Part 0. 시계열이란?
- 시간의 흐름에 따라 관찰된 값들을 시계열 자료라고 한다.
- 시계열의 본질적인 특성은 크게 자기상관(auto-correlation), 추세(trend), 계절성(seasonality)이 있다.
Part 1. Stationarity란?
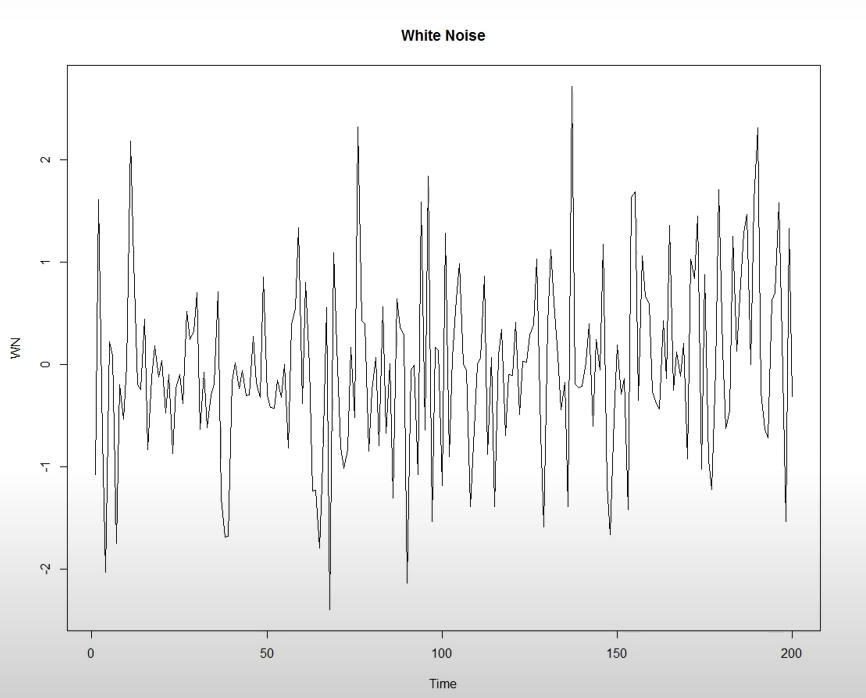
-
시계열분석을 하기 위해서는 정상성(Stationarity)을 만족해야 한다.
-
정상성이란 '시계열의 특징이 관측된 시간과 무관함'을 의미.
ex) 7일전~1일전까지의 시계열 특징이 오늘~6일후와 동일하지 않다. -
정상성은 크게
강정상성,약정상성으로 나뉜다.
-강정상성을 만족하는 경우는 대부분약정상성을 만족한다.강정상성이란 기저를 이루는 확률분포가 언제가 같아야한다는 것이다- 이는 현실에 적용하기 쉽지 않다. 따라서 실생활에서 말하는 정상성이란
약정상성이다.
정상성의 조건
- 평균이 일정
- 분산이 일정
- 두 시점 사이의 자기공분산(Autocovariance)은 시차(time lag)에만 의존
* 자기공분산 = 서로 다른 2개의 시간에 대한 변수 값의 공분산
ex) 평균은 일정하지 않으나, 분산이 일정한 경우
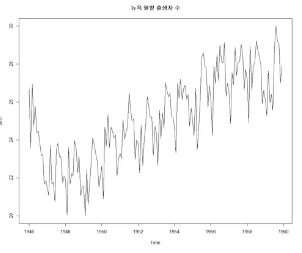
ex2) 평균도 일정하지 않고 분산도 일정하지 않은 경우
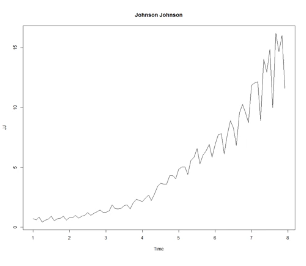
💡하지만, 생각보다 약정상성을 만족하는 경우도 많지 않다.
