축했다. 다음, action labels을 예측하기 위해 3D convolution network이 훈련되었다. 네트워크에서 얻은 features은 action embedding으로 사용됐다. 이런 방식으로 clip-level actions이 표현되며 상응하는 action label이 삽입됐다. global action information 말고도 fine-grained visual cues을 제공하기 위해 local regional information도 통합한다. Object regions는 regional object feature, object position을 포함해 전체 scene에 대한 세세한 visual clues를 제공한다. language model은 language-and-visual alignment을 위해 regional information에서 득을 볼 수 있다.
둘째로 세 sources, 즉 global actions, local regional objects, linguistic tokens로부터의 features를 encode하기 위해 TaNgled Transformer block (TNT)을 도입한다. 기존 연구는 tranformer layer를 디자인할 때 두 modalities, 즉 image와 natural language부터의 fine-grained object information을 고려했다. ActBERT에서는 local regional features와 linguistic texts가 clip에서 일어나는 사건에 대한 세세한 descriptions을 제공한다. global action feature은 시계열(time-series)로 human intention과 contextual inferring에 대한 straightforward clue을 제공한다. 논문은 cross-modality feature 학습을 위해 이 세 sources부터 새로운 tangled transformer block을 디자인한다. 2 visual cues와 linguistic features 사이 상호작용을 강화하기 위해 각 modality를 encode하는 transformer block을 따로 사용한다. mutual cross-modal communication은 2 additional multi-head attention block을 가지고 나중에 향상된다(enhance). action feature은 상호작용을 촉진시킨다. action feature의 가이드 하에 visual information을 linguistic transformer에 주입하고 linguistic information을 visual transformer에 통합한다. tangled transformer은 target prediction을 용이하게 하기 위해 동적으로 신호를 선택한다.
또 ActBERT를 훈련하기 위해 4 surrogate tasks, 즉 masked language modeling with global and local visual cues, masked action classification, masked object classification, cross-modal matching을 디자인했다. pretrain된 ActBERT는 5 video-related downstream tasks, 즉 video captioning, action segmentation, text-video clip retrieval, action step localization, video question answering에 transfer되며 SOTA를 달성한다.
ActBERT는 4 종류 input elements을 받는다. actions, image regions, linguistic descriptions, special token이다. special token은 input을 서로 구분하기 위해 사용된다.
각 input sequence는 special token “[CLS]”로 시작하고 token “[SEP]”로 끝난다. [CLS] 다음에 linguistic description을 넣고 local regional features 뒤에 action inputs이 따른다. action features을 a1, . . . , aL로, region features을 r1, . . . , rM로, sequential text descriptions을 w1, . . . , wN로 표기한다. 전체 sequence는 다음과 같다. {[CLS], w1, . . . , wN , [SEP], a1, . . . , aL, [SEP], r1, . . . , rM, [SEP]}. 또한 [SEP]는 문장들 사이에도 삽입된다. 모델이 clip boundaries를 식별할 수 있도록 서로 다른 clip에서 온 regions 사이에도 [SEP]을 삽입한다. 각 input steps에 대해 final embedding feature은 4가지 다른 embeddings, 즉 position embedding, segment embedding, token embedding, visual feature embedding으로 구성된다. action features와 regional object features을 구분하기 위해 새 token을 몇 개(a few) 추가했다. visual & action information을 추출하기 위해 visual embedding이 도입된다. 다음과 같은 embeddings는 ActBERT의 final feautre이 되기 위해 합해진다.
- Position embedding
BERT를 따라 learnable position embedding을 sequence 내의 모든 input에 통합한다. self-attention이 order information을 고려하지 않기 때문에 position encoding은 sequence order이 중요할 때 sequence를 embed할 유연한 방법을 제공한다. 서로 다른 clips 속 actions에 대해서는 video clips 순서에 따라 position embeddings이 다르다. 같은 frame에서 추출된 regions에 대해서는 같은 position embedding을 사용한다. 같은 frame 내의 regions을 구분하기 위해 서로 다른 spatial positions에 대해 spatial position embedding을 고려한다. 세부사항은 이하 “Visual (action) embedding”에서 설명한다.
