
💡 Keras란?
파이썬으로 구현된 high-level deep learning API이다.
high-level은 추상화 레벨이 높다는 것으로 딥러닝 모델에 적합하다.
또한 쉬운 사용법과 간단한 문법, 빠른 설계가 가능하다.
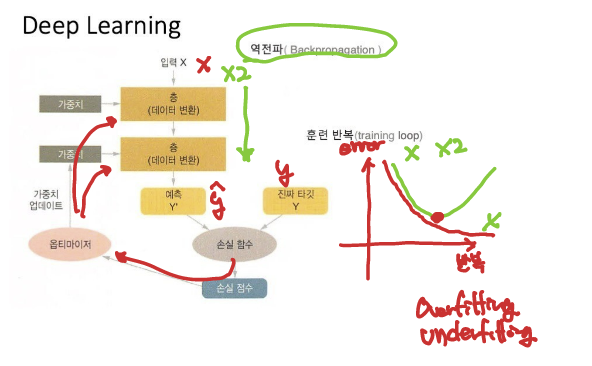
케라스는 위와 같이 x값 input되었을때,
예측된 y값과 실제 y값을 비교하고 손실 점수에 따라
최적의 값을 찾는 프레임워크로 활용된다.
- overfitting : 학습 데이터를 과하게 공급하여 학습시켰을 때 발생하는 에러
- underfitting : 학습 데이터를 부족하게 공급하여 학습시켰을 떄 발생하는 에러
✔️ 파이썬으로 Keras 프레임워크를 활용해 데이터를 분석하고 학습시키는 딥러닝 과정을 구현할 수 있다.
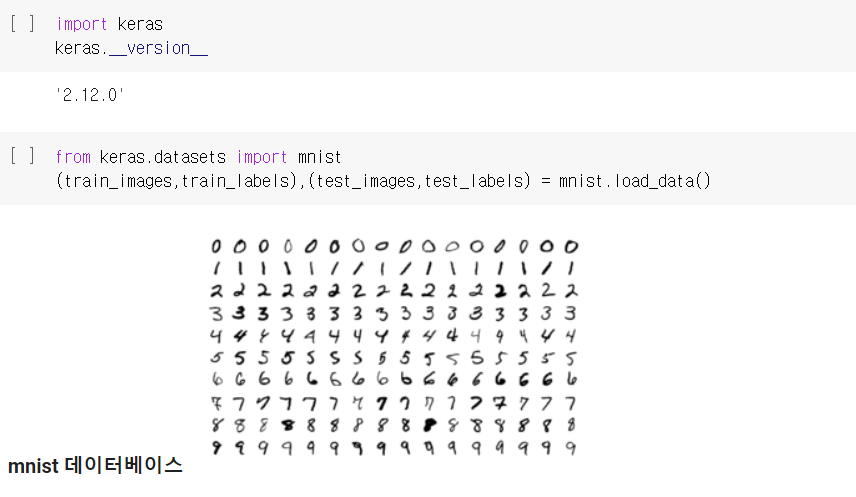
케라스 모듈을 import하고 keras 버전도 확인해주었다.
케라스에서 사용할 datasets은 mnist라는 손글씨 데이터이다.
minst.load_data()함수를 호출하여 반환된 값을 (train_images, train_labels), (test_images, test_labels)에 각각 할당해주었다.
- train_images : 학습용 이미지 데이터
- train_labels : 학습용 이미지 라벨
- test_images : 테스트용 이미지 데이터
- test_labels : 테스트용 이미지 라벨
위와 같이 분리된 학습 데이터셋과 테스트셋은 머신러닝 모델을 학습시키고 검증하는 데 사용된다.

train_images와 test_images의 데이터 모양을 살펴보았다.
train data는 60000개로 학습하고 test data는 10000개로 테스트를 진행할 것이다.

