
CS231n 4강

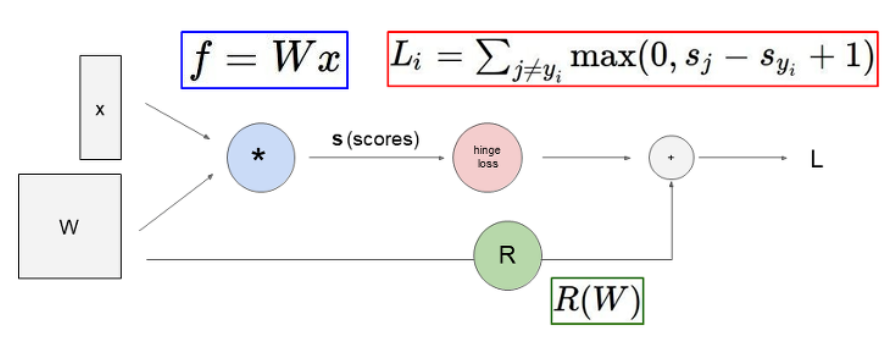
앞서 배운 식을 computational graph로 만든 것이다.
역전파(Backpropagation)는 input에 대한 gradient를 얻기위해 chain rule을 사용한다. 왜 input에 대한 gradient를 얻냐?? input이 마지막단에 얼마나 영향을 끼치는지 알 수 있기 때문이다.
- 함수에 대한 computational graph 만들기
- 각 local gradient 구하기
- input에 대한 gradient 구하기 (chain rule 사용)
오차역전법
예제 1
오차역전법에 대한 간단한 예제를 살펴보자.
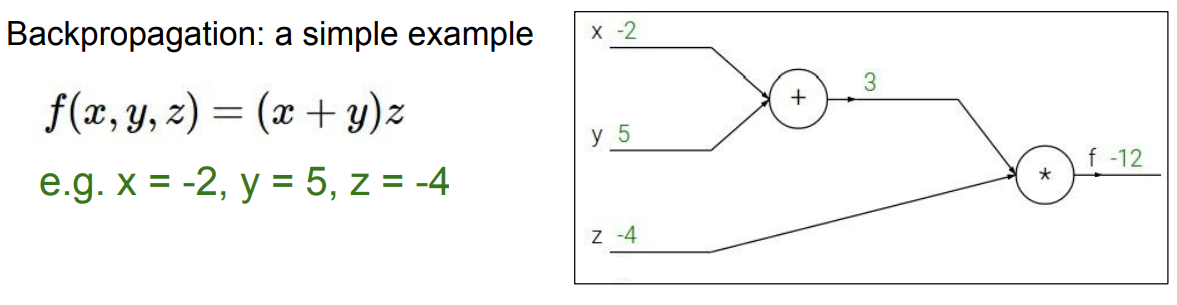
f(x,y,z)=(x+y)z라는 함수가 있고 x,y,z는 각각 -2,5,-4 라는 값을 가지고 있다. 우리는 최종적으로 input x,y,z에 대한 gradient들을 구할 것이다. 구하는 과정을 살펴보자
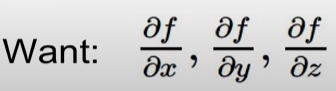
1. 먼저 forward pass로 local gradient를 구한다.