- Segment embedding
long-term video context modeling을 위해 multiple video clips를 고려한다. 각 video clip/video segment는 상응하는 segment embedding을 가진다. elements는, 즉 action inputs, regional object inputs, linguistic descriptions는 같은 video clip 내에서 같은 segment embedding을 가진다.
- Token embedding
각 단어는 30,000 vocabulary를 가진 WordPiece embeddings로 embed된다. 앞서 언급한 special token [CLS], [MASK], [SEP] 외에도 video frames에서 추출한 action features와 region features을 추출하기 위해 각각 [ACT]와 [REGION]을 도입한다. 모든 action inputs이 동일한 token embedding을 가져 inputs의 modality를 드러냄에 주의하라.
- Visual (action) embedding
action embedding을 얻는 절차를 생각해보자. 각 video clip에 대해 상응하는 descriptions에서 동사를 추출한다. 간단성을 위해 동사가 없는 clips은 제거한다. 그 다음 모든 추출한 동사들로 vocabulary를 구축한다. 그 후 각 video clip은 하나 이상의 category label을 가지게 된다. 이렇게 구축된 dataset에 3D convolutional neural network을 학습시킨다. 3D network로의 input은 additional temporal dimension을 포함하는 tensor다. CNN 꼭대기에 softmax classifier을 leverage한다. multiple labels을 가진 clips에 대해선 모든 labels의 점수 합이 1이 되도록 L1-norm을 가지고 one-hot label을 normalize한다. model이 학습된 후 global average pooling 이후 features을 추출해 action features로 삼는다.
regional object features을 얻기 위해선 bounding boxes와 상응하는 visual features를 pretrained object detection network에서 추출한다. ViLBERT와 비슷하게 COCO vocabulary 하에 categorical distribution을 추출하기 위해 pre-trained Faster R-CNN network을 활용한다. image region features은 visual & text relation modeling을 위해 세세한 visual information을 제공한다. 각 region에 대해 visual feature embeddings은 pre-trained network의 output layer 이전의 feature vectors다. ViLBERT를 따라 region locations를 5-D vector로 나타내기 위해 spatial position embeddings를 통합한다. 이 벡터는 4 box coordinates와 region 면적(area)의 비율(fraction)로 구성된다. 구체적으로는 로 표기하며 W는 frame width, H는 frame height, (x1, y1)와 (x2, y2)는 각각 top-left, bottom-right 좌표다. 그 다음 이 좌표는 visual feature의 차원에 맞도록 embed된다. final regional object feature은 spatial position embedding과 object detection feature의 합이다.
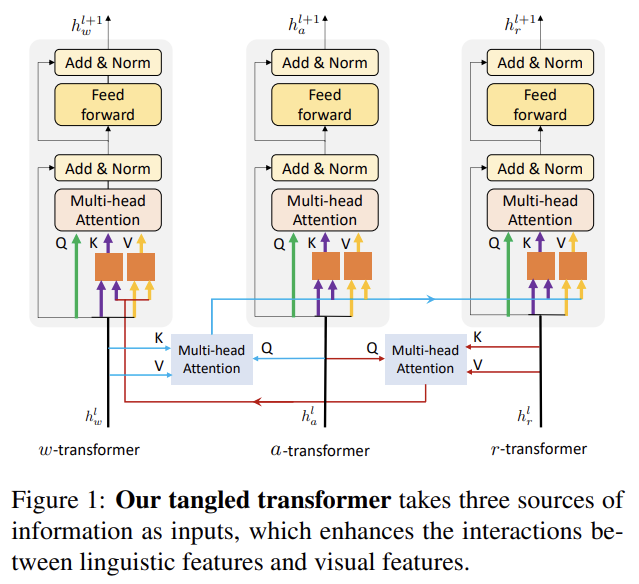
세 종류의 정보, 즉 action features, regional object features, linguistic features을 더 잘 encode하기 위해 TaNgled Transformer (TNT)을 디자인했다.
