
오늘 리뷰할 논문은 fMRI와 Stable Diffusion을 이용해 뇌 속 영상을 재구성하는 논문이다. 뉴스를 보고 너무 신기해서 논문을 찾아보게 되었다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
- 「Stable Diffusion」으로 fMRI에 의한 뇌 활동 데이터로부터 이미지를 생성하는 연구
- Stable Diffusion이 대체 무엇일까?(Latent Diffusion의 작동 원리)
- Diffusion model 설명 (Diffusion model이란? Diffusion model 증명)
- VAE(Variational AutoEncoder)
Summary
논문은 functional Magnetic Resonance Imaging (fMRI)와 latent diffusion model (LDM), 특히 Stable Diffusion을 이용해 brain activity에서 visual image를 reconstruct하고자 한다.
논문의 성과는 다음과 같다.
- 논문의 간단한 framework가 복잡한 deep generative models을 학습하거나 fine-tuning할 필요 없이 brain activity로부터 높은 semantic 정확도를 가진 high-resolution (512 ⇥ 512) images를 reconstruct할 수 있음을 입증했다.
- LDM의 특정 component를 distinct brain regions으로 mapping하여 neuroscience 관점에서 LDM의 component를 양적으로 해석한다.
- LDM으로 시행된 text-to-image conversion process가 어떻게 conditional text로 표현된 semantic information을 포함(incorporate)하는 동시에 원본 image의 모습을 유지하는지에 대한 객관적인 해석(objective interpretation)을 제시한다.
논문은 LDM의 각 component, process와 상응하는 brain activities의 관계를 실험함으로써 LDM의 biological interpretations을 얻을 수 있었다고 한다. 예컨대 어떻게 latent vectors, denoising processes, conditioning operations, U-net components가 visual stream에 상응되는지 말이다.
데이터셋은 Natural Scenes Dataset (NSD)을 사용했다. NSD는 실험대상이 10,000 images를 3번 반복해서 보는 30–40 sessions 동안의 7-Tesla fMRI scanner의 데이터를 제공한다. functional data를 위해서 NSD가 제공한 preprocessed scans (resolution of 1.8 mm)를 사용했다.
DM은 iterative denoising을 통해 Gaussian noise로부터 learned data distribution를 따르는 sample을 복구하는 probabilistic generative models이다. training data가 주어졌을 때 data에 Gaussian noise를 점진적으로 더하여 data의 structure을 파괴한다. 각 time point t에서 sample x는 다음과 같다.
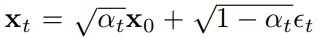
는 input 의 noisy version이고 alpha는 hyperparameter, epsilon은 Gaussian이다. inverse diffusion process은 original input을 회복하기 위해 각 step의 sample에 neural network 적용한다. learning objective는 이며 보통 neural network f로 U-Net이 사용된다.
이 방법은 neural network에 auxiliary input c를 삽입하는 것으로 conditional distributions을 학습하는 것으로 일반화될 수 있다. text sequence의 latent representation을 c로 둔다면 text-to-image model을 implement할 수 있는 것이다.
(중간에 LDM 설명 생략)
논문은 autoencdoer로 압축된 original image의 latent representation를 z로 정의하고, text의 latent representation을 c, 를 c를 이용해 수정된, z의 generated latent representation으로 정의했다.
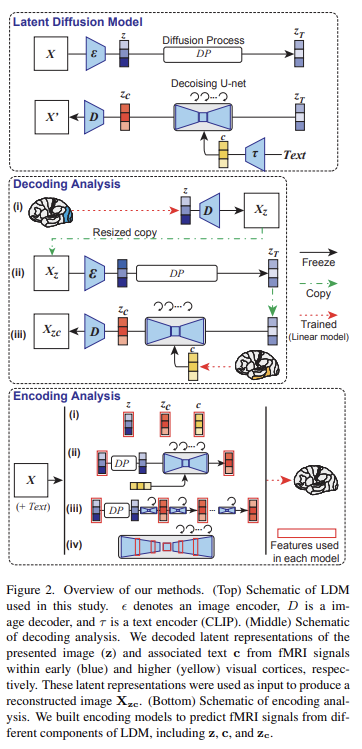
Decoding: reconstructing images from fMRI
논문은 Fig 2와 같이 세 단계를 통해 fMRI 신호로부터 visual reconstruction를 수행한다. 이 방법에서 필요한 training은 오직 fMRI signals를 각 LDM components에 map하는 linear models를 구축하는 것뿐이고 다른 training이나 fine-tuning은 필요하지 않다. 나머지는 (DDIM sampler의 parameter를 포함해) LDM의 저자들이 제공한 image-to-image와 text-to-image codes의 default parameter를 사용했다.
