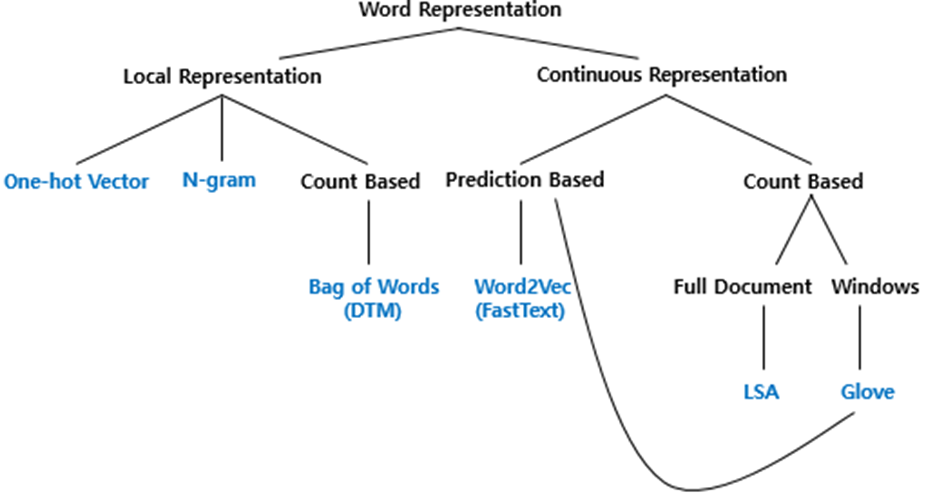
단어 표현에는 두가지 방법이 있다.
1. Local Representaion (이산표현=국소표현=희소표현)
2. Continuous Representaion (분산표현=연속표현=밀집표현)
분산표현
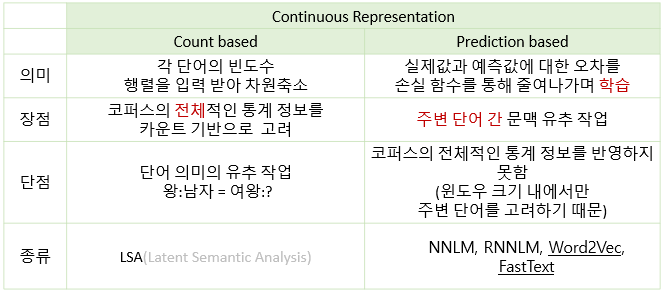
분산표현에는 크게 2가지 방식이 있다.
1. count based
2. Prediction based
⭐이번 포스팅에서는 Predicion based 부분에 대해 전체적인 개념의 흐름을 다루겠다
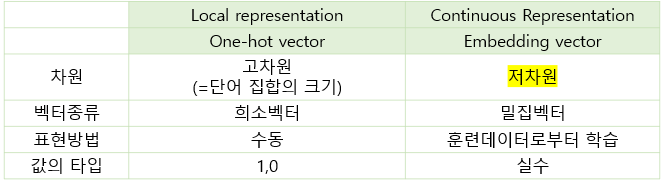
단어를 원핫인코딩을 통해 원핫벡터로 나타내는 것의 한계
- 단어 간의 유사도 표현 불가
- 차원이 무한대로 늘어나 저장 공간 측면에서 비효율적
이를 해결할 수 있는 방법은 단어를 밀집벡터로 표현하는 것이다.
이를 바로 워드임베딩이라고 한다.
단어를 워드임베딩하여 만든 벡터를 밀집벡터 혹은 임베딩벡터라고 칭한다.
| 종류 | 설명 |
|---|---|
| NNLM(Feed Forward Neural Network Language Model) | 단어 벡터 간 유사도를 구할 수 있도록 인공신경망을 사용한 word embedding 방법이 처음으로 사용된 모델 |
| Word2Vec | 워드 임베딩 자체에 집중하여 NNLM의 느린 학습 속도와 정확도를 개선 |
| FastText | 하나의 단어를 쪼개서 subword에 대해 학습 |
Projection layer:차원의 감소
임베딩벡터의 포인트는 원핫벡터와 달리 차원을 저차원으로 나타낸다는 것이다.
과연 어느 과정을 통해 단어가 저차원 벡터로 표현된다는 것일까?
바로 Projection layer에서 차원의 감소가 일어난다.
이해하기 쉽게 nnlm의 구조를 도식화 해보자면
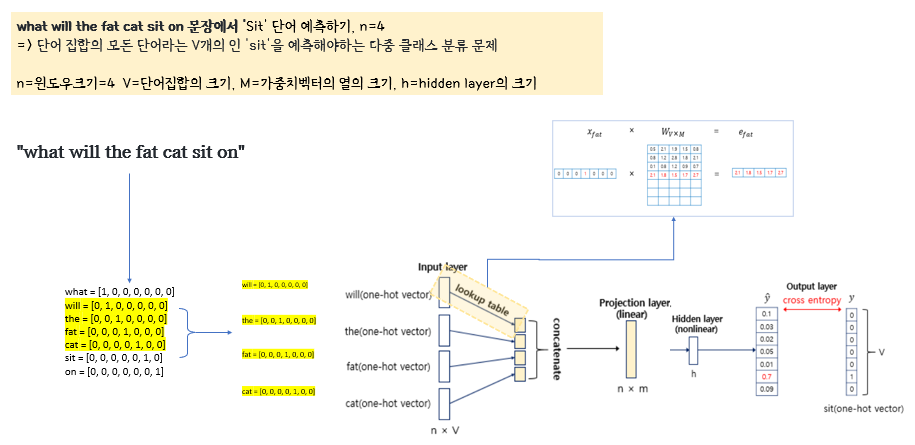
input layer에서 projection layer로 갈 때 가중치행렬과의 look up과정을 거치면서 차원이 감소한다.
과정을 확대해보면
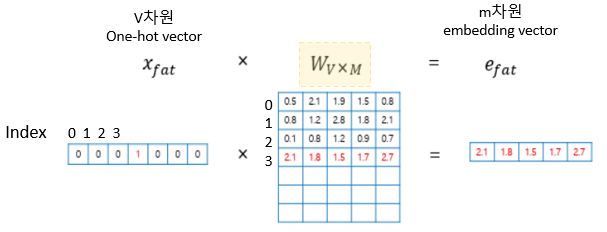
다음과 같이 가중치 행렬과의 곱이 이루어진다.
그런데 '곱'의 과정이긴 한데, 단어벡터가 원핫벡터로 이루어져있으니 실질적으로는 가중치벡터값을 그대로 가져올 뿐이다. 그래서 이를 look up 이라고 한다.(엑셀의 lookup함수같은 기능)
이 과정을 통해 V차원(전체 단어의 크기)을 가지는 원핫벡터에서 M차원의 벡터로 맵핑되는 것이다.
임베딩벡터들은 처음에는 랜덤한 값을 가지지만 학습을 통해 값이 갱신된다.
