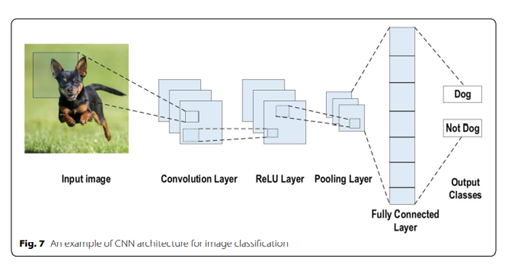
 Input image가 주어지면 Convolution Layer를 통해 특징을 추출한다.
Input image가 주어지면 Convolution Layer를 통해 특징을 추출한다.
이때 filter를 사용해서 특징을 추출한다.
Filter를 input image에 적용하는 방식이 convolution이라고 한다.
Filter를 일정한 간격으로 이동시키면서 연산을 하는데 이때 나온 결과를 feature map이라고 한다.
// 일정한 간격을 stride라고 하는데 주는 값에 따라 이동하는 간격을 정해줄 수 있다.

왼쪽 stride 1 , 오른쪽 stride 2
그런데 이렇게 나온 feature map은 filter를 적용하기 전보다 작아지게 된다.
이러한 현상을 미연에 방지하고자 padding을 이용한다.
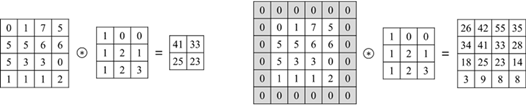 Input image에서 가장자리에 특정 값으로 설정된 픽셀을 추가함으로써 입력 이미지와 출력 이미지 크기를 같거나 비슷하게 만든다.
Input image에서 가장자리에 특정 값으로 설정된 픽셀을 추가함으로써 입력 이미지와 출력 이미지 크기를 같거나 비슷하게 만든다.
주로 0값을 가장자리에 추가한다.
이제 feature map이 추출되면 activation function을 적용한다.
Filter를 여러 번 사용하면 그 만큼 데이터끼리의 폭이 커질 것인데 이 폭을 어느정도 조절하여 비선형값으로 바꾸어 주는 역할을 한다.
이렇게 나온 결과를 activation map 이라고 한다.
Activation map에서 Pooling layer를 거치게 되면서 이미지 크기도 줄이고 특정한 feature를 강조하게 된다.
// 이미지 크기를 계속 유지한다면 비용이 크게 발생
이 작업을 sub-sampling이라고 한다.
이때는 주로 max pooling 기법을 사용하여 구한다.
이렇게 layer를 거쳐서 나온 feature들을 이용해 fully connected layer로 분류작업을 한다.
그리고 나온 결과를 이용하여 최종적으로 Dog와 Not Dog일 확률을 구하게 된다
Inductive bias
지금까지 만나보지 못했던 상황에 대해서 사용하는 추가적인 가정이다.
Filter의 크기와 개수를 정의할 때는 임의로 사람이 정할 수 있게 되는데 이때 크기와 개수를 정하는 기준에 따라 특정 상황에 맞는 학습 정확도가 달라지게 된다.
즉 inductive bias라 볼 수 있게 된다.추가적으로 Pooling 작업과 activation 함수를 적용 시키는 것도 inductive bias로 볼 수 있는데
많은 Layer를 거치게 만들 수록 일반적인 feature만 부각되어서 마찬가지로 예측 못하는 feature에 대해서는 학습 정확도가 떨어지게 된다.
즉 inductive bias는 일반적인 상황과 예측 못하는 상황의 중간 점을 적절히 선택하여 학습시키는 것이 중요하다.
