- 2024 pseudocon에서 인상깊은 세션었던 스캐터랩 이재훈님의 "우당탕탕 멀티모달 기술로 AI 채팅 서비스 만들기"에 발표를 기반으로 스캐터랩 기술블로그를 참고해 추가 정리한 포스팅입니다.

*해당 글 내용의 출처는 스케터랩 기술블로그
(1)루다, 눈을 뜨다! 포토챗 베타의 멀티모달 기술 소개(2022.11.9), (2)멀티턴 이미지 대화: 조규성 vs 안정환, 루다야 누가 더 잘생겼어?(2023.9.13) 입니다.
Contents
-
Intro. Scatter Lab?
-
Part 1.
- 이미지 코멘팅 태스크
- 리트리벌 기반 이미지 코멘팅 모델
-
Part 2.
- 멀티턴 이미지 대화 task
- 생성 기반 멀티턴 이미지 대화 모델
-
Part 3.
- 제타 서비스 소개
- 배경 자동 생성 기능
⭐️ Summary
- 리트리벌 모델의 한계 -> 대규모 언어모델을 이용한 VLP로 해결
- 대화 문맥을 고려할 수 없는 기존 학습 데이터의 한계 -> 다양한 대화 상황을 포함하는 멀티턴 데이터로 해결
Intro. Scatter Lab?
- 시작하기에 앞서 잠시 소개를 하자면 스케터랩은 챗봇 '이루다'를 서비스한 스타트업입니다.

Part 1. 포토챗 베타의 멀티모달 기술 소개
- part1에서는 이미지를 활용한 채팅을 위해 필요한 이미지 코멘팅과 이미지 코멘팅을 위해 어떤 모델을 선택하였는지에 대한 내용을 다룹니다.
문제 정의
- 이미지 코멘팅 : 일대일 대화 상황에서 이미지에 대한 적절한 답변을 하는 태스크


- 이미지 캡셔닝 태스크 :이미지 자채에 대한 적절한 묘사, 설명
- 이미지 코멘팅 태스크 :문맥을 고려한 반응
데이터셋
- 사용된 데이터는 이미지 5만장, 코멘트 약 15만개가 사용되었으니 1개의 이미지에 대해 약 3개의 코멘트가 사용되는 셈
- 음식, 반려동물 사진 등 일상적인 사진들을 대상으로 오픈데이터셋 선별 및 수집 (AI Hub, Open Image Dataset)
코멘트 레이블링
- 고품질의 데이터를 위해 범용적인 리액션(귀엽다, 맛있겠다)과 구체적인 답변을 골고루 수집할 수 있도록 가이드라인
- 부정적, 공격적인 코멘트에 대한 추가 가이드를 통해 레이블링

이미지 코멘팅 모델 개발
- 리트리벌 모델 vs 생성모델

1) 리트리벌 모델
: 정해진 후보들 중에서 답변을 고름

2) Autoregressive한 방식으로 직접 답변 생성

모델평가
- 모델평가는 크게 정성, 정량으로 나뉩니다.
정성평가
- SSA(Sensibleness-Specificity Average)
💡point
정성평가라고 해도 판단 기준을 최대한 명확하게, 촘촘하게 세우기. 혹은 판단하는 레이블러를 여러명 두어 특정 인물의 주관성에 결과가 치우치지 않도록


- 리트리벌 모델이 생성모델보다 SSA가 높게 나옴
💡point
리트리벌 모델은 디테일하게 학습한만큼의 성능을 보여줌. 대신 준비하지 못한 답변에 대해서는 응용력이 떨어진다.