세 단계는 아래와 같다.
- 첫째로 early visual cortex의 fMRI signals에서 온 presented image X의 latent representation z를 예측한다. 그리고 z를 autoencoder 중 decoder에 넣어서 320 x 320 크기의 coarse decoded image 를 생성한다. 그 이미지를 다시 512 x 512로 resize한다.
- 를 autoencoder 중 encoder에 넣고 diffusion process 중에 noise를 더해준다.
- higher (ventral) visual cortex의 fMRI signals에서 온 latent text representations c를 decode한다. 를 생성하기 위해 denoising U-Net에 coarse image의 Noise-added latent representations 와 decoded c가 input으로 넣어진다. 마지막으로 autoencoder의 decoding module에 를 input으로 넣어 512 x 512 크기의 최종 reconstructed image 를 만든다.
fMRI에서 LDM component로 model을 설립하기 위해 L2-regularized linear regression를 사용했고 모든 모델은 실험대상 별로(per subject basis) 만들어졌다. weights은 training data에서 추정됐고 regularization parameters는 training 중에 5-fold crossvalidation를 통해 얻어졌다.
control analyses로써 위의 step 3에서 c나 z를 제외해서 오직 z나 c 한가지만을 가지고 image를 생성하기도 했다.
image reconstruction의 정확도는 generated image를 보고 original test images (N=982 images)가 식별될 수 있는지를 평가함으로써 perceptual similarity metrics (PSMs)로 객관적으로도, human raters(N=6)으로 주관적으로도 측정됐다. 다시 말해 two-way identification experiments를 수행한 것이며, fMRI로 reconstruct한 image가 랜덤하게 고른 reconstructed image보다 상응하는 original image에 더 가까운지를 평가했다.
Encoding: Whole-brain Voxel-wise Modeling
다음으로 논문은 brain activity와 mapping함으로써 LDM의 internal operation을 해석하려 했다. 이를 위해 아래의 4가지 세팅으로 whole-brain voxel-wise encoding models를 구성했다.
- 우선 세 latent representation z, c, 로부터 각자 독립적으로 voxel activity를 예측하는 linear models을 만들었다.
- z, 가 다른 이미지를 생성하지만 결과적으로 cortex에서 비슷한 prediction maps을 만든다. 따라서 이들을 single model로 설립하고(incorporate) 각 feature로 설명되는 unique variance를 cortex에 mapping하는 것으로 둘이 어떻게 다른지 실험했다. original
image의 appearance와 semantic fidelity of the conditional text 사이의 밸런스를 조절하기 위해 z에 더해지는 noise의 level을 다양화했다. 이 분석은 image-to-image process의 quantitative interpretation를 가능하게 했다. - LDM의 denoising process의 internal dynamics는 여전히 설명이 잘 안된다. 이 과정의 통찰을 얻기 위해 denoising process 중에 가 어떻게 변하는지 실험했다. 그러기 위해 denoising의 early, middle, late step 중 를 추출했다. 그리고 2번 분석과 같이 z와 combined models를 구축하고 cortex로 unique variance를 mapping했다.
- LDM에 관한 마지막 black box를 조사하기 위해 U-Net의 다양한 layer에서 feature를 추출한다. denoising의 서로 다른 step에 대해 encoding model들은 다양한 U-Net layers를 가지고 독립적으로 설립된다(first stage에서 둘, bottleneck stage에서 하나, second stage에서 둘). 각 voxel과 각 step마다 최고의 정확도를 가진 layer를 확인했다.
model weights는 L2-regularized linear regression를 사용해 trainng data에서 추정됐고 test data에 적용됐다. 평가를 위해 predicted, measured fMRI signals 사이 Pearson’s correlation coefficients를 사용했다. estimated correlations를 길이(N=982)가 같은 두 independent Gaussian random vectors 사이의 null distribution of correlations과 비교함으로써 statistical significance (one-sided)를 계산했다. statistical threshold는 P < 0.05로 설정됐고 FDR procedure를 사용해 multiple comparisons에 대해 수정되었다. principal component analysis(PCA)를 적용해 모든 feature dimension을 6400으로 줄였다.