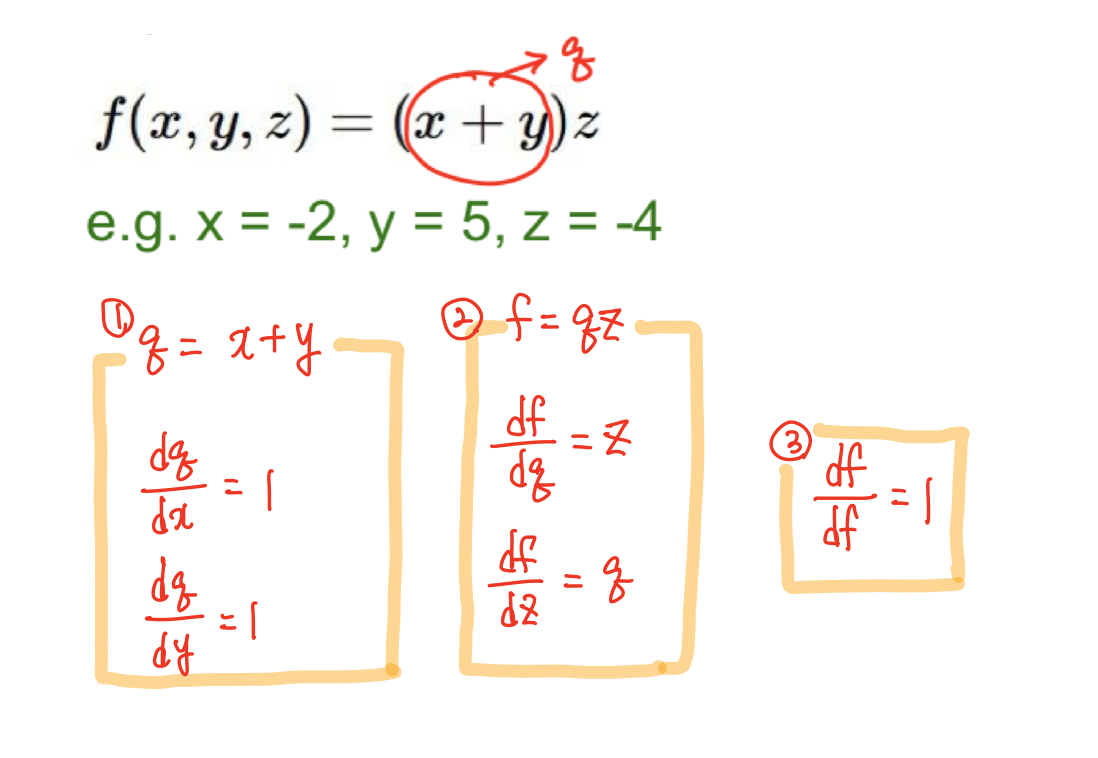
- 구해놓은 local gradient를 사용하여 input에 대한 gradient를 구한다.

이때, df/dx 와 df/dy는 어떤식으로 구해야할까??
chain rule을 이용하면 된다!!
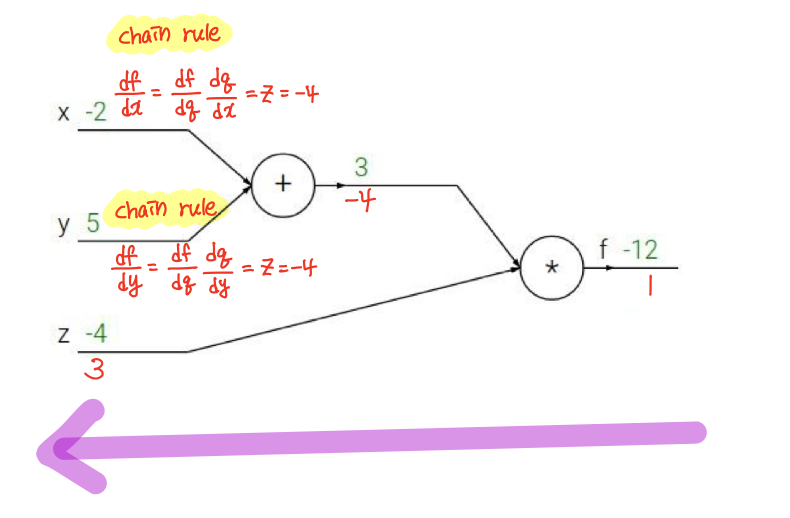
복잡한 함수라도 local gradient와 chain rule을 이용해서 gradient를 구할 수 있다.