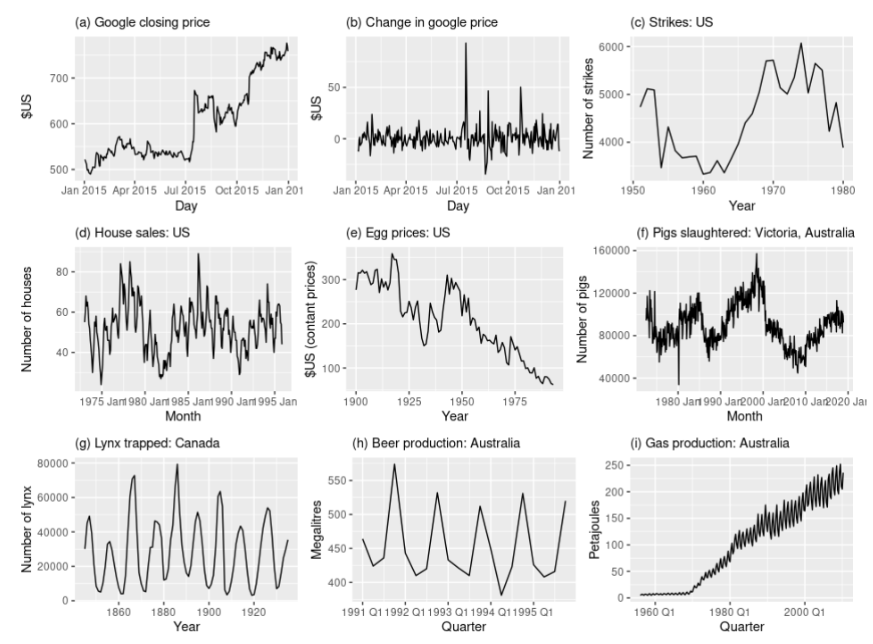
- 추세, 계절성이 있는 경우 관측시점에 따라 특성이 바뀌기 때문에
정상성을 만족한다고 볼 수 없다. - 추세를 보이는 경우는 a,c,e,f,i이다.
- 계절성을 보이는 경우는 d,h이다.
- b의 경우 분산이 안정적이지 못하다.
- 결국 이 중에서 정상성을 만족하는 시계열은 g 뿐이다.
비정상성 시계열의 특징
- 추세가 있음
- 계절성이 있음
- 분산에 변동이 있음
💡샘플 예시처럼 시각적으로 분류가 가능한 경우도 있겠지만, 실제 데이터 상에서는 육안으로 확인하기 '애매'할 경우가 분명 존재할 것이다.
정상성 만족 기준을 판단하는 방법
- ACF plot을 통한 판단
- ACF plot이 규칙성없이 있는 경우 '정상성'을 만족시킨다고 할 수 있음.- 검정을 통한 판단 (이 포스팅에서는 검정방법에 대한 자세한 내용은 다루지 않겠다)
- KPSS 검정
- ADF 검정
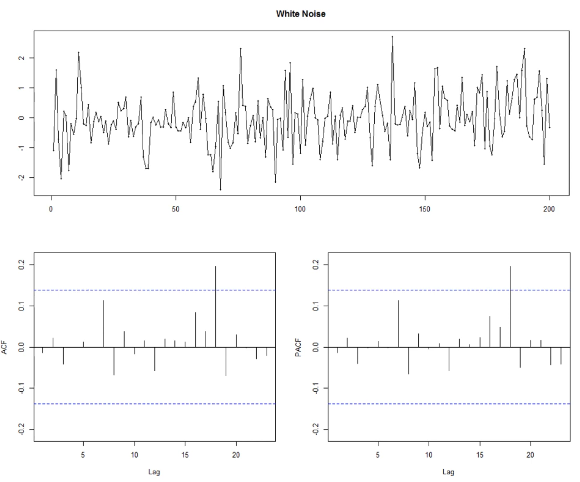
- Lag=1 : 시점차이가 1이라는 뜻. t시점의 값-(t-1)시점의 값.
