오늘 리뷰할 논문은 고흐 사진으로 유명한 style transfer 논문이다.
아래 포스트를 먼저 읽으면 도움이 될 것이다.
- 논문 읽기 및 구현(1)- A Neural Algorithm of Artistic style
- [논문 요약14] A Neural Algorithm of Artistic Style
- Gram matrix (그람 행렬) 정리
Summary
논문은 CNN(VGGNet)을 이용해 사진/그림을 style과 content라는 요소로 구분해 이 두 가지를 재조합하여 새로운 artistic image를 생성하는 것을 목표로 한다.
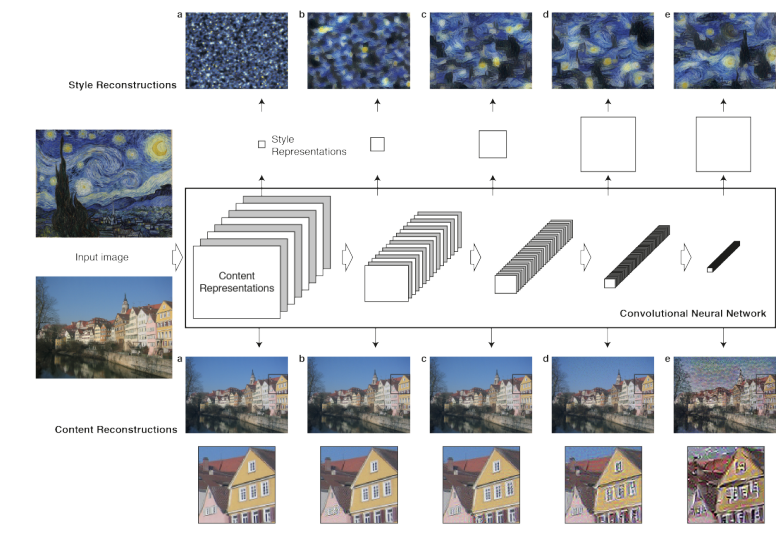
CNN에서 feature map을 reconstructing하는 것으로 각 layer의 정보를 visualize할 수 있다. 이때 Higher layers는 high-level content를 포착(capture)하고 lower layers에서 reconstruction은 원본 이미지의 exact pixel values를 재생산한다. 따라서 논문에서는 higher layers에서의 feature response를 content representation이라고 부른다.
style representation을 얻기 위해선 본래 texture information을 포착하기 위해 디자인된 feature space를 사용한다. 이 feature space는 네트워크의 각 층 filter response 꼭대기에 만들어진다. 이는 서로 다른 filter response 간의 correlation으로 구성된다. 이렇게 여러 층의 feature correlation을 포함하는 것으로 input image의 stationary, multi-scale representation를 얻을 수 있으며 global arrangement이 아니라 texture information을 포착하게 된다.
style feature에서의 reconstruction은 colour, localised structures 같은 general appearance를 포착하는 input의 texturised versions를 생성한다. 또 계층을 따라(즉, layer가 높아질수록) local image structure의 size와 complexity가 상승하는데, receptive field sizes와 feature complexity가 증가하기 때문이다. 논문에서는 이 multi-scale representation를 style representation이라고 부른다.

논문에선 서로 다른 두 이미지에서 각자 style과 content를 추출해 재조합한다. 사진에서 global arrangement를 뽑고(content) artwork에서 global scenary를 구성하는 colours와 local structures를 뽑는다(style). 이를 통해 미술작품의 style을 가진 사진을 만들 수 있다.

