오늘 리뷰할 논문은 word2vec처럼 단어 임베딩을 만드는 데 사용되는 GloVe 논문이다.
아래 포스트를 먼저 보면 도움이 될 것이다.
- [논문 리뷰] GloVe: Global Vectors for Word Representation
- [NLP 근본 논문 리뷰 #1] GloVe: Global Vectors for Word Representation (EMNLP 2014)
- GloVe(글로브) 개념정리(feat. GloVe: Global Vectors for Word Representation 논문)
Summary
word vector를 배우는 두 주요 모델은 1) latent semantic analysis (LSA) 같은 global matrix factorization methods와 2) skip-gram model 같은 local context window methods이다. 그러나 둘 다 단점이 있다. LSA 방식은 statistical information을 효율적으로 leverage하지만 word analogy task에 상대적으로 나쁘게 작동해서 sub-optimal vector space structure를 암시한다. skip-gram 방식은 analogy task에 더 잘 작동하지만 학습 중에 global co-occurrence counts 대신 separate local context windows로 학습하기 때문에 corpus의 statistics를 잘 활용하지 못한다.
논문은 linear directions of meaning (king − queen = man − woman 의미하는 듯)을 생성하는 데 필요한 model properties를 분석하고 global log-bilinear regression models가 이에 적합하다는 것을 보인다. 논문은 global word-word co-occurrence counts에 학습해 statistics를 효과적으로 이용하는 weighted least squares model을 제안한다. 모델은 word analogy dataset에 75% 정확도의 SOTA를 달성하여 meaningful substructure를 가진 word vector space를 생성한다. 또 모델이 여러 word similarity tasks와 common named entity recognition (NER) benchmark에서 다른 모델들을 outperform하는 것을 보인다.
corpus 내 word occurence의 statistics가 word representation을 학습하는 unsupervised methods의 정보의 근원이다. 그러나 어떻게 statistics에서 의미가 생성되고 어떻게 resulting word vectors가 그 의미를 표현할지는 여전히 핵심 문제다.
GloVe를 보기 전에 먼저 표기를 정리하고 간다. X는 matrix
of word-word co-occurrence counts, entries 는 word i의 context에서 word j가 나타나는 횟수, 는 word i의 context에서 나타나는 모든 단어의 횟수, 는 word i의 context에서 word j가 나타날 확률이다.

raw probabilities보단 ratio가 relevant words를 irrelevant words로부터 구별하기 용이하고 두 relevant words를 구분하기도 좋다. word vector learning도 probability 자체보다는 ratios of co-occurrence probabilities로 수행되어야 한다.
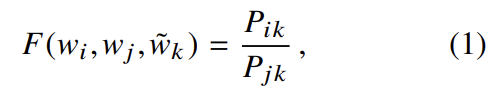
이는 세 단어 i, j, k에 기반하며 w는 word vectors, 는 separate context word vectors다. 식의 우변은 corpus에서 추출하고 좌변의 F는 (아직 명시하지 않은) parameters에 기반한다. F는 여러 선택지가 있는데, 몇 가지 조건을 선호해 선택지를 줄일 수 있다. 첫째로 F가 word vector space에서 정보가 ratio 를 표현하도록 encode하고 싶다. vector space가 내재적으로 linear structures이기 때문에 가장 자연스러운 방법은 vector differences이다.
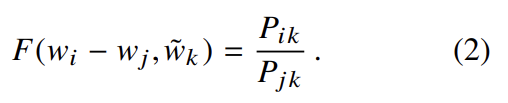
식 (2)의 좌변은 vector인데 우변은 scalar이다. 그래서 arguments를 dot-product한다.
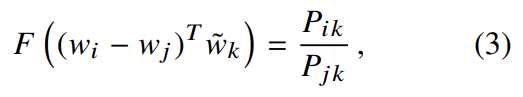
word-word co-occurrence matrices에 대해 word와 context word의 차이는 임의적이며 둘의 역할을 바꾸기도 자유롭다. 이것이 consistent하려면 로 바꿔야 한다. final model이 이 relabeling에 invariant해야 하는데 식 (3)은 그렇지 않으므로 두 단계에 걸쳐 symmetry를 얻는다. 우선 F가 groups (R,+)와 (R>0, ×) 사이 homomorphism이도록 요구한다.