visual과 text features을 동등하게 다루는 transformer 하나만 사용하는 대신 논문의 tangled transformer은 각각 세 sources of features를 받는 세 개의 transformers로 구성된다. visual과 linguistic features 사이 상호작용을 강화하기 위해 visual information을 linguistic transformer에 주입하고 linguistic information을 visual transformers에 통합하는 방식을 제안한다. cross-modal interactions을 가지고 tangled transformer은 target prediction을 위해 동적으로 적절한 신호(judicious cues)를 선택할 수 있다.
transformer block l에서의, 각각 w-transfomer, a-transformer, r-transformer에 의해 처리되는 intermediate representations을 로 표기한다. 동일한 modality로부터의 standard multi-head attention encoding features뿐만 아니라 transformer blocks 간 상호작용을 강화하기 위해 다른 두 multi-head attention blocks도 leverage한다. 구체적으로는 상호작용을 촉진시키기 위해 를 활용한다. multi-head attention을 로 표기하며 Q는 query, K는 key, V는 value다. 와 에서 judicious cues를 attend하기 위해 query로 를 사용한다.
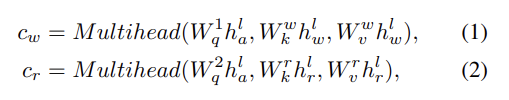
W는 learnable weights, c_w는 linguistic representations에서 온 blended feature, c_r은 regional object representation에서 온 guided feature이다. 그 다음 linear layer을 사용해 c_w에서 새로운 key-value pair을 생성한다. 생성된 쌍은 original a-transformer와 r-transformer에서 온 key-value pair과 함께 stack된다. 비슷하게 c_r에서 새 key-value pair을 생성해 w-transformer의 key-value pair과 stack한다. 이런 형태의 tangled transformer로 visual, linguistic features가 더욱 연관된다.
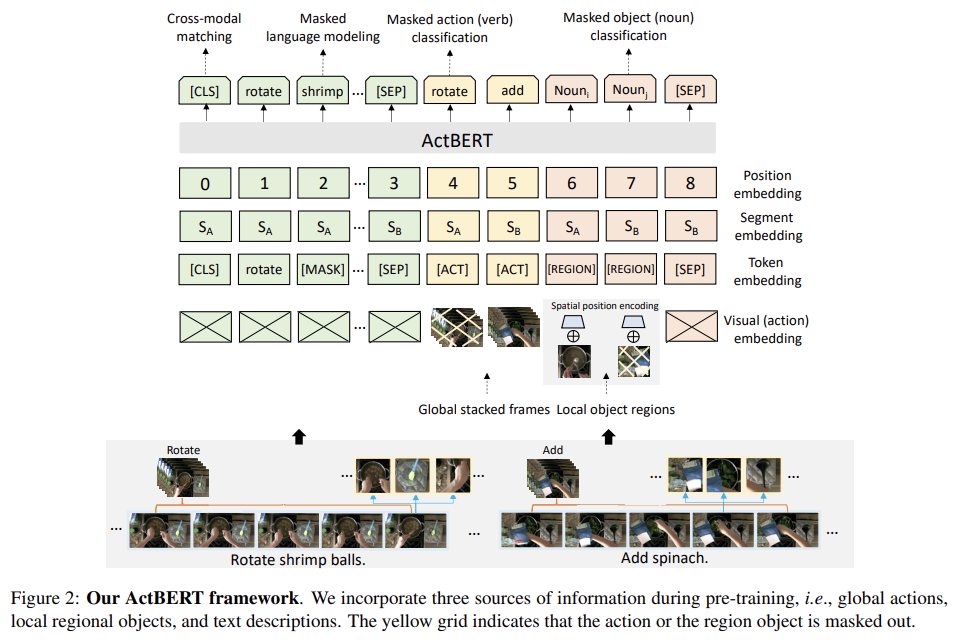
이제 pretraining의 4가지 task를 알아보자. 우리의 cross-modal setting에서 Masked Language Modeling을 확장했다. VideoBERT와 달리 actions와 regional information을 unified framework에서 명시적으로 model한다.