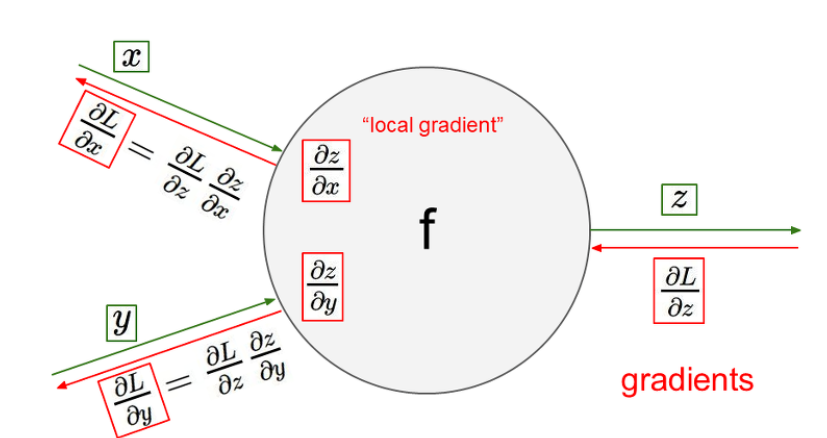
다시 한번 정리하자면
- 미리 구할 수 있는 gradient 값 ---> local gradient
- local gradient 값과 앞에 저장된 gradient 값 ---> global gradient
- gradient = local gradient * global gradient
예제 2

조금 더 복잡한 예제이다. 체감상 완전 더 어려워졌따....🙄


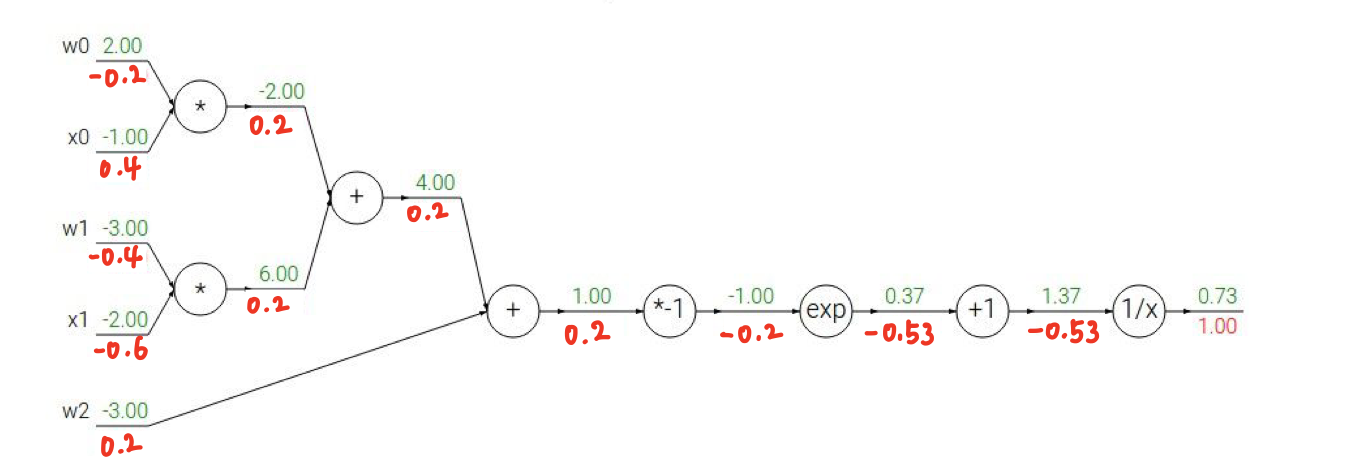
이 과정을 똑같이 계속 반복하면 이렇게 gradient를 구할 수 있다.
이때동안 하나 하나 일일이 계산해보았는데 특성을 알면 그럴 필요가 없다.
