수료식 전날, 봉인해제
오늘은 전반적으로 여유로운 하루를 보냈다. 일단 오전에 대전으로 내려왔는데 3일만에 비가 좀 잠잠해져서 편히 내려올 수 있었다. 어제랑 엊그제는 진짜 비가 너무 많이와서 도저히 내려갈 엄두가 나지 않았지만...... 그런데 막상 대전 도착하니까 비가 쏟아지는게 함정이다. 대전에 내려와있는 다른 친구에게 들어보니, 이번엔 충청지역 호우경보란다. 비를 따라다니네, 내가.
어찌되었든 간에 오랜만에 느끼는 여유, 참 좋다. 얼마만에 느끼는 편안함인지 모르겠다. 프로젝트가 진행되는 5주 동안, 일요일마다 쉬기는 쉬었지만 항상 머릿속에서는 더 좋은 성과를 내기 위해 끊임없이 고민했다. 막판에는 더 많은 기능개발을 맡았다가 잠을 줄이고 운동시간도 따로 내지 못해서, 체력이 많이 떨어진 것 같다. 프로젝트가 끝난 날, 1시간이 채 지나지 않아 이력서와 자기소개서를 화요일까지 내야 한다는 공지를 받고 바로 작업을 시작했다. 그래서 오늘에야 여유가 생겼다. 내일 수료식이라는게 실감나지 않는다.
온전하게 나만의 시간을 보낼 수 있게 된 오늘 오후, 나는 그토록 좋아하던 농구를 했다. 세무조사 때도 어떻게든 시간을 내서 새벽에라도 농구공을 잡았던 내가, 이번 프로젝트 기간에는 농구공을 한 번도 잡지 않았다. 그만큼 이번 프로젝트를 내가 중요하게 생각했고, 애정을 많이 쏟았다는 것이겠다. 그리고 오늘 봉인해제를 했다. 카이스트 스포츠 컴플렉스에 가서, 3시간 동안 슛 연습을 하는데 너무 행복했다.
돌아와서 저녁을 먹으며 오늘 하루는 아예 쉴까 잠깐 고민했다. 하지만 나와의 약속을 지키기 위해 오늘도 알고리즘 문제를 하나 풀어보았다. 너무 쉬워서 금방 풀더라도, 문제를 풀기위해 생각하고 고민함으로써 뇌가 활기를 잃지 않을 테니까! 그리고 이렇게 TIL을 적음으로써 나의 루틴을 유지할 수 있는 것에도 의의가 있다고 생각했다.
알고리즘
프로그래머스 - 내적
오늘 풀어본 문제는 '내적' 이라는 문제였다.
어제와 마찬가지로 '오늘의 연습 문제'라고 뜨는데 내가 아직 풀어보지 않았길래 시작했다.  문제는 간단하다. a와 b라는 1차원 배열이 2개 주어지고, 각 배열의 n번째 인덱스끼리 곱해주는 함수를 작성하기만 하면 되었다. 물론 푸는데는 20초가 채 걸리지 않았다. 대신 이번 문제는 단순히 푸는 것을 넘어, 어떻게 풀이하는 것이 가장 좋을지도 고민해보았다. 그래서 다음과 같이 2가지 풀이를 생각해봤는다.
문제는 간단하다. a와 b라는 1차원 배열이 2개 주어지고, 각 배열의 n번째 인덱스끼리 곱해주는 함수를 작성하기만 하면 되었다. 물론 푸는데는 20초가 채 걸리지 않았다. 대신 이번 문제는 단순히 푸는 것을 넘어, 어떻게 풀이하는 것이 가장 좋을지도 고민해보았다. 그래서 다음과 같이 2가지 풀이를 생각해봤는다.
