
오늘 리뷰할 논문은 object detection과 object instance segmentation에 사용되는 Mask R-CNN이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
Summary
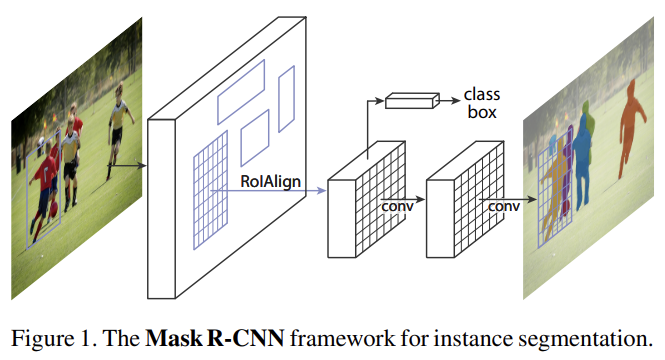
Mask R-CNN은 Faster R-CNN의 classification, bounding box regression branch에 평행하게 object mask를 예측하는 branch를 붙인 확장형이다. mask branch는 Faster R-CNN에 약간의 computational overhead만 더해 속도가 빠르고 instance segmentation, boundingbox object detection, person keypoint detection 등 다양한 task에 일반화하기 쉽다.
instance segmentation은 모든 object를 감지하고, 각 instance를 정밀하게 segment해야한다. 그래서 bounding box를 통해 개별 object를 classify하고 localize하는 object detection과 obejct instances 구분 없이 각 pixel을 categories에 맞게 분류하는 semantic segmentation을 합친 task라고 볼 수 있다.

Mask branch는 각 RoI(Region of Interest)에 적용되는 FCN(Fully Convolutional Network)이며, pixel-topixel manner로 segmentation mask를 예측한다.
하지만 Faster R-CNN은 network의 input과 output 사이 pixel-to-pixel alignment을 위해 디자인된 게 아니다. Faster R-CNN은 RoIPool을 사용하는데, 이는 feature extraction을 위해 coarse spatial quantization를 한다. 이 misalignment를 고치기 위해 논문은 RoIAlign이라고 이름붙인 간단한 quantization-free layer을 사용하여 정확한 spatial location을 보존한다. RoIAlign은 정확도 향상에 큰 효과를 보였다.
또 mask와 class prediction을 분리하는 것이 중요했다. 즉, classes 간의 competition 없이 각 class별로 binary mask를 독립적으로 예측하고, category를 예측하기 위해선 네트워크의 RoI classification branch를 사용한 것이다. 반면 FCN은 per-pixel multi-class categorization을 수행하며, segmentation와 classification이 결합된 형태다. 그래서 논문에서 실험한 결과 FCN은 instance segmentation 성능이 나빴다고 한다.
일단 Faster R-CNN부터 짚고 넘어가면, Faster R-CNN은 candidate object bounding boxes를 제안하는 Region Proposal Network (RPN) 단계와 각 candidate box에서 feature을 추출해 classification과 bounding-box regression을 수행하는 Fast R-CNN 단계가 있다.
Mask R-CNN은 Faster R-CNN과 동일한 RPN을 사용하고 두 번째 단계에서 평행하게 RoI마다 binary mask를 output한다. 이는 classification이 mask prediction에 의존하는 기존의 방식과 다르다.
training 시에는 각 RoI마다 multi-task loss 를 정의한다. classification loss와 bounding-box loss는 Fast R-CNN 논문과 동일하다. 각 K classes 별로 m x m binary mask를 encode하니 mask branch는 RoI마다 -dimensional output을 가진다. 여기에 per-pixel sigmoid를 적용해 average binary cross-entropy loss로 를 정의한다. ground-truth class k와 연관된 RoI는 k번째 mask만 가 정의되고 나머지 mask output은 loss에서 무시된다.
이러한 방식은 class 간 경쟁 없이 모든 class에 대한 mask를 생성하며, mask와 class prediction을 분리시킨다.
mask는 input object의 spatial layout을 표현한다. fc layer에 의해 불가피하게 짧은 output vector가 되는 class labels이나 box offsets와 달리 mask의 spatial structure를 추출하는 일은 convolution으로 제공되는 pixel-to-pixel correspondence으로 자연스럽게 다루어질 수 있다. 다시 말해 FCN을 사용해 RoI마다 m x m mask를 예측하는데, spatial dimension이 부족한 vector representation으로 collapse하지 않고 mask branch의 각 layer가 명시적인 m x m object spatial layout을 유지한다는 것이다. FCN은 FC layer 방식보다 parameter도 적고 더 정확하다.
이러한 pixel-to-pixel behavior은 그 자신이 feature이기도 한 RoI들이 explicit per-pixel spatial correspondence를 보존하도록 잘 align된 상태일 것을 요구한다. 그래서 RoIAlign layer을 사용한다.

RoIPool은 quantization을 사용하는데 이는 RoI와 extracted feature 사이 misalignment를 유발한다. 이는 classification에는 문제가 없지만 pixel-accurate masks를 예측하는 데는 문제가 있다. 그래서 RoIPool의 harsh quantization를 없애고 extracted feature를 올바르게 align하는 RoIAlign layer을 제안한다. RoIAlign은 RoI boundary나 bin에서 quantization을 피하고 bilinear interpolation을 사용해 각 RoI bin 내의 four regularly sampled locations에 있는 input feature 값을 정확히 연산하고 max/average로 결과를 aggregate한다.
inference time에는 classification branch가 예측한 k번째 class에 해당하는 mask만 사용한다. m×m floating-number mask output은 다시 RoI의 크기로 resize되고 threshold(=0.5)로 binarize된다.
ablation study 내용은 생략하겠다.

Mask R-CNN은 human pose estimation에도 사용될 수 있다. 사람 몸의 K keypoint types을 각각 하나의 one-hot mask로 예측하면 된다.
흥미로운 점은 keypoint branch를 추가해서 Mask R-CNN을 학습하면 box/mask AP(average precision)를 조금 떨어뜨린다는 것이다. keypoint detection은 multitask training에서 이득을 볼 수 있지만, 이것이 다른 task를 돕지는 못한다는 것이다. 일단 하나의 시스템으로 boxe, segment, keypoint를 동시에 예측할 수 있긴 하다는 것에 의의가 있다.
Strengths
- Faster R-CNN의 RoIPool을 개선해 정확도 향상을 이루었다. RoIAlign을 잘 설계한 게 feature의 정밀도를 높이는 데 크게 기여한 것 같다.
- 모델의 용도가 다양했다. object detection, instance segmentation, human pose estimation에 두루 사용될 수 있어서 좋았다.
FPN이 어디 쓰이나 했더니 backbone에 대한 ablation study에 쓰였다. ResNet, FPN, ResNeXt 등을 비교했다. 사실 앞서 FPN 논문을 안 읽고도 충분히 읽을 수 있는 논문이었던 것 같다.
흥미로웠던 점은 ablation study에서 Multinomial vs. Independent Masks를 비교했을 때 일반적인 FCN처럼 softmax와 multinomial loss를 사용해 classification과 mask를 결합하면 class 간 경쟁이 없을 때보다 성능이 떨어진다는 점이다. softmax가 만능인 줄 알았는데, mask 작업과 classification 작업 둘 모두 정확하게 학습하기엔 표현력? 용량(capacity)?이 부족했던 게 아닐까 싶다. 흥미로운 결과였다.