살펴보자!🤩
1. 시그모이드함수 특성을 이용하라

먼저, 파란색으로 박스 친 부분은 시그모이드 게이트이다.
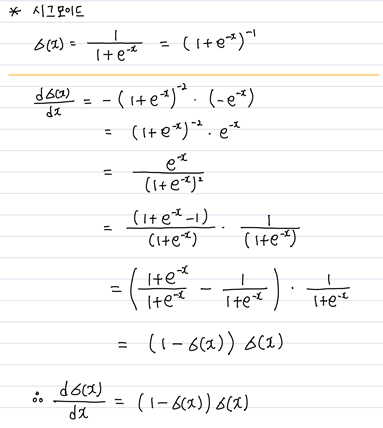
시그모이드함수를 미분하면 (1-시그모이드) * (시그모이드) 로 표현할 수 있다.

시그모이드 게이트에 들어가기전 gradient는
시그모이드값인 기준으로 (1-0.73)* 0.73 = 0.2로 바로 구할 수 있다
2. add 게이트
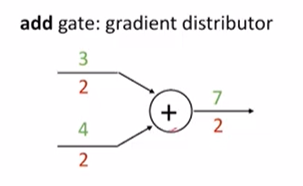
3+4 --> 7 이라는 add 게이트가 있으면
7에 있는 gradient 2를 그대로 distributor 해주면 된다.
3. copy 게이트
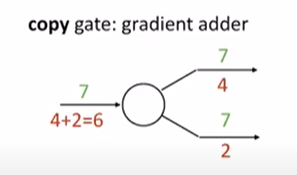
7을 그대로 copy하는 게이트가 있다면 각각의 gradient 를 adder하면 된다.
4. mul 게이트
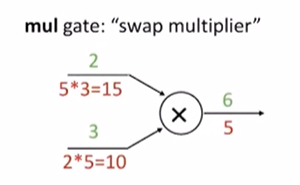
2x3 --> 6 이라는 mul 게이트가 있으면 switch해서 곱해주면 된다.
5. max 게이트
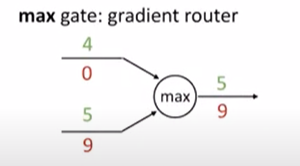
4 와 5 중에 max 값을 취해서 5를 준 max 게이트가 있으면
5에게 gradient를 주고 나머지에겐 0을 주면 된다.
사실은 왜 저런식으로 나오는지 완전히 이해를 못해서 설명을 자세히 못했는데 이런 특성들을 적용해서 간단하게 계산을 할 수 있을것같다!!😵
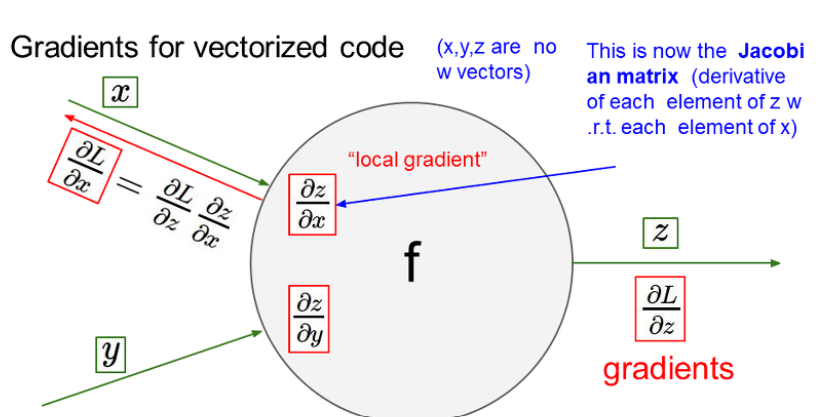
우리가 할 딥러닝은 하나의 값이 아니라 다변수일 확률이 높다.
다변수 함수일때의 미분값은 자코비안 행렬 방식으로 표현한다.