- Masked Language Modeling with Global and Local Visual Cues
BERT의 MLM을 확장한다. visual, linguistic entities 사이 관계를 밝히기 위해 local regional objects에서 온 visual cues와 global actions를 leverage한다. BERT처럼 input sentence 내 각 단어가 고정된 확률로 랜덤하게 mask된다. 이는 모델이 contextual descriptions에서 배울 수 있게 하며 동시에 관련된(relevant) visual features를 추출하게 한다. verb word가 mask되면 정확한 예측을 위해 모델은 action feature을 사용해야 한다. object의 description이 mask되면 local regional features가 더 많은 contextual information을 제공할 수 있다. 따라서 강력한 모델은 visual & linguistic inputs을 locally, globally align해야 한다. 그 다음 output feature에는 전체 linguistic vocabulary에 대한 softmax classifier가 추가된다.
- Masked Action Classification
비슷하게 Masked Action Classification에선 action features이 mask된다. 과제는 linguistic feature와 object feature에 기반해 masked action label을 예측하는 것이다. 이런 명시적인 action 예측은 두 가지 측면에서 이롭다. 첫째로 action sequential
cues가 long-term으로 활용될 수 있다. 예를 들어 “get into”, “rotate”, “add”의 action sequences을 가진 video의 경우 이 task는 이 instructional assignment을 수행하는 것에 관해 temporal order information를 더 잘 활용할 수 있다. 둘째로 더 나은 cross-modality modeling을 위해 regional objects와 linguistic texts가 leverage된다. 이때 목표가 masked-out action feature의 categorical label을 예측하는 것임에 주의하라. 이 task는 pretrained model의 action recognition capability을 향상시켜 나중에 많은 downstream task로 일반화될 수 있다.
- Masked Object Classification
Masked Object Classification에서는 regional object features이 랜덤하게 mask된다. masked-out image region에 대한 fixed vocabulary의 distribution을 예측하기 위해 ViLBERT를 따른다. masked-out region의 target distribution은 region을 (feature extraction stage 내의 동일한 pretrained detectection model에 순전파함으로써 추출한) softmax activation으로 계산된다. 두 분포 간 KL divergence가 최소화된다.
- Cross-modal matching
Next Sentence Prediction (NSP) task와 유사하게 first token [CLS]의 output 꼭대기에 linear layer을 적용한다. sigmoid classifier이 뒤따라 linguistic sentences와 visual features의 relevance score을 나타낸다. 점수가 높으면 text가 video clips을 잘 묘사함을 의미한다. 모델은 binary cross-entropy loss을 통해 최적화된다. 이 cross-modal matching task을 학습시키기 위해 unlabeled dataset에서 negative videotext pairs을 sample한다. positive pairs와 negative pairs을 sampling하는 방법은 HowTo100M 논문을 따른다.
HowTo100M dataset에 ActBERT를 pretrain한다. video-text inputs을 구축하기 위해 HowTo100M dataset에서 video clips을 sample한다. video-text joint training을 위해 하나의 clip만 사용하는 대신 longer context를 cover하기 위해 multiple adjacent clips을 leverage한다. 이는 ActBERT가 서로 다른 segments의 관계를 model할 수 있게 한다. 10 adjacent video clips을 sample하며 temporal-aligned linguistic tokens가 추출되어 video-text pair을 형성한다.
local regional features을 얻기 위해선 ViLBERT를 따라 Visual Genome dataset에 pretrain된 Faster R-CNN을 사용한다. backbone은 ResNet-101이다. regional feature을 추출하기 위해 1 FPS의 frame rate를 사용한다. 각 region feature은 그 region에서 온 convolutional feature에서 RoI-pool된다. 이하 생략한다.
action features을 얻기 위해선 먼저 action classification dataset을 구축한다. 8 FPS로 frames을 추출한다. 그 다음 softmax classification loss를 가지고 ResNet-3D network를 학습시킨다. 이하 생략한다.
다섯 downstream tasks, 즉 action step localization, action segmentation, text-video clip retrieval, video captioning, video question answering을 평가한다. 5 tasks를 CrossTask [59], COIN [37], YouCook2 [53], MSR-VTT [46] and LSMDC [32]에 평가한다. test set의 video는 pretraining할 때 HowTo100M에서 제거되었다.
