Intro
- Word2Vec은 단어 표현 방법 중 밀집벡터로 나타내는 방법 중 하나이다.
- 밀집벡터로 나타내면 단어를 벡터로 표현할 때 저차원으로 표현할 수 있다.
- 밀집벡터로 나타내면 단어간의 유사도를 반영할 수 있다.
단어 벡터 간 유사도를 반영할 수 있는 이유
- Word2Vec은 ‘비슷한 문맥에서 등장하는 단어들은 비슷한 의미를 가진다’는 가정 하에 만들어진 표현 방법
- 분포 가설을 이용해 텍스트를 학습하고, 단어의 의미를 벡터의 여러 차원에 분산하여 표현
⭐ Word2Vec은 word를 다차원 벡터(vector)공간에 표현하여 벡터간의 유사도를 계산할 수 있게 하는 방법이다.
Word2Vec 학습방식
Word2Vec은 학습방식에 따라 2종류로 나뉜다.
구조를 통해 알 수 있듯이 학습방식이 정반대이다.👀
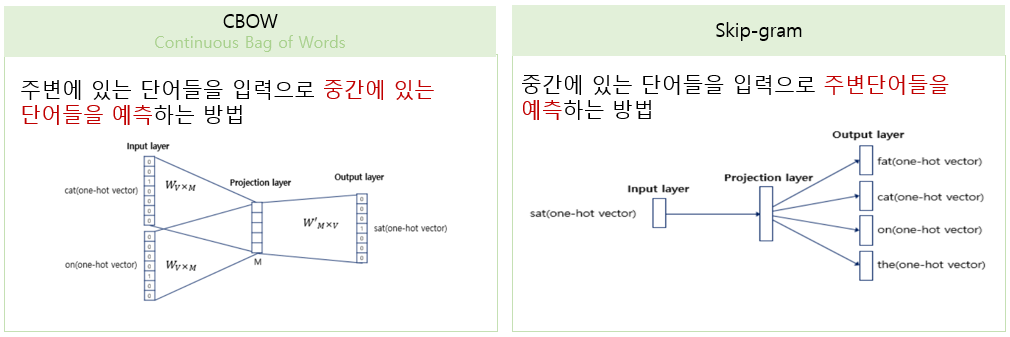
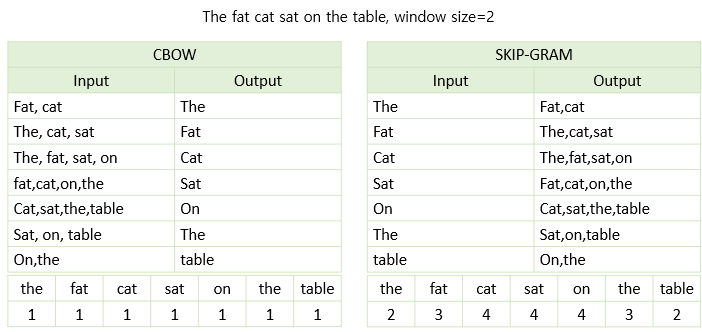
우선 두 방법의 차이를 예시문장 The fat cat sat on the table 이라는 문장을 통해 직관적으로 이해해보도록 하자!😺
CBOW
- CBOW는 주변단어(초록단어)들로 중심단어(빨간단어)를 예측하는 방법이다.
여기서 주변단어의 갯수를 몇개로 설정할 것인지는 정하기 나름이다.
중심단어로부터 떨어진 거리만큼을 window size라고 하는데
사용할 단어의 갯수 = 2*window size 이렇게 이해하면 된다.
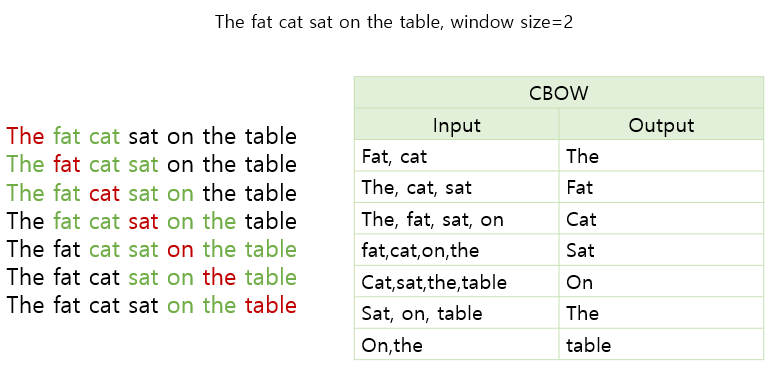
CBOW 구조
window size=2 이고 sat을 예측할 때의 구조를 뜯어보자!