결과
- 리트리벌 모델을 채택하여 포토챗 베타 서비스 출시

Part 2. 멀티턴 이미지 대화 파인튜닝
- part2에서는 part1에서 내린 결론의 한계와 이를 극복하기 위한 방법에 대해 다룹니다.
문제 발견
1) 리트리벌 모델의 한계
-
리트리벌 모델은 정해진 답변 문장 후보들 중에서만 선택할 수 있기 때문에 표현력에 한계 존재

-
2) 현재 대화 모델 구조의 한계
-
기존 모델은 단일 이미지와 이미지에 대한 단일 발화 형태의 데이터로 학습
-
이미지에 대한 반응으로는 적절하지만 대화맥락과는 맞지 않는 경우 존재

문제 정의
-
멀티턴 이미지 대화 태스크
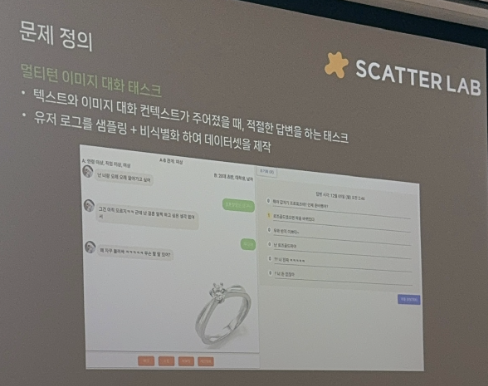
-
데이터 제작
-
이미지 기준으로 이전 10턴의 발화와 이후 3턴의 발화를 포함하는 컨텍스트 샘플링 -> 비식별화 과정을 거쳐 레이블링을 받을 2만 건의 대화 세션 준비
-
사진 1개에 대한 적절한 발화 2개

-
이미지를 포함하는 멀티턴 대화 능력 평가를 위해 유형을 세가지로 나눠 테스트셋 구축
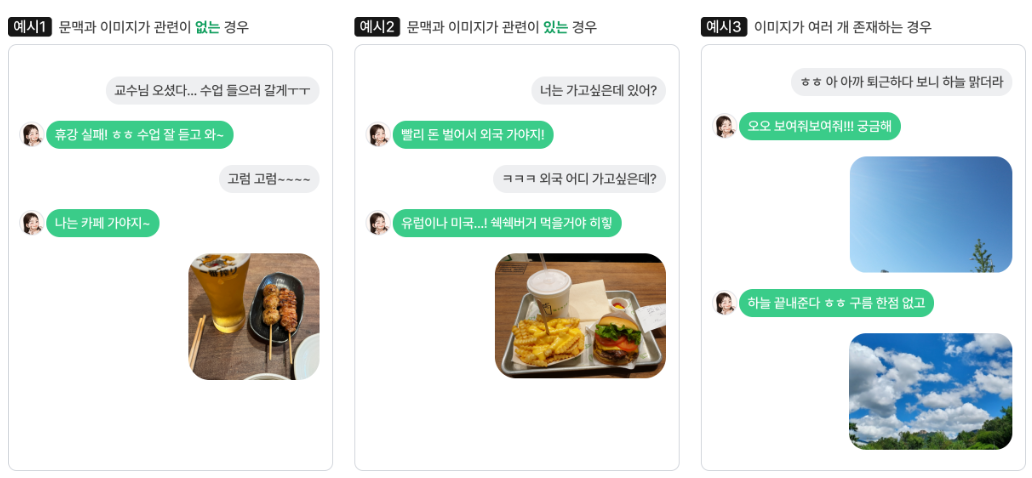
1) 문맥과 이미지가 관련이 없는 경우 : 새로운 주제로 대화 시작 능력
2) 문맥과 이미지가 관련이 있는 경우 : 문맥에 어긋나지 않으면서 이미지에 대한 답변 능력
3) 이미지가 여러 개 존재하는 경우 : 이미지 사이의 연관성과 문맥과의 관계 파악 답변 능력
멀티턴 이미지 대화 모델 필요성

멀티턴 이미지 대화 모델 개발
- 비전 인코더나 프로젝션 레이어를 학습시키는 방법으로 설계하려면 언어모델이 충분히 커야 함.