풀이 1
def solution(a, b):
answer = 0
for n1, n2 in zip(a,b):
answer += n1 * n2
return answer첫 번째 풀이는, 그냥 for 문으로 푸는 것이었다. O(N) 시간복잡도로 푸는 것이 가장 빠를 것이라고 생각했기 때문이다. 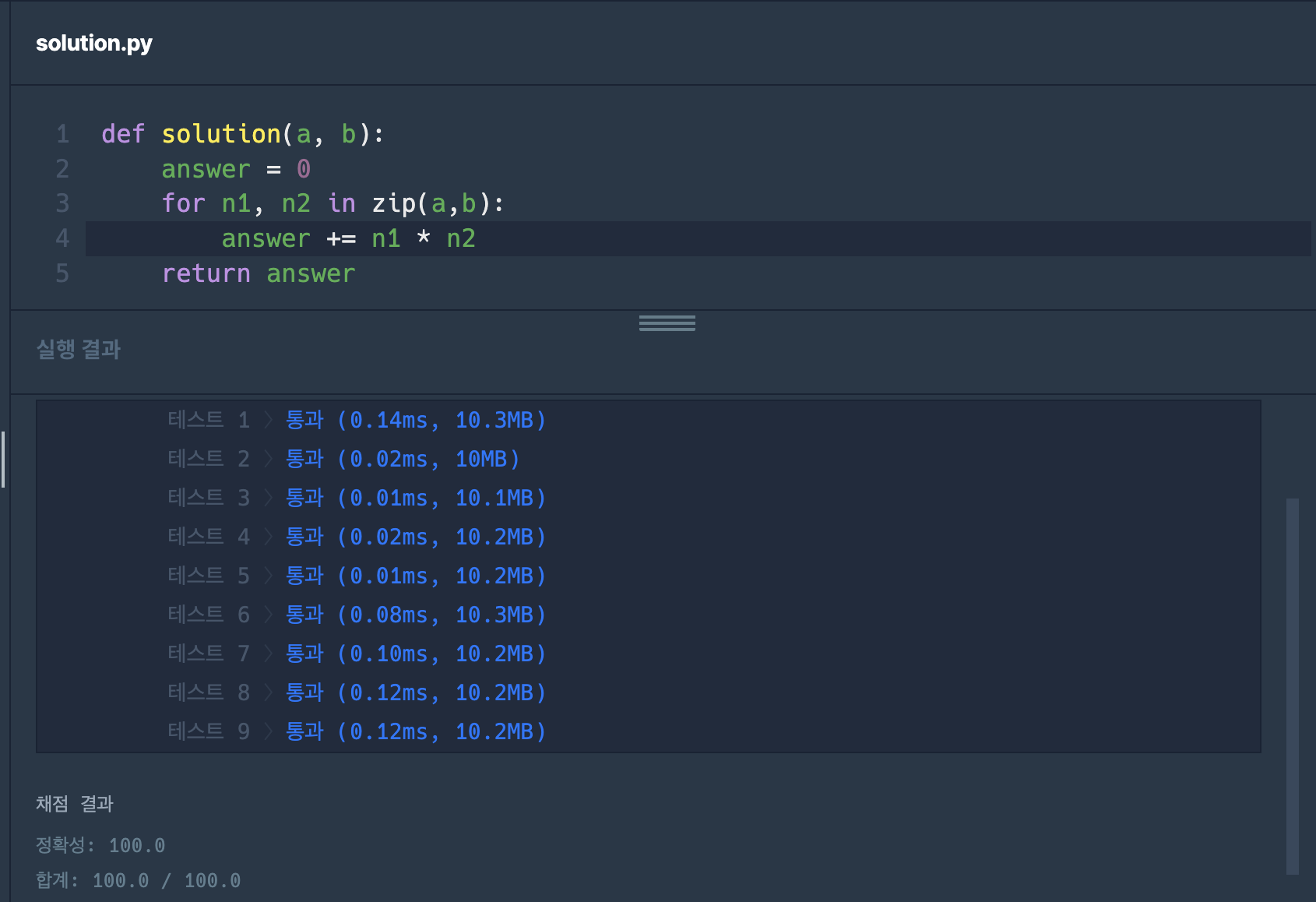
풀이 2
def solution(a, b):
return sum([n1*n2 for n1,n2 in zip(a,b)])두번째 풀이는 List Comprehension으로 짧게 푸는 것이었다. 내 생각대로라면 이 풀이는 짧을지언정 더 빠를수는 없다고 생각했다. 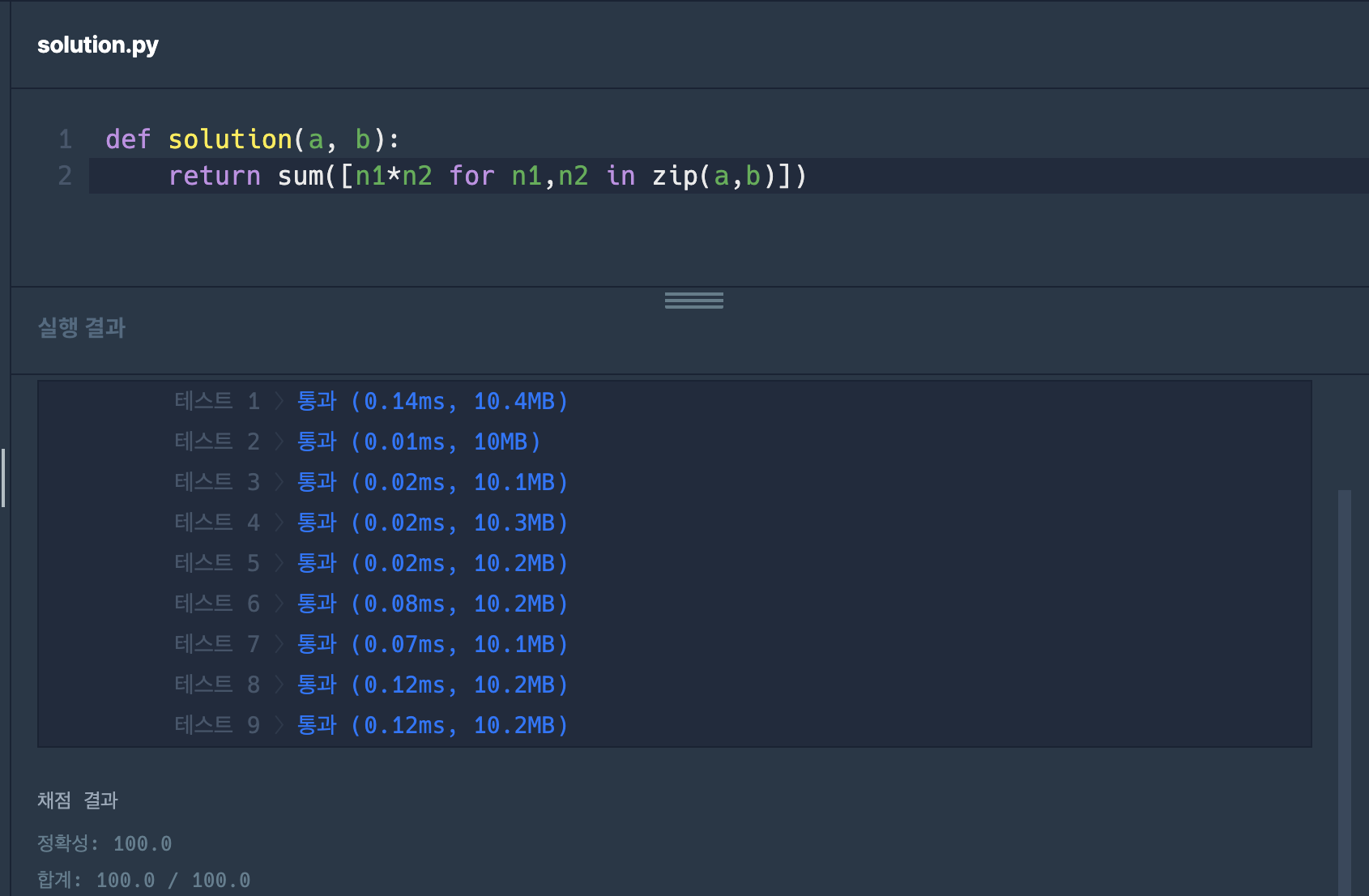
근데 보다시피, 풀이 2가 풀이 1에 비해 전혀 느리지 않다. 오히려 테스트 7은 0.03ms 더 빠르다. 물론 이 실행 결과라는게 그때그때 같은 코드에 대해서도 약간씩 다르게 나타나기도 하지만, 납득이 잘 되지 않았다.  Python sum() – A Simple Illustrated Guide 라는 글을 보면, 그냥 iterable의 원소 수에 선형비례한다고 설명하고 있다. 참고로 파이썬 공식 문서에 따르면 iterable은 한 번에 하나의 멤버를 리턴해줄 수 있는 객체를 일컫는다.