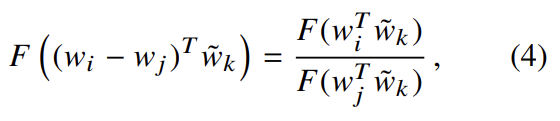
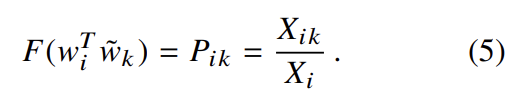
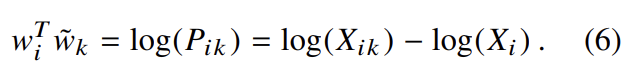
식 (4)는 식 (3)에 의해 식 (5)로 풀리고 식 (4)의 해는 F = exp고 식 (6)이 성립한다. 식 (6)은 우변의 만 아니라면 symmetry를 보인다. 그러나 이 항은 k에 독립적이라 w_i에 대한 bias b_i로 흡수될 수 있다. 마지막으로 에 대한 additional bias 를 추가하여 symmetry를 얻는다.
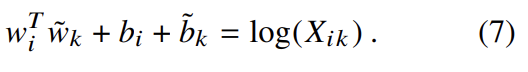
식 (7)은 식 (1)의 급격한 간략화이지만 argument가 0으로 갈 때 로그함수가 발산하기 때문에 ill-define된 것이다. 이를 해결하는 간단한 방법은 로그함수에 additive shift를 추가해 를 만드는 것이다.
그래서 논문은 weighted least squares regression model를 제안한다. 식 (7)을 least squares problem로 만들고 cost function에 weighting function 를 도입해 다음과 같이 model을 만든다.
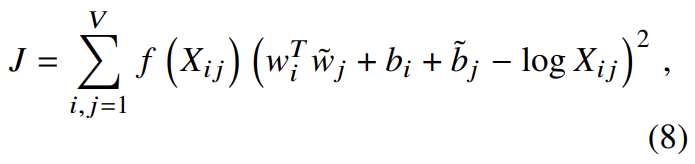
V는 vocabulary의 크기다. weighting function은 다음 특징을 만족해야 한다.

논문은 다음과 같은 f를 선택했다.
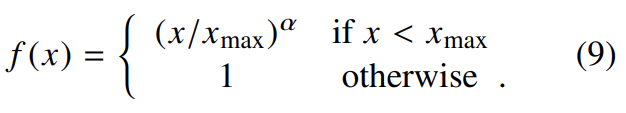
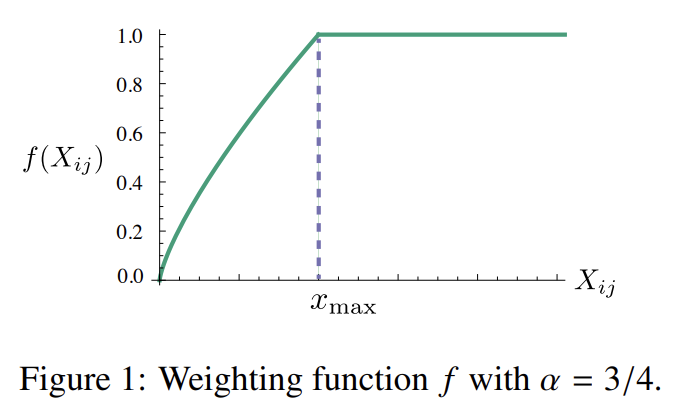
model 성능은 cutoff에 약하게 의존하고 이후 실험에서 으로 고정했다. 그리고 경험적으로 가 좋은 성능을 보였다.
(3.1 Relationship to Other Models, 3.2 Complexity of the model 생략)
실험은 Mikolov et al.의 word analogy task와 Luong et al.의 여러 word similarity tasks를 수행하고 CoNLL-2003 shared benchmark dataset for NER에도 실험한다. 학습은 여러 크기의 다섯 개의 corpora를 사용했다.