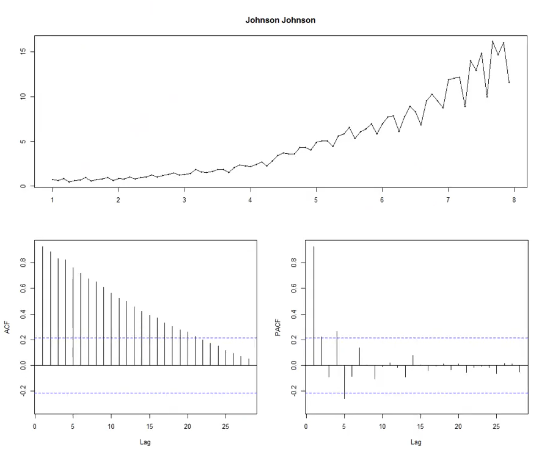
ACF가 감소하는 패턴이 보인다 -> 비정상성 시계열
Appendix. ACF & PACF
자기상관계수 (ACF. Autocorrelation Coefficient)
- 시점 t와 시점 (t+k)의 (k기간 떨어진 값)들의 상관계수
= 시점 t에서의 값과 (t+k)시점에서의 값이 얼마나 상관있는지를 나타낸 값
부분 자기상관계수 (PACF.partial autocorrelation coefficient)
서로 다른 두 지점 사이의 관계를 분석할 때 중간에 있는 값들의 영향을 제외시킨 상관관계 개념
== 시점 t에서의 값과 (t+k)시점에서의 값이 얼마나 상관있는지를 시점 사이의 간접적인 상관성을 제외하고 나타낸 값
- ACF VS PACF
https://youtu.be/5Q5p6eVM7zM?si=EEPcvalJaeH-6RGO
정상성을 만족하는 시계열로 만드는 방법
-
평균이 일정하지 않은 시계열은 차분(differencing)을 통해, 분산이 일정하지 않은 경우는 변환(transformation)을 통해 정상화할 수 있다.
-
회귀분석(regression)
- residual을 통해 추세와 계절성 제거 -
평활법(smoothing)
-
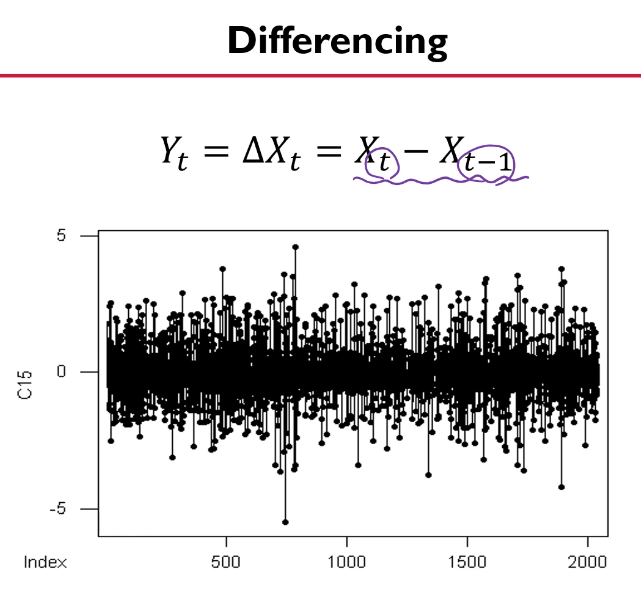
차분(differencing)
차분?
- 현시점 자료에서 전 시점 자료를 빼는 것을 의미

-
시간 t일 때의 값 - 시간 (t-1)일 때의 값
-
정상성(Stationary)을 만드는 방법 중 하나
-
차분에 대해서는 뒷부분 ARIMA파트에서 다시 다룬다.
Part 2.시계열 자료 분석방법
시계열 자료 분석방법
- 수학적 이론모형 : 회귀분석(계량경제)방법, Box-Jenkins 방법
- 직관적 방법 : 지수평활법, 시계열 분해법으로 시간에 따른 변동이 느린 데이터 분석에 활용
- 장기예측 : 회귀분석방법 이용
- 단기 예측 : Box-Jenkins 방법, 지수평활법, 시계열 분해법 활용
이동평균법(Moving Average)
- 다음 기간에 대한 예측값을 일정 기간별 평균값을 활용하는것
ex) 1/6에 대한 값은 1/1~1/5의 값의 평균, 1/7에 대한 값은 1/2~1/6의 값의 평균 ...
이동평균법의 특징
- 특정 기간 안에 속하는 시계열에 대해서는 동일한 가중치를 부여
- 일반적으로 시계열 자료에 뚜렷한 추세가 있거나 불규칙 변동이 심하지 않은 경우에는 짧은 기간의 평균을, 불규칙변동이 심한 경우에는 긴 기간의 평균을 사용
- 이동평균법에서 가장 중요한 것은 적절한 기간을 사용하는 것.