Fig 3은 실험대상1에 대한 결과다. 각 test image에 대해 5개 images를 생성하여 가장 높은 PSMs를 가진 이미지를 선택했다. z만 이용해 뽑은 이미지는 original image와 visually consistent했지만 semantic content는 포착하지 못했다. 반면 c만 이용해 뽑은 이미지는 semantic 정확도(fidelity)가 높았지만 visually inconsistent했다. 로 뽑은 이미지는 높은 semantic 정확도를 가진 high-resolution images를 생성했다.

Fig 4는 모든 실험대상에서 reconstruct한 결과다. 실험대상에 관계없이 reconstruction quality가 안정적임을 볼 수 있다.
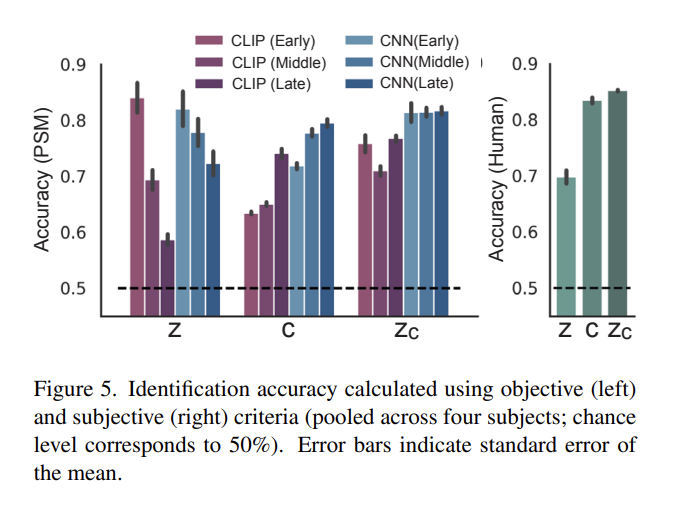
Fig 5는 quantitative evaluation 결과다. objective evaluation에서 로 만든 이미지가 z나 c만 이용한 경우보다 여러 metrics에서 일반적으로 정확도가 높음을 확인할 수 있다. 결과는 논문의 방법이 low-level visual appearance뿐 아니라 original stimuli의 high-level semantic content도 포착함을 보여준다.
c에 full-text annotations이 아니라 images와 연관된 categorical information를 사용하면 semantic fidelity 감소가 있었다. 또 z에 original images 대신 semantic maps를 사용하면 semantic fidelity 증가가 있었지만 visual similarity는 감소했다.
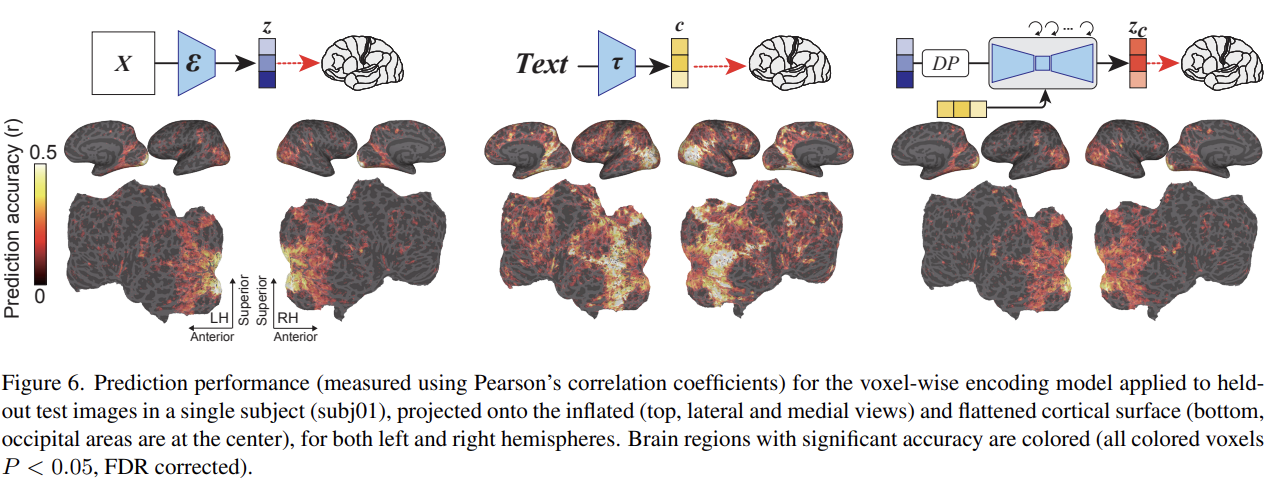
Fig 6은 LDM과 연관된 다음 3 종류의 latent representations에 대한 encoding model의 정확도를 보여준다.