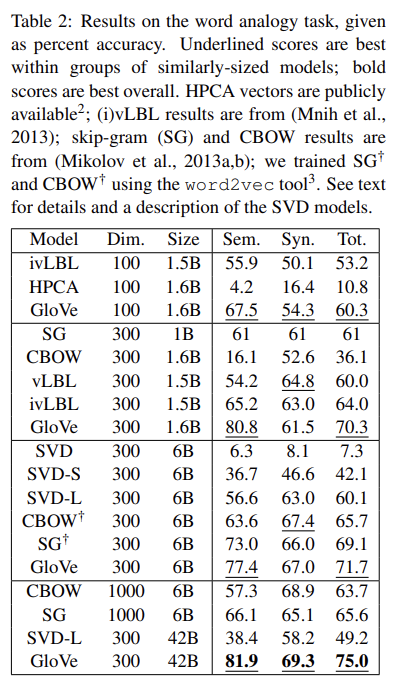
Tab 2는 word analogy task의 결과다.
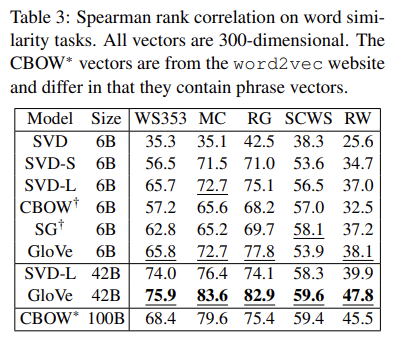
Tab 3는 다섯 가지 word similarity dataset에 대한 similarity score를 구해 human judgement와 Spearman’s rank correlation coefficient를 계산한 것이다.
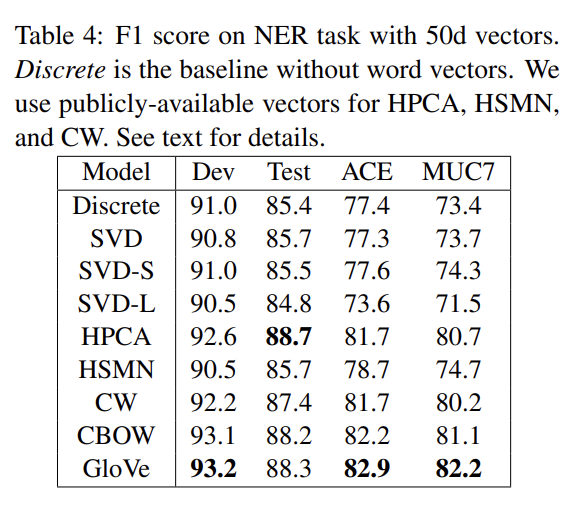
Tab 4는 CRF-based model를 가지고 NER task를 한 결과다.
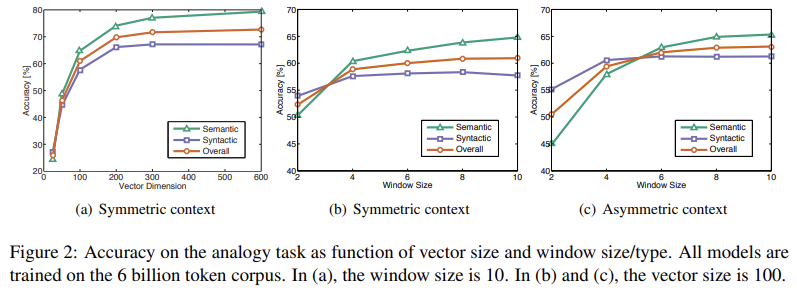
Fig 2는 vector length와 context window를 바꾸며 실험한 결과다.
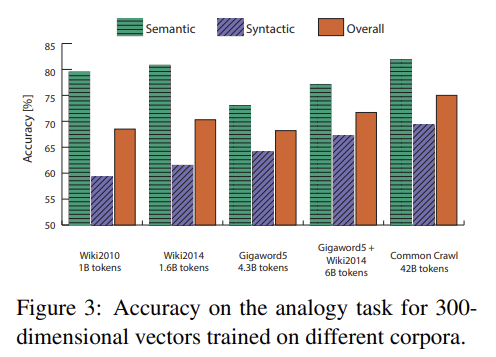
Fig 3는 여러 크기의 corpora에 word analogy task를 수행한 것이다.
Strengths
- FM과 local window based model의 단점을 보완하여 sementic vector space representation을 제안했다.
- word2vec보다 잘 작동한다.
Weaknesses
- 수식을 전개하고 유도하는 과정이 직관에 의존하고 논리의 비약이 큰 것 같다. (근데 사실 대부분 논문이 그럴지도...)