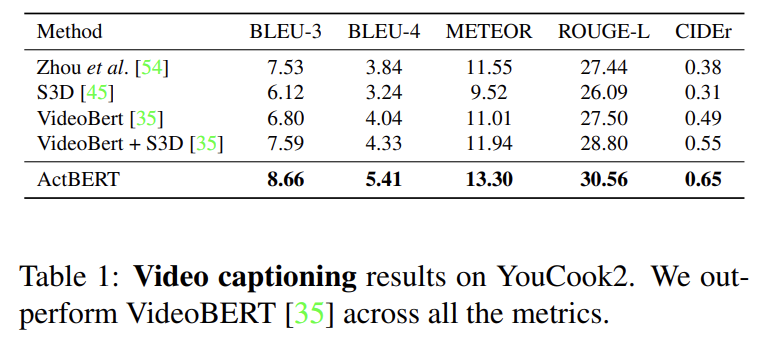
video captionoing은 VideoBERT와 ActBERT를 비교했으며 모든 metric에서 VideoBERT를 능가했다. 이는 우리의 pre-trained transformer가 더 좋은 video representation을 배움을 입증한다. 또 global, local video cues를 모두 고려하여 video sequences를 modeling하는 ActBERT의 효능을 보여준다.
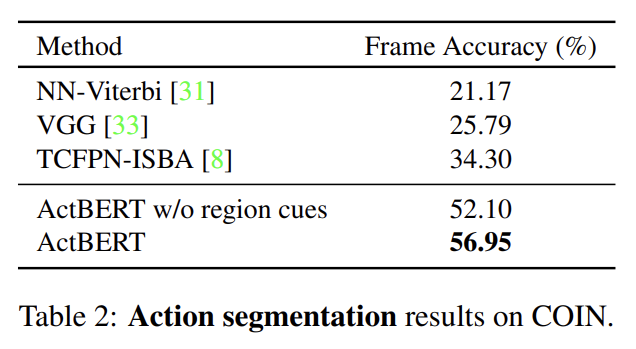
ActBERT가 baseline보다 20% 이상 좋은 성능을 보인다. 이는 ActBERT가 linguistic descriptions 없이 visual inputs만 다룰 수도 있음을 보여준다. regional information를 제거하면 성능이 하락하는데 이는 detailed local cues가 dense frame labeling task에 중요함을 보여준다.
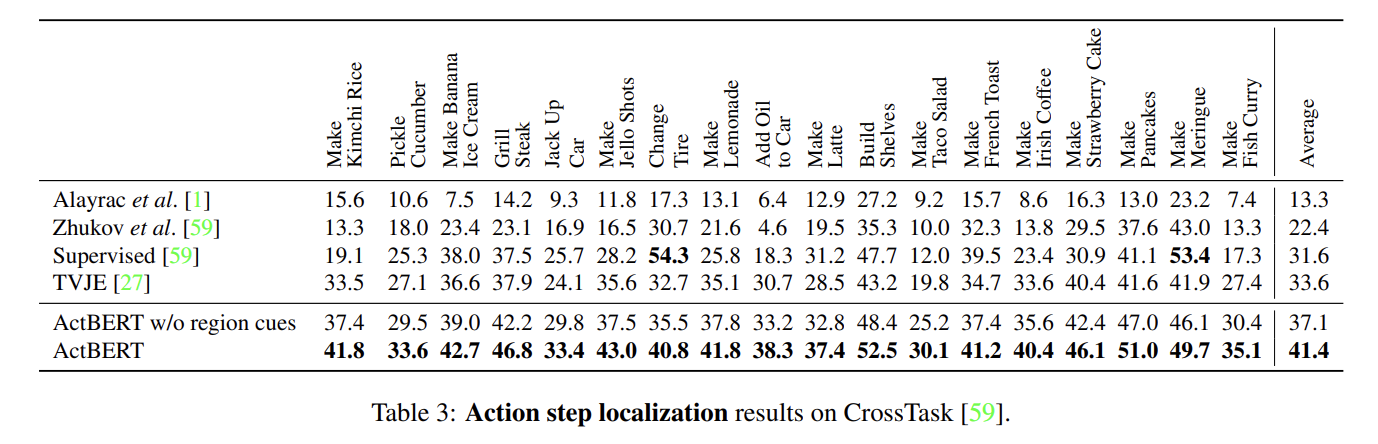
action step localization에서 ActBERT는 TVJE를 큰 폭으로 넘어선다. region cue가 없으면 성능이 하락하는데 regional information이 text-and-video matching을 위한 detailed local object features을 제공하는 중요한 source임을 입증한다.