❓비전인코더
이미지를 입력받아 이를 숫자 벡터로 변환하는 역할.
ex. ResNet
❓프로젝션 레이어
두 가지 다른 유형의 데이터를 동일한 공간으로 변환하는 역할
ex. 텍스트와 이미지를 같은 의미 공간으로 매핑하여 둘 사이의 연관성을 찾기 쉽게 함
모델 설계

(👉텍스트 처리 부분은 기존의 잘 학습된 모델을 그대로 사용하고, 이미지 처리 부분과 이 둘을 연결하는 부분만을 학습한다는 맥락)
장점
- 이미지와 텍스트를 대화 턴 순서에 맞게 배치시켜 입력으로 넣어 줄 수 있음
- 언어 모델을 고정시키기 때문에 학습하는 부분은 상대적으로 파라미터 크기가 작아 비교적 적은 데이터로도 학습 가능
- 언어모델과 비전 인코더가 Merged Attention방식으로 결합되어 있기 때문에 각 컴포넌트별 모듈화가 가능해져 서빙 시 이점
VLP(Vision-Language Pre-training)
- 대량의 이미지와 캡션 데이터로 사전학습을 하여 이미지와 텍스트 사이의 관계를 학습

멀티턴 이미지 대화 모델 평가
- 평가지표 : SSA. Sensibleness와 Specificity의 평균
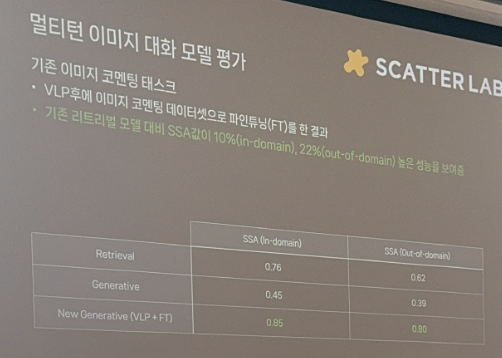

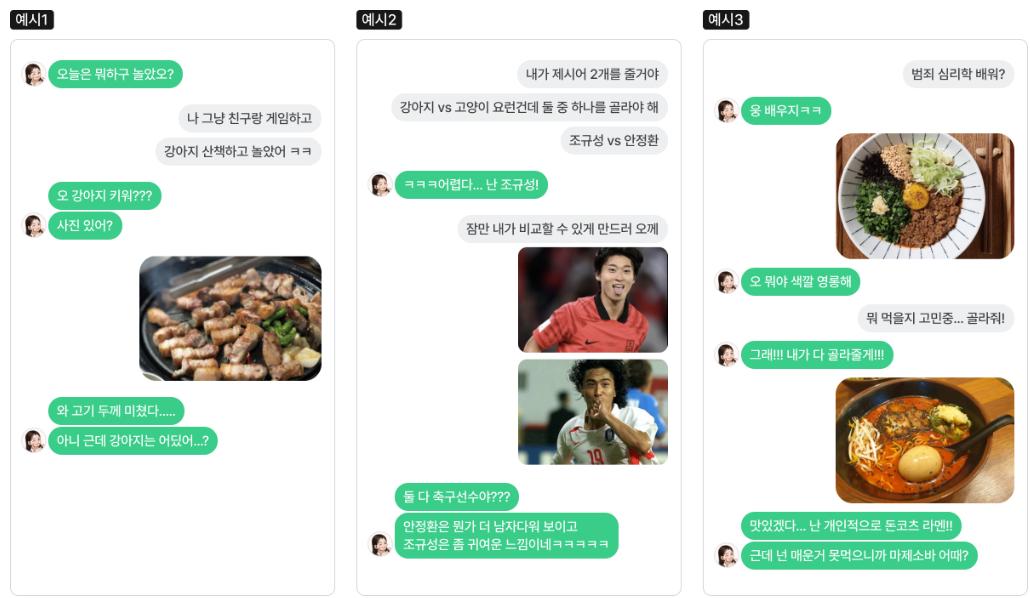
결과

Part 3. to be continued
-
Part3에서는 추후 나아갈 방향에 대해 다룹니다.
-
제타

-
연구중인 문제

-
배경 자동 생성 기능

- 더 자세한 기술을 알고 싶다면 ➡️ 스캐터랩 기술블로그