input으로 4096차원의 벡터가 들어가고 output으로도 4096차원의 벡터가 나오는 자코비안 행렬이 있다고 치자.
질문
1. 자코비안 행렬의 크기는?
4096xx4096
2. batch사이즈가 100인 미니배치를 추가하게 된다면 행렬의 크기는?
409600x409600
이 엄청난 자코비안 행렬을 실제로는 계산하지 않는다... 구조만 살펴볼 것이다.
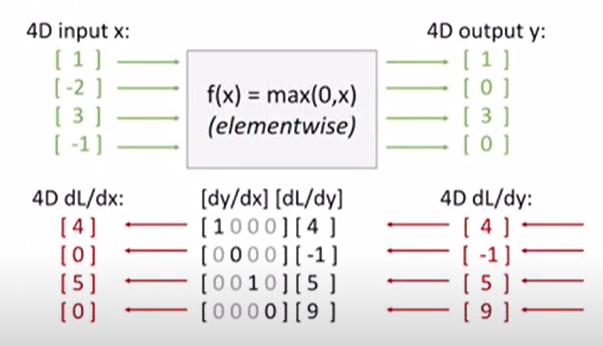
4x4 행렬이 있고 max 게이트 특성을 사용해서 gradient를 구하면 4,0,5,0 이 된 단 말씀..이때!! 자코비안 행렬을 보면 대각행렬이 된다. 첫번째 차원은 오직 출력의 해당 요소에만 영향을 주기때문에 전체에 대한 자코비안 행렬을 작성할 필요가 없다고한다ㅏㅏㅏ... 예제를 살펴보면서 이해해봐야겠다.
예제 3

x는 n차원
W는 nxn차원
x와 W를 곱해서 L2규제 마냥 제곱을 한 함수가 있다.
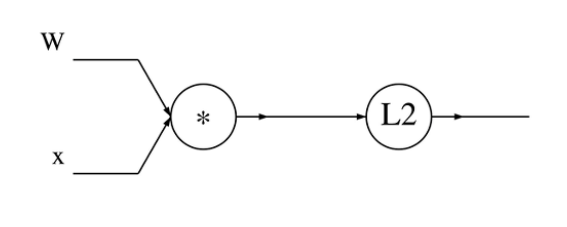
위의 식에 대한 computational graph를 그렸다.
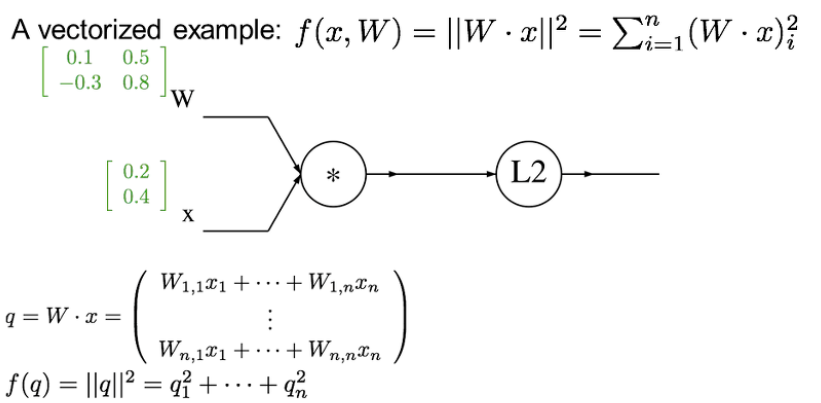
W와 x의 행렬이 저런식으로 있다고 치자.