train_labels의 dtype은 uint8이며,
이는 데이터 타입이 부호 없는 8비트의 정수임을 의미한다.
train_labels의 각 요소는 array([5,0,4,...,5,6,8])이며 해당 학습용 이미지 데이터가 0부터 9까지 나타낸다. train_labels의 첫 번째 요소는 첫 번째 학습용 이미지 데이터가 숫자5를 나타내는 것을 의미한다.
이 머신러닝 모델은 학습용 이미지 데이터와 해당 이미지 데이터가 나타내는 숫자(label)을 함께 사용하여 숫자 인식 분류 문제를 학습할 것이다.
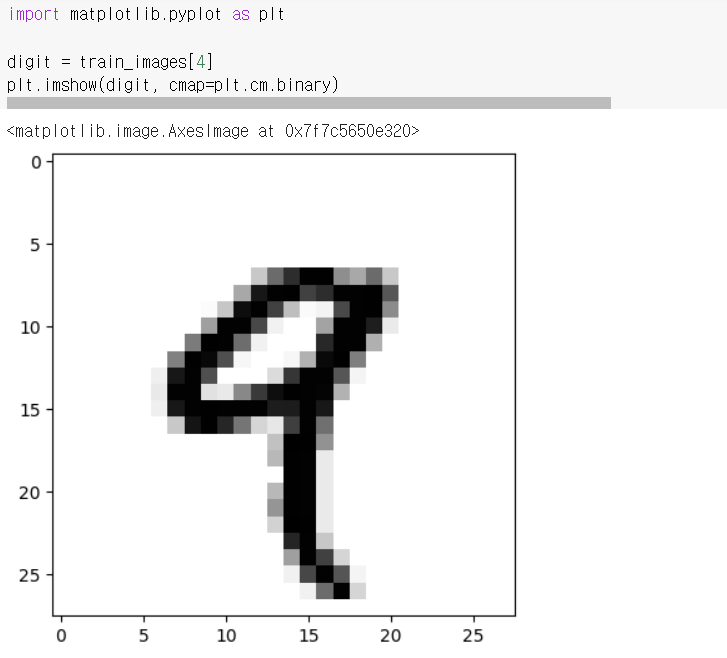
✔️ 데이터 확인
우선 matplot 모듈을 import하여 파이썬의 데이터를 시각화할 수 있게 세팅해두었다.
digit = train_images[4]은 이미지 데이터셋에 5번째 이미지를 train_images라는 변수로 불러와 digit이라는 변수에 저장해두었다.
inshow 함수는 이미지를 보여주는 함수.
cmap 함수는 colormap을 설정하는 인자.
plt.cm.binary는 흑백 이미지를 표시하기 위한 colormap.
따라서 plt.imshow(digit, cmap=plt.cm.binary)은 digit 변수에 저장된 이미지 데이터를 흑백으로 시각화하는 코드이다.
✔️신경망 만들기

신경망을 만들기 위한 모듈을 임포트해주었다.
-
optimizer은 손실 함수에 손실 점수에 따라 가중를 조절하는 역할이다. (옵티마이저 자세한 내용은 다음 포스팅에 언급하겠다.)
-
Sequential()은 순차적으로 레이어 층을 더해주는 순차 모델이라고 불리며, 케라스에서 흔히 사용되는 모델이다.
network.add(layers.Dense())을 2개 생성하여 2개 레이어를 가진 신경망으로 만들었다. 구조의 이해를 위해 아래와 같은 그림을 첨부하였다.
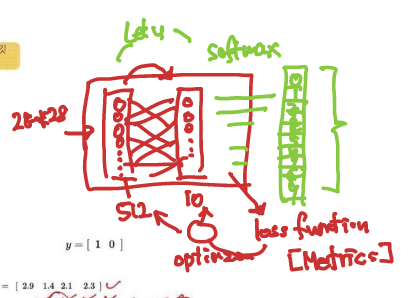
- Dense()는 뉴런마다 input들이 전부 연결된 것들을 Dense Layer라고 부른다.
첫 번째 layer는 512개의 유닛과 28x28 배열의 입력되는 모양을 가진 레이어
두 번째 layer는 출력층이며, 0~9까지 layer들을 계산하며 모양은 생략해도 1번 layer과 동일하게 적용된다.
✔️ 데이터 준비하기

이미지 데이터는 기본적으로 3차원으로 구성되어 있으며, 모델을 학습하기 위해 과부화 발생을 방지하기 위해 차원을 축소해주는 것이 좋다.
reshape함수를 사용해 데이터 손실 없이 데이터 모양만 바꿔 2차원으로 축소시켜주었다.
또한 이미지 데이터는 0~255까지의 값으로 이루어져 있으며, 이 값을 신경망 모델이 학습할 수 있는 형태로 변환하기 위해 'float32' 데이터 타입으로 변환해주었다.
이렇게 하면 소수점 이하의 값을 포함할 수 있어, 더 다양한 값을 표현할 수 있다.
÷ 255를 한 이유는 모든 픽셀 값이 0부터 1사이의 값으로 스케일링시키기 위해서 이다. 픽셀값이 모두 동일한 범위내에 있게 되어 학습이 더욱 안정적으로 이루어지게 된다.
✔️ 라벨 데이터를 카테고리 데이터로 변환하기
원래 아래와 같이 train_labels은 1차원에 8비트 정수형 데이터이다.