지수평활법 (Exponential Smoothing Method)
- 일정 기간이 아닌 모든 시계열 자료를 사용해 평균을 구하며, 시간의 흐름에 따라 최근 시계열에 더 많은 가중치를 부여해 예측
지수평활법의 특징
- 단기간에 발생하는 불규칙 변동을 평활하는 방법
- 지수평활계수가 가중치의 역할을 함.
- 불규칙변동이 큰 시계열의 경우 지수평활계수는 작은 값을, 불규칙변동이 작은 시계열의 경우 큰 값의 지수평활계수 적용 (일반적으로 0.05~0.3)
Part 3.시계열 모형
*자기상관성
- p시점 전의 자료가 현재 자료에 영향을 주는 것
자기회귀모형(AR.Autoregressive model)

-
x가 y의 시점 lag된 값들로 구성됨(과거값)
-
자기 상관성을 시계열 모형으로 구성한 것
-
일반적인 multiple regression과는 다른 접근이 필요. independence assumption이 위배되므로 최소제곱법은 사용x
선형회귀를 사용하지 않는 이유
- 선형회귀 분석은 독립항등분포 데이터가 있음을 가정
시계열데이터를 최소제곱선형회귀 모델에 적용해도 되는 경우
1) 시계열의 행동에 대한 가정
2) 오차에 대한 가정
- 특정 시기의 오차는 시기에 관련없음. 오차에 대한 자기 상관함수 그래프는 패턴이 없음.
- 오차의 분산은 시간으로부처 독립적
이러한 가정이 성립된다면 보통최소제곱회귀는 주어진 입력에 대한 계수의 비편향추정량이 됨.
- AR(1) 모형: 바로 직전 데이터가 다음 데이터에 영향을 준다고 가정한 모형
- AR(2) 모형 : t-2시점의 데이터가 현재 데이터에 영향을 준다고 가정한 모형
- PACF를 통해 AR 차수 결정(AIC가 작은 모형으로 결정)
MA(Moving Average model. 이동평균모형)

-
x가 y의 시점 lag된 값의 error들로 구성됨(과거 예측오차)
-
시간이 지날수록 관측치의 평균값이 지속적으로 증가하거나 감소하는 경향을 표현한 시계열 모형
-
현시점의 자료를 유한한 개수의 오차항(백색잡음)의 결합으로 표현하기 때문에 언제나 정상성 만족
-
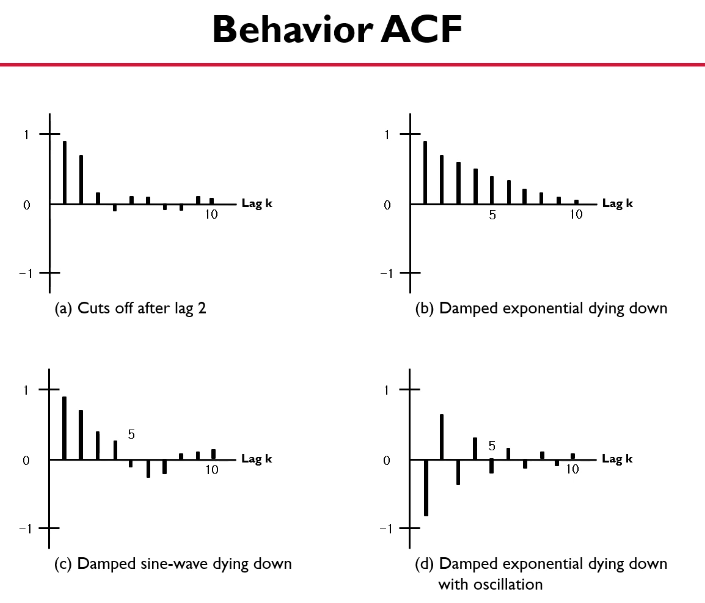
AR모형과 반대로 ACF에서 절단점을 갖고, PACF가 빠르게 감소
-
ACF를 통해 차수 결정(AIC가 작은 모형으로 결정)
-
AR VS MA

ARMA
- AR+MA

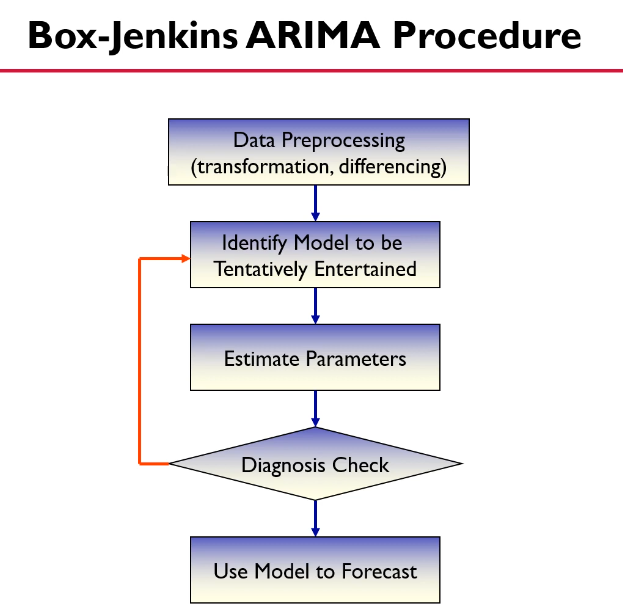
ARIMA(p,d,q)(Autoregressive Integrated Moving Average Model.자기회귀누적이동평균 모형)

-
arima 개념을 잘 이해하기 위해서는 ar,ma,arma와의 관계를 생각할 줄 알아야 한다.