Python sum() – A Simple Illustrated Guide 라는 글을 보면, 그냥 iterable의 원소 수에 선형비례한다고 설명하고 있다. 참고로 파이썬 공식 문서에 따르면 iterable은 한 번에 하나의 멤버를 리턴해줄 수 있는 객체를 일컫는다.  공식 문서에 있는 sum에 대한 설명을 봐도, iterable의 아이템을 왼쪽에서 오른쪽으로 순회하며 합친 total을 반환해준다고 되어있다. 하나하나 순회하니까 for문을 적용할 때와 같은 O(N) 방식이라고 할 수 있겠다.
공식 문서에 있는 sum에 대한 설명을 봐도, iterable의 아이템을 왼쪽에서 오른쪽으로 순회하며 합친 total을 반환해준다고 되어있다. 하나하나 순회하니까 for문을 적용할 때와 같은 O(N) 방식이라고 할 수 있겠다.
이렇게 봤을 때, 풀이 1과 풀이 2는 비슷한 성능을 지닌 것으로 추정된다. 풀이 1에서 'answer'라는 변수의 값을 업데이트하며 소요되는 cost와 풀이 2에서 새로운 리스트를 구성하는 cost가 비슷비슷한 것일까? 이 문제에서는 주어진 배열의 길이도 짧고 숫자 범위도 좁아서 비슷한 성능을 내는 것 같은데, 조건이 더 까다로운 문제에서는 서로 어떤 퍼포먼스를 보여줄지 정말 궁금하다. 효율성까지 체크하는 문제 중에 비슷한 문제가 있다면, 한번 2가지 방식을 둘 다 적용해보고 결과를 확인해봐야겠다.