또 앞서 언급했듯 style representation은 neural network의 multiple layers를 포함하는 multi-scale representation이다. 위의 사진의 경우 모든 layer을 포함한 style representation인데, lower layers를 덜 포함하는 것으로 style을 더 locally 정의할 수 있다.
style representations를 higher layers에 matching하면 local images structures들이 large scale에서 match되며 더 smoothe하고 continuous한 visual experience를 만든다. 위의 사진의 마지막 row(E)가 highest layer에서 matching한 경우다.
이때 style과 content를 완벽히 분리하기는 어렵다. 논문에선 loss function을 각자 content와 style을 위한 2개 항으로 구성한다. 그래서 (위의 사진의 열처럼) style과 content 어느 쪽을 강조할 건지 조절할 수 있다. 사진의 왼쪽 열이 style을 강조한 것이고 오른쪽 열이 content를 강조한 것이다.
논문은 뉴런 간 correlation을 추출하는 게 primary visual system (V1)의 complex cells의 역할과 비슷하기에 biologically plausible computation이라고 한다. 그래서 논문의 결과를 '서로 다른 processing stage에서 complex-cell like computation를 수행하는 게 visual input의 content-independent representation를 얻는다'라고 해석한다.
논문에 사용된 network는 VGGNet에 기반하는데, VGG-19의 16 convolutional와 5 pooling layers를 사용하며 fully connected layer은 사용하지 않는다. 또 gradient flow를 향상시키고 더 좋은 결과를 내도록 max-pooling를 average pooling으로 교체했다.
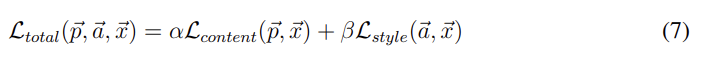
앞서 말했듯 loss function은 2가지 항, content항과 style항의 합으로 표현된다. 이때 p는 photograph, a는 artwork이며 x는 generated image인데 처음에는 랜덤한 white noise image이다. 즉, 하나의 layer에서 온 photograph의 content representation과 여러 layer에서 온 artwork의 style representation과 distance가 최소화되도록 back-propagation해서 noise image를 조금씩 변형해 생성하는 것이다. alpha, beta는 일종의 hyperparmeter고 앞서 말했듯 두 loss 항의 비중을 변경시키기 위해 사용된다. Fig 3의 열이 alpha/beta 비율을 나타낸다.
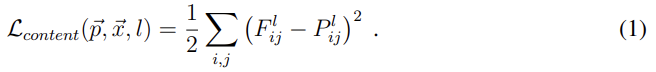
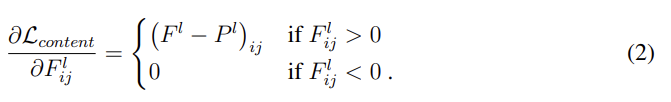
content의 loss항과 그 미분은 위와 같다. F는 (노이즈에서 생성된 이미지) x를 넣었을 때 l번째 layer에서 i번째 채널, 즉 i번째 feature map의 j번째 위치의 값을 의미한다. 마찬가지로 P는 photograph을 넣었을 때의 값이다. Fig 1이 어떤 layer을 선택하면 어떻게 나오는지 보여준다.

style representation의 경우 filter 사이 correlation을 계산한다고 했는데, 이는 Gram matrix으로 나타낸다. G는 l번째 layer에서 i번째 feature map과 j번째 feature map의 내적이다.
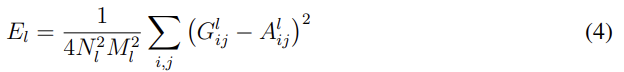

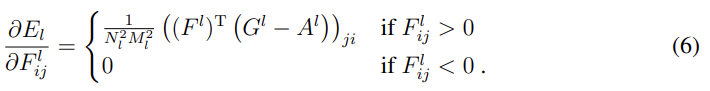
style의 loss는 artwork에서 만든 gram matrix A와 x에서 만든 gram matrix G를 최소화한다. 이때 style의 경우 여러 layer을 합산하므로 식 (5)에서 볼 수 있듯이 각 layer의 contribution에 따라 weighting factor(w)를 곱해준다(논문에서는 w를 선택한 layer들은 1/n빵하고 안쓰는 layer들은 0으로 둔 듯하다). 선택한 layer들에 따른 변화도 FIg 1에서 볼 수 있다.
Strengths
- image의 구성 요소를 style과 content로 구분해 변형, 재조합하려 한 시도가 참신했다. 더불어 noise image를 두 개의 loss 항을 모두 최소화하도록 update하는 것이 좋았다.
- 각 feature map의 correlation을 계산하기 위해 Gram matrix를 채택한 게 신선했다.
- 결과물이 눈으로 보이고 visually impressive하다. 비록 quantitative한 분석은 없지만 qualitative하게는 꽤나 성공적이다.
- 새로운 architecture를 만드는 게 아니라 기존의 VGGNet에서 FC layer만 제거하고 loss function만 변경했다는 점이 기존의 CNN이 지닌 가능성을 보여주는 것 같아서 좋았다.
Weaknesses
- 이론적 기반이 부족한 것 같다. 성과와는 별개로 직관적인 접근이 많은 것 같다.
- 어떤 layer을 사용할지 선택하는 것이나 hyperparameter에 대한 연구가 부족한 것 같다. 그냥 사용했더니 잘 나왔더라가 끝인 것 같아서 아쉽다.
논문은 이 성과가 psychophysics over functional imaging, electrophysiological neural recordings 등 visual perception 연구에 도움을 줄거라 생각하는데... 사실 그 정도는 아니고 그냥 재밌는 장난감 수준인 것 같다.
결과물이 신기해서 링크 첨부한 포스트를 따라하면서 코드도 실습해보고 싶다.
참고로 Andrew Ng 교수님의 강의에도 설명이 나온다.