- z : original image의 latent representation
- c : image text annotation의 latent representation
- : c로 cross-attention을 한 reverse diffusion process 이후 z의 noise-added latent representation
모든 세 요소가 높은 예측 성능을 visual cortex에서 보였지만 차이가 있었다. z는 early visual cortex라 불리는 visual cortex의 후반부에서 높은 prediction peformance를 보였고 higher visual cortex라 불리는 전반부에서도 상당한 성능을 보였지만 다른 영역에선 낮았다. 반면 c는 higher visual cortex에서 가장 높은 prediction performance를 보였고 cortex의 넓은 범위에서 높은 prediction performance를 보였다. 는 z와 비슷하게 early visual cortex에서 높은 성능을 보였다. 또 z에 noise level을 줄여 를 사용하면 z로부터 얻은 prediction map과 비슷한 map을 생성한다.

z와 의 feature이 설명하는 unique variance를 알고자 논문은 z와 를 동시에 포함하는 single model을 만들어 각 feature의 unique contribution을 실험한다.
Fig 7은 작은 양의 noise가 추가되면 z가 보다 voxel activity를 더 잘 예측함을 보여준다. noise의 level을 올리면 는 higher visual cortex 내의 voxel activity를 z보다 더 잘 예측했는데, 이는 image의 semantic content이 점진적으로 강조됨을 나타낸다. 이 결과는 어떻게 text-conditioned image-toimage process가 semantic content와 original visual appearance 사이를 balance할 수 있는지 보여주어 흥미롭다.
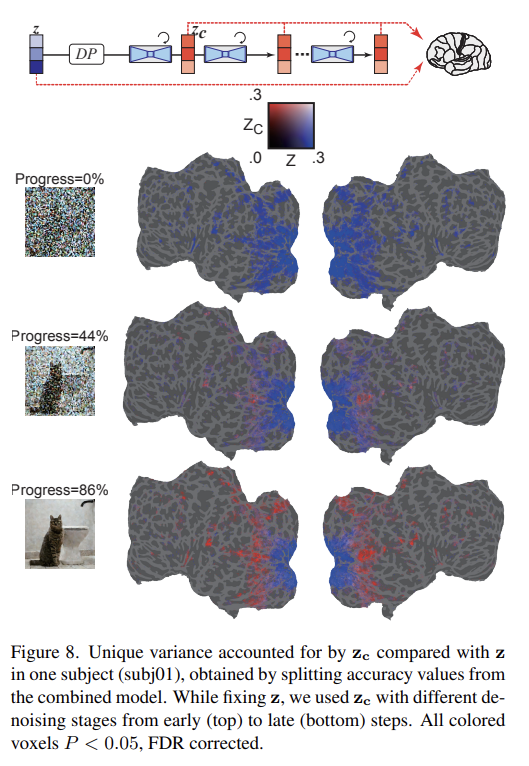
다음으로 iterative denoising process 중에 어떻게 noise-added latent representation가 변하는지 확인했다. Fig 8은 early stages에 z가 prediction을 dominate하는 것을 보여준다. 중간 단계에선 가 z보다 higher visual cortex 내의 activity를 잘 예측했고 이 단계에서 대량의 semantic content가 드러남을 알 수 있었다.