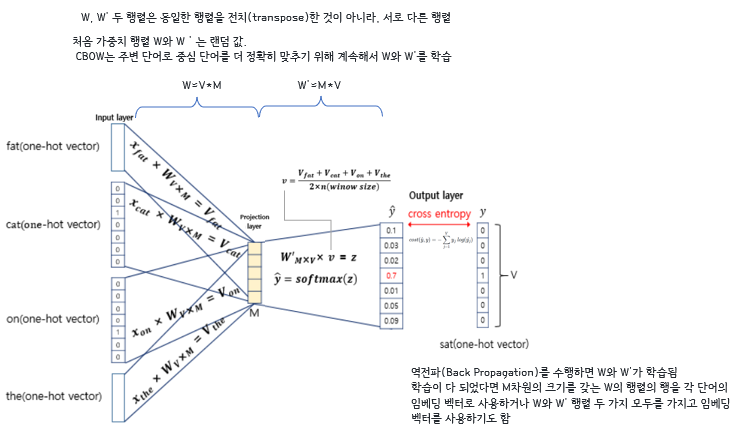
projection layer를 기준으로 가중치벡터와 단어벡터를 곱해준다.
Point
projecton layer를 기준으로 가중치벡터와 단어벡터의 곱이 이루어진다.
- ⭐두 가중치 행렬은 전치관계가 아니라 서로 다른 행렬임
- ⭐
projection layer과정에서 차원의 축소가 발생- 4개의 단어벡터가 1개의 단어벡터 사이즈로 감소하기 때문에
projection layer-> outputlayer에서 이루어지는 곱은 단어벡터들의 평균값이다.- 역전파과정을 통해 가중치벡터 W,W'가 학습되고 이를 임베딩벡터로 사용한다.
💛꿀 TMI
나는 처음에 이런 구조를 뜯어보는 것에 대한 일종의 거부감이 있었다.
복잡하고.. 막상 구현은 코드 한 줄인데 어디까지 알아야 하는건가 싶고!
그런데 강약포인트를 조절해서 본다는 마인드로 접근하니 좀 부담감이 줄었다.
처음부터 마스터하겠다는 마인드보다는, 어디 부분이 가장 중요할까? 어디 부분이 다른 부분과 비교했을 때 다를까? 이런식으로 마음속에 이 공부를 통해 알고 싶은 포인트를 설정해서 뽑아가겠다(!)는 마인드로 접근하니 효과적이었다.
+'이걸 어떻게 쉽게 전달할 수 있을까?'라는 마인드도 좋았다. 사내 세미나를 위해 준비한 토픽이었는데, 다양한 롤의 사람들에게 모두 뭔가 남도록 하려면 어디 부분을 강조하는게 좋을까? 라는 생각을 가지고 접근하니 책임감이 생겨서 더욱 열심히 보게 되었다.
Skip-Gram
- Skip-Gram은 중심단어로 주변단어를 예측하는 방법이다.
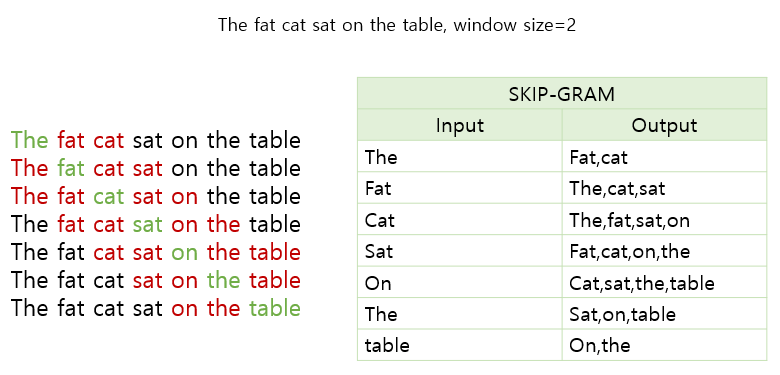
CBOW VS Skip-Gram
-
처음에는 여러개의 학습데이터를 가지고 있는 CBOW가 더 성능이 좋지 않을까?라는 생각을 했었는데, 한 단어에 대해 여러 학습의 기회를 가지는
Skip-Gram의 성능이 더 좋다고 한다. -
아래 표를 보면 학습이 된 수치를 확인할 수 있다.
-
처음에는 왜 이러한 수치가 나오는지 직관적으로 이해가 잘 안될 수 있지만!
output 기준으로 해당 단어가 몇번 등장했는지를 보면 된다.
Reference