-
⭐⭐⭐ ar,ma,arma 모델을 적용하기 위해서는 데이터가 정상성을 만족해야 한다.
-
하지만 실생활에서 정상성을 만족하는 케이스는 많지 않으므로, 차분 등을 통해 정상성을 만족하도록 바꿔주어야 한다.
-
이처럼 차분 후 AR / MA / ARMA 모델로 적용하는 과정을 'ARIMA'라고 하는 것이다.
-
EX) 정상성을 만족하지 않는 경우 1차/2차 차분을 통해 정상성을 만족시켜준다.
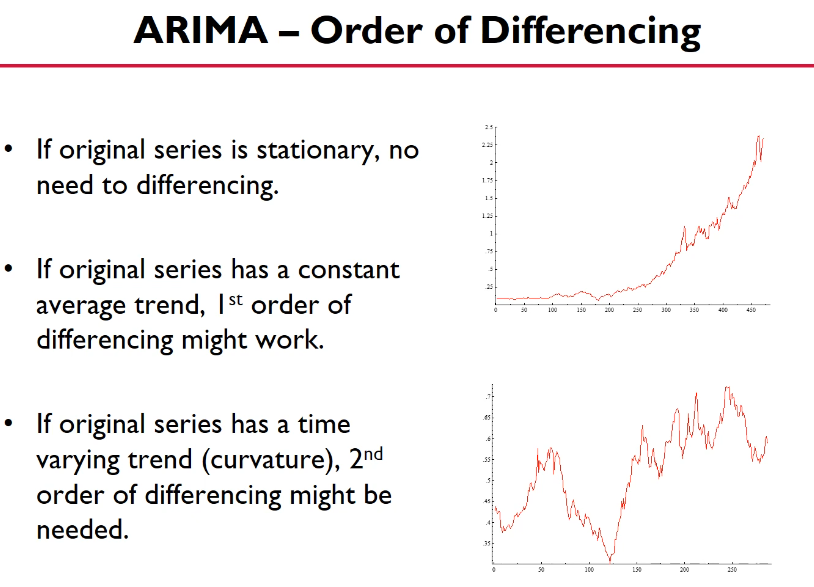
차분한 뒤 ACF를 보면서 정상성을 만족하는지 확인한다. 규칙성이 없는 것고 급증하는 경우가 정상성을 만족하는 것이다.
(p,d,q)의 의미
- ARIMA모형은 p,d,q의 세가지 차수가 있다. p는 AR모델의 독립변수의 갯수, d는 차분의 횟수, q는 MA모델의 독립변수의 갯수

- p=0일 때, IMA(d,q) -> d번 차분하면 MA(q)
- d=0일 때, ARMA(p,q).
- q=0일 때, ARI(p,d)-> d번 차분하면 AR(p)모형을 따름
- p=d=q=0일 때 -> 백색잡음(=자기상관(autocorrelation)이 없는) 시계열
백색잡음 시계열?