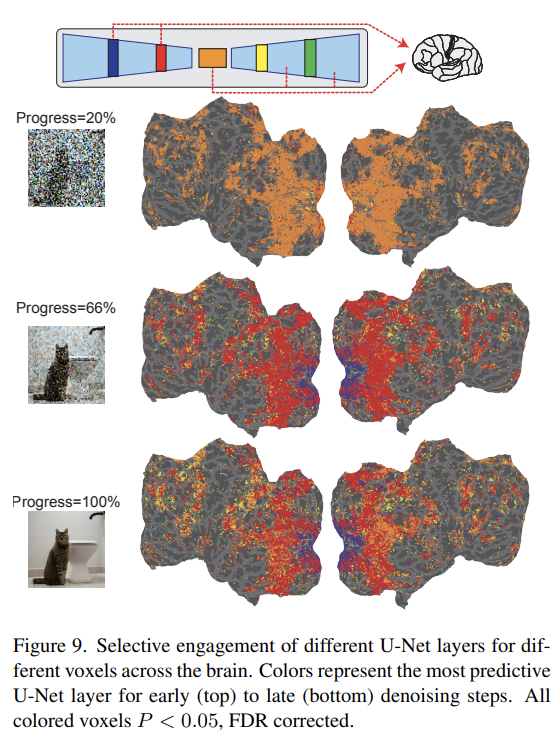
마지막으로 U-Net의 각 layer에서 무슨 정보가 process되는지 확인했다. Fig 9는 denoising process의 early, middle, late step과 U-Net의 서로 다른 layer에서 결과를 보여준다. denoising process의 초기에는 U-Net의 bottleneck layer가 가장 높은 prediction performance를 보여준다. denoising이 진행될수록 U-Net의 early layer(파란색)이 early visual cortex 내의 activity를 예측하고 bottleneck layer은 higher visual cortex를 향해 우수한 predictive power가 이동한다.
이 결과는 reverse diffusion process의 시작(beginning)에서 image information이 bottleneck layer 내에서 압축됨을 시사한다. 그리고 denoising이 진행됨에 따라 U-Net layers 간에 기능적 분리가 나타난다. 예컨대 first layer은 early visual areas에서의 fine-scale details를 표현하고 bottleneck layer은 더 ventral, semantic areas 내의 higher-order information와 상응한다.
Strengths
- training이나 fine-tuning 없이 쉽게 이용할 수 있다. fMRI에서 LDM내 latent representations로의 간단한 linear mappings만 있으면 된다.
- encoding models을 통해 visual cortex의 전, 후반부 activity를 관찰하여 Stable Diffusion의 내부 작동 원리를 규명하려고 시도한 점이 참신했다.
- 무엇보다 결과가 흥미로워서 논문 읽는 게 재미있었다.
Weaknesses
- 뉴스에선 Ai가 사람 뇌, 마음을 읽을 수 있다는 식으로 말하던데 그 정도는 아닌 것 같다. 어디까지나 사람이 '보고 있는' 것과 유사한 semantic, visual appearance를 가진 비슷한 사진을 '재구성'하는 것이지, 완전히 똑같은 영상을 뽑아내는 것도 아니고 마음을 읽는 것도 아니고 그마저도 text 없이는 불가능하다. 사람이 무엇을 보는지 이미 알고 있어 그것을 input text(c)로 넣어준다는 전제가 필요하고, 사람의 현재 시각 인식에 대한 사진만 얻을 수 있을 뿐이다. 그래도 청각 등 다른 범위로 확장될 수 있다는 점에서 의의가 있는 것 같다.
reconstruct 결과가 굉장히 신기하기는 한데 개인적으로는 Stable Diffusion의 성능이 워낙 뛰어난 것, 그리고 text input(c)를 넣어준 것이 그럴듯한 결과에 가장 크게 기여한 것 같다. Fig 3를 보면 의 결과는 semantically 비슷하면서도 visual appearance에 대한 detail은 꽤 다르다. 사실 Stable Diffusion에 그냥 text만 넣어도 상당히 그럴듯한 사진을 생성한다는 것을 생각하면 논문의 실험 결과도 text input에 의해 dominate되고 있는 게 아닌가하는 의심이 든다. 그래도 생성된 사진의 구도, 위치 따위가 원본과 유사한 점을 보면 fMRI input(z)의 영향이 아예 없는 건 아닌 것 같은데... z는 생성된 사진이 원본과 visual appearance가 비슷하도록 제약하는 일종의 constraint/regularization 역할일 뿐인 게 아닐까.
어째 이전에 리뷰했던 A Neural Algorithm of Artistic Style (Neural style transfer) 논문처럼 약간 야매 느낌이 난다(...).
적어도 visual cortex와 Stable Diffusion을 연관해 이해하려 시도한 점은 굉장히 인상적이었다.