라벨 데이터는 숫자가 아닌 문자 데이터로 인식하게 설정하여 계산되지 않게 해주었다.
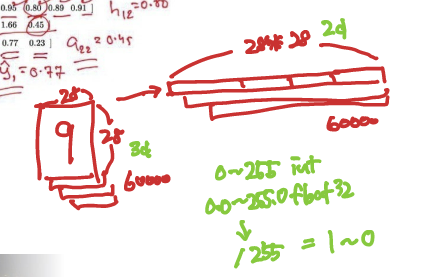
그림과 같이 라벨 데이터는 문자로 남게된다.
✔️ 신경망 학습
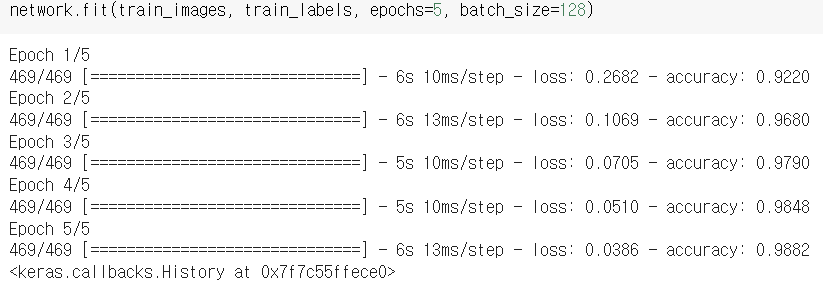
network 변수에 train_images와 train_labels를 fit함수로 학습시킨다.
이때 epochs = 5, batch_size = 128로 지정해주었다.
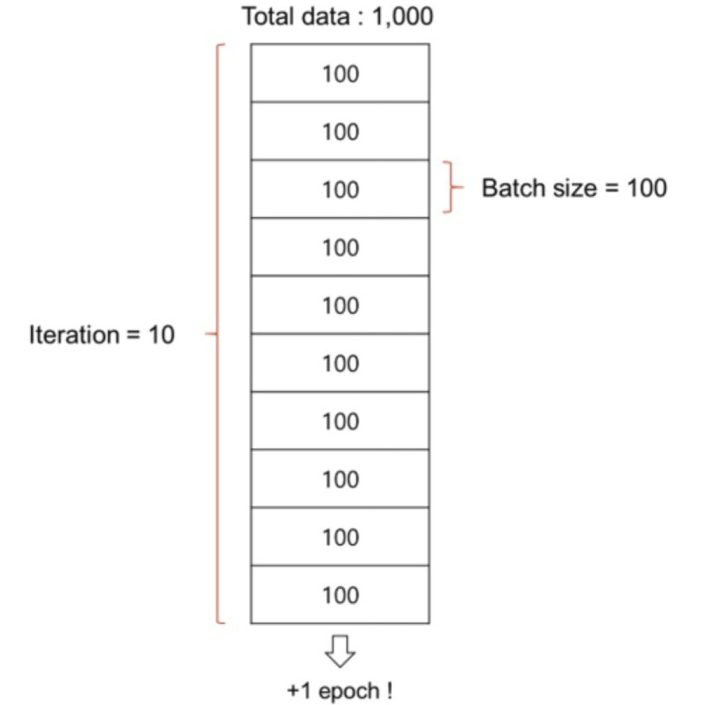
쉽게 이해하기 위해 그림과 함께 살펴보면,
epoch는 학습하는 횟수이고 batch_size는 학습 데이터의 개수이다.
-
epoch 값이 높을 수록 다양한 무작위 가중치를 학습하며,
적합한 파라미터를 찾을 확률이 올라간다.(즉, 손실 값이 내려간다.)
그러나, 지나치게 값을 높이면 그 학습 데이터셋에 oberfitting이 되어
다른 데이터에 대해선 제대로 된 예측을 못할 가능성이 있다. -
batch_size 값이 너무 크면 한번에 처리해야 할 데이터 양이 많아져서
학습 속도가 느려지고, 메모리 부족 문제가 발생할 수 있다.
그러나 값이 너무 작으면 적은 데이터를 대상으로 가중치를 업데이트하고,
이 업데이트가 자주 발생해 훈련이 불안정해진다.
그래서 손실 함수를 줄이면서 가중치를 업데이트할 수 있는 적합한 값을 찾아야한다.
학습된 결과를 살펴 보면 epoch는 5번 모두 실행되었고,
accuracy는 5번째가 0.9882로 가장 우수하다.
loss도 5번째가 0.0386으로 손실이 가장 낮다.

테스트 데이터셋으로 test_loss와 test_acc를 모델의 성능을 평가해보니,
손실 값이 0.0626, 정확도는 0.9809임을 나타낸다.
이 학습된 신경망 모델은 약 98.1%의 정확도를 보이며, 숫자 인식 분류 문제에서 좋은 성능을 내는 모델이다.