- p=0, d=1, q=0 일 때 확률보행
case
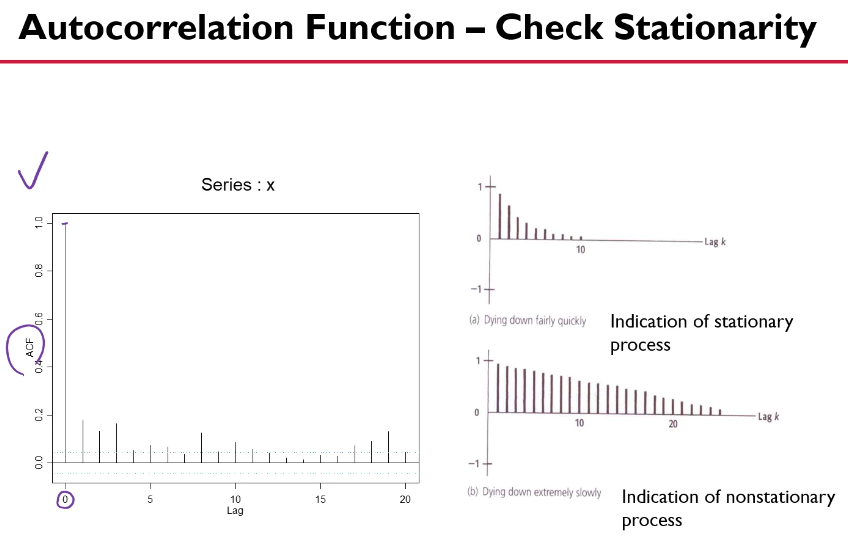
lag=0일 때는 신경 x
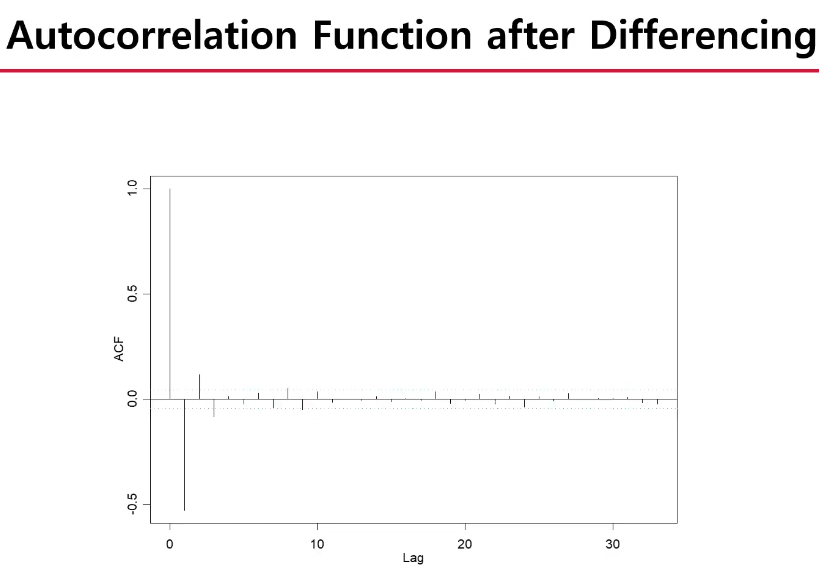
급증/감 -> 정상성 만족
언제 MA,AR,ARMA를 사용해야할까?
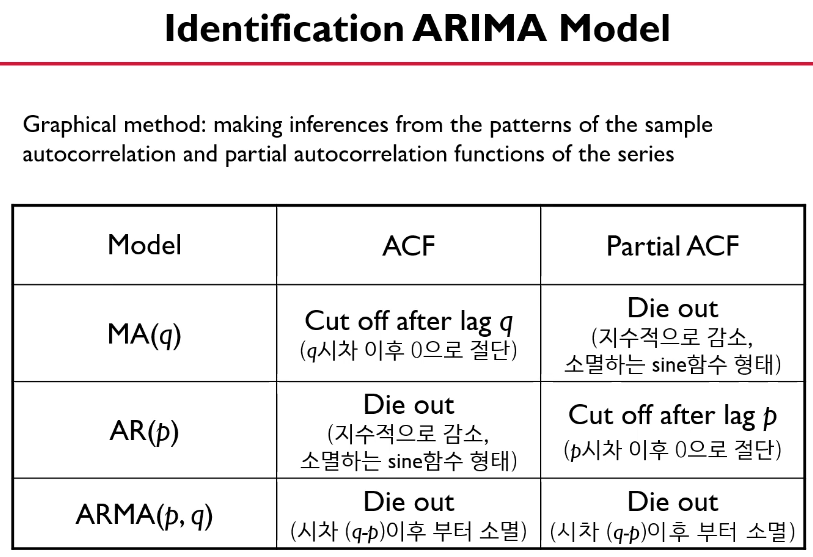
시계열데이터를 차분한 뒤 ACF, PACF를 봤을 때 ACF가 q시차 이후 0으로 절단되고, PACF가 지수적으로 감소하거나 소멸하는 sin함수 형태를 보이면 -> MA모델을 선택한다.