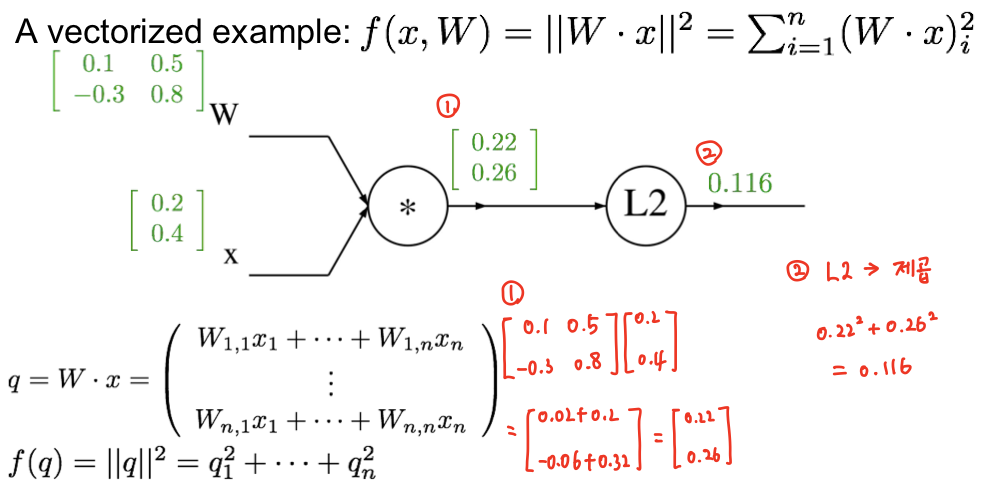
하나씩 계산을 해주었다.
이제 local gradient와 global gradient를 이용하여 gradient를 하나씩 구해보자!!
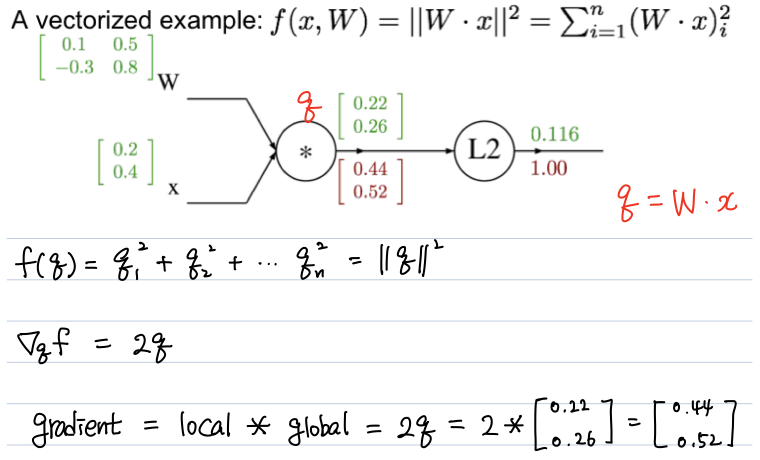
local gradient는 2q
global gradient는 1
--> gradient는 각각의 행렬값에 2를 곱한거나 마찬가지

이런식으로 구해주면 된다
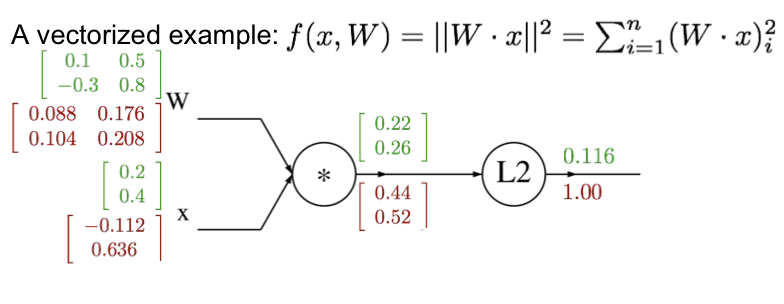
최종 결과
주의할 점은 벡터의 gradient는 항상 원본 벡터의 사이즈와 같다는것!!
검산시 꼭 확인하자

곱셈 게이트에 대한 forward 와 backward의 파이썬 구현을 보면서
계산 가득했던 4강의 Backpropagation을 마치겠따...🤯🤯