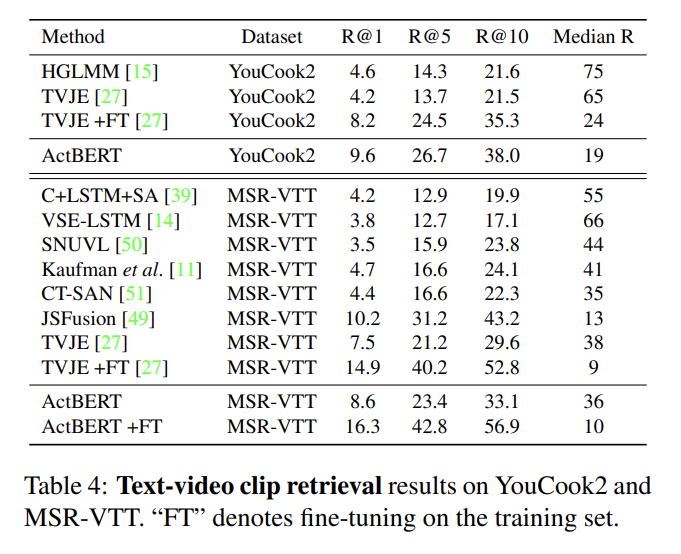
text-video clip retrieval은 ActBERT가 TVJE와 다른 baseline을 상당히 능가한다.
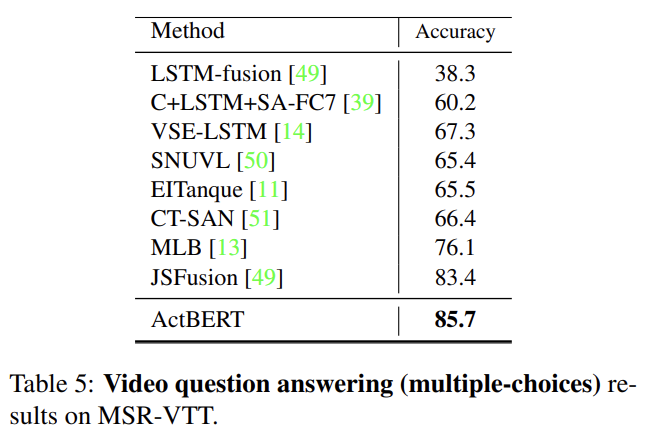
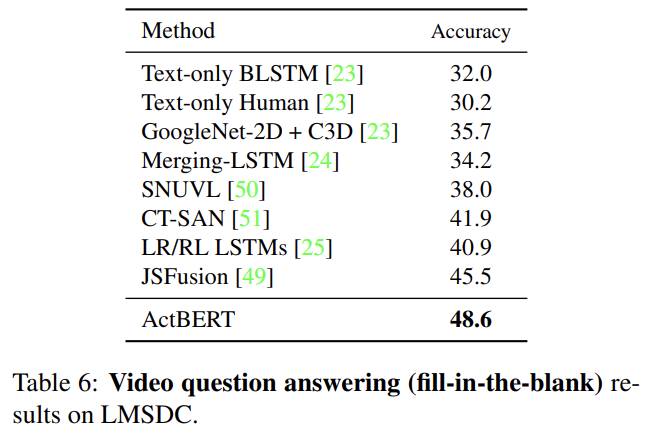
video question answering에서 ActBERT는 JSFusion을 넘어선다.
Strengths
- local한 visual 정보도 신경써서 성능 향상이 있었다.
- action도 명시적으로 input으로 받아 활용하는 방식이 독특했다.
Weaknesses
- instructual video를 사용할 때 영상과 음성의 의미가 일치하지 않는 어쩔 수 없는 오염이 데이터셋에 존재한다.
action을 명시적으로 활용하긴 했는데 개인적으로 세련된 방식은 아닌 것 같다.