그런데, 해석에 있어서 주관적일 수 있음
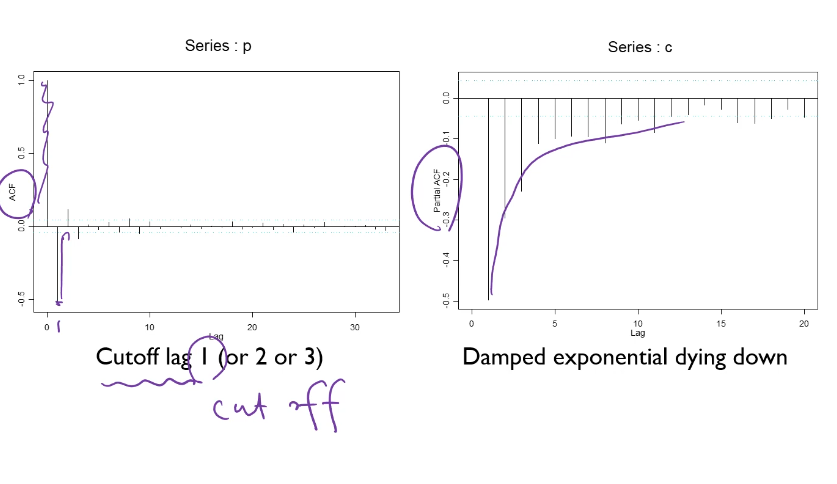
MA(1) 모델이 '우선은' 적합하다고 추정

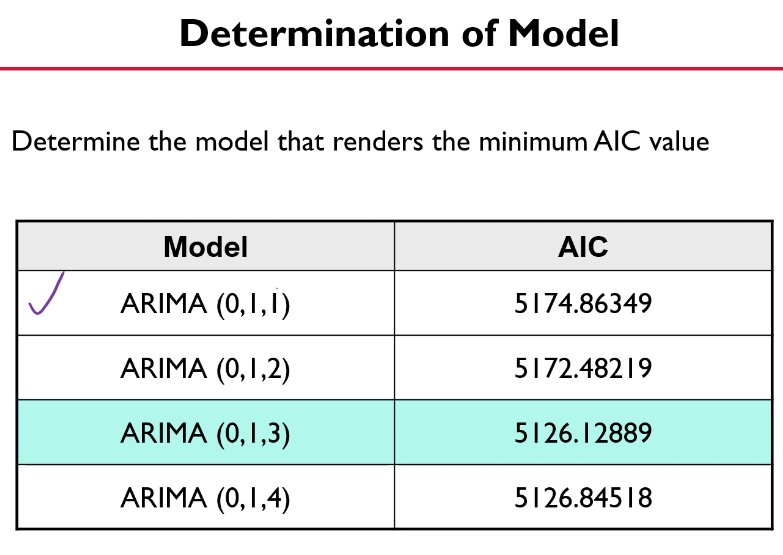
Diagnosis

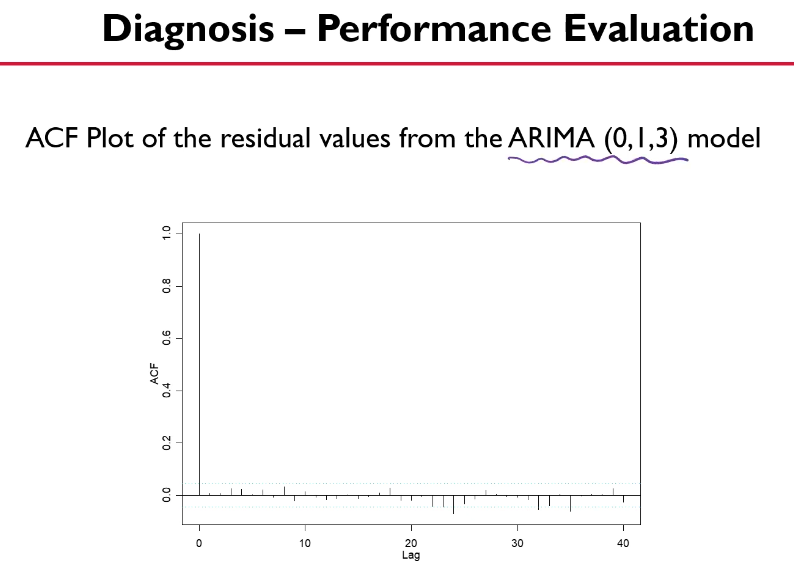
residual의 3시그마 limit
실질적으로는 d를 먼저 1 or 2로 결정하고
p= 1~20, q=1~20의 범위에서 autoarima
AIC가 가장 작은 조합을 찾는다.
SARIMA


- SARIMA의 경우 결정변수가 총 7개임
시계열 통계모델의 장단점
장점
- 모델의 파라미터확인
- 작은 데이터셋에도 좋은 성능
단점
- 모델이 단순해서 빅데이터에는 부적합
- 통계 모델은 분포보다는 분포의 평균값 추정에 집중함. 예측의 불확실성에 대한 대용물로서 표본의 분산을 도출할 수 있지만 이는 모델을 고를 때 선택한 모든 것에 대한 불확실성을 제한된 방식으로만 표현함.
- 통계모델은 비선형 관계가 많은 데이터 설명에 부적합
Q. GLM은 데이터를 시간순으로 입력해야 할까?
A. 일반화 선형 모델(GLM)은 데이터를 시간순으로 고려할 것을 요구하지 않는다.
이유
GLM?
GLM의 설계와 가정은 본질적으로 데이터의 연대순 순서를 설명하지 않고 대신 독립성을 가정하고 시간적 종속성을 직접 모델링하지 않는 방식으로 변수 간의 관계에 중점을 둔다.
-
통계적 독립성: GLM은 많은 기존 통계 모델과 마찬가지로 관측값이 서로 독립적이라고 가정한다. 이는 한 관찰의 결과가 다른 관찰의 결과에 의존하지 않는다는 의미다. 시계열 데이터에서는 관측치가 시간에 따라 상관될 수 있기 때문에 이 가정이 위반되는 경우가 많다(예: 오늘 매출이 어제 매출에 영향을 받을 수 있음).
-
모델 구조: GLM은 데이터 포인트의 순서나 순서를 명시적으로 통합하지 않고 종속변수와 하나 이상의 독립변수 간의 관계를 모델링하도록 설계되었습니다. 모델은 데이터 포인트가 표시되는 순서에 관계없이 종속변수의 관측값과 예측값 간의 차이를 최소화하는 독립변수에 대한 계수를 추정하는 데 중점을 둡니다.
-
시간적 구성 요소 부족: 시계열 모델(예: ARIMA, 지수 평활화, 딥 러닝의 LSTM 네트워크)과 달리 GLM에는 추세, 계절성 또는 자기 상관을 직접 모델링하는 구성 요소가 포함되어 있지 않다.
시간적 순서와 자기 상관이 중요한 요소인 시계열 예측의 경우 일반적으로 다른 모델이 더 적합하다. 그러나 과거 데이터를 독립변수를 활용하는 것을 통해 GLM모델에서도 시계열의 특징을 반영할 수 있다.
Q. 딥러닝 모델을 사용할 때에도 정상성을 만족해야 할까?
A. 딥러닝모델을 사용할 때에는 정상성을 요구하지 않는다. 그러나 딥러닝의 경우 입력의 모든 입력 채널의 값이 -1과 1사이로 조정될 때 가장 잘 동작하여 관련한 전처리작업은 필요하다.
Reference
- 빅데이터분석기사(데이터에듀)
- 실전시계열분석(한빛미디어, 에일린 닐슨)
- (사진출처) arima모델개요. 김성범교수
참고)
- pandas의 resample 메서드로 업샘플링과 다운샘플링 기능 구현
- shift() : 이전일자의 데이터 값 가져옴
- tslm() : 시계열 데이터에 대한 쉬운 선형회귀 방법론 제공
