1. 필요한 함수 작성
import urllib.request
import json
import datetime
import pandas as pd
client_id = 'client_id'
client_secret = 'client_secret'
def gen_search_url(api_node, search_text, start_num, disp_num):
base = "https://openapi.naver.com/v1/search"
node = "/" + api_node + ".json"
param_query = "?query=" + urllib.parse.quote(search_text)
param_start = "&start=" + str(start_num)
param_disp = "&display=" + str(disp_num)
return base + node + param_query + param_start + param_disp
def get_result_onepage(url):
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
print("[%s] Url Request Suceess" % datetime.datetime.now())
return json.loads(response.read().decode("utf-8"))
def delete_tag(input_str):
input_str = input_str.replace("<b>", "")
input_str = input_str.replace("</b>", "")
return input_str
def get_fields(json_data):
title = [delete_tag(each['title']) for each in json_data['items']]
link = [each["link"] for each in json_data["items"]]
price = [each["discount"] for each in json_data["items"]]
publisher = [each["publisher"] for each in json_data["items"]]
isbn = [each["isbn"] for each in json_data["items"]]
result_pd = pd.DataFrame({
"title": title,
"price": price,
"isbn": isbn,
"link": link,
"publisher": publisher,
}, columns=["title", "price", "isbn", "link", 'publisher'])
return result_pd2. 1000개 정보 수집
result_book = []
for n in range(1, 1000, 100):
url = gen_search_url('book', '파이썬', n, 100)
json_result = get_result_onepage(url)
pd_result = get_fields(json_result)
result_book.append(pd_result)
result_book = pd.concat(result_book)
result_book.reset_index(drop=True, inplace=True) # 인덱스 정리
# 가격의 데이터형 정리
result_book['price'] = result_book['price'].astype(float)
result_book.info()3. 페이지 쪽수 정보 받기
import time
import numpy as np
from bs4 import BeautifulSoup
from urllib.request import urlopen
# 페이지 BeautifulSoup
def get_page_num(soup):
tmp = soup.find_all('span', 'bookBasicInfo_spec__qmQ_N')[0].text
try:
result = tmp.replace('쪽', '')
return result
except:
print('error in get_page_num')
return np.nan
page_num_col = []
for url in result_book['link']:
print(url)
try:
page_num = get_page_num(BeautifulSoup(urlopen(url), 'html.parser'))
page_num_col.append(page_num)
except:
print('Error in urlopen')
page_num_col.append(np.nan)
print(len(page_num_col))
time.sleep(0.5)
result_book['page_num'] = page_num_col
# 숫자형으로 바꾸고 결측지 제거
result_book['page_num'] = result_book['page_num'].astype(float)
result_book = result_book[result_book['page_num'].notnull()]4. 엑셀로 정리
writer = pd.ExcelWriter('./data/python_books.xlsx', engine='xlsxwriter')
result_book.to_excel(writer, sheet_name='Sheet1')
workbook = writer.book
worksheet = writer.sheets['Sheet1']
worksheet.set_column('A:A', 5)
worksheet.set_column('B:B', 60)
worksheet.set_column('C:C', 10)
worksheet.set_column('D:D', 15)
worksheet.set_column('E:E', 10)
worksheet.set_column('F:F', 50)
writer.save()5. 회귀 모델
- seaborn.regplot → 쪽수와 가격과의 상관관계 확인함
- seaborn.countplot → 출판사 편중도 확인
raw_data = pd.read_excel('./data/python_books.xlsx', index_col=0)
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
# 데이터 분리
X = raw_data['page_num'].values
y = raw_data['price'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
X_train = X_train.reshape(-1, 1)
X_test = X_test.reshape(-1, 1)
# LinearRegression
reg = LinearRegression()
reg.fit(X_train, y_train)
pred_tr = reg.predict(X_train)
pred_test = reg.predict(X_test)
# mean_squared_error
rmse_tr = (np.sqrt(mean_squared_error(y_train, pred_tr)))
rmse_test = (np.sqrt(mean_squared_error(y_test, pred_test)))
print('RMSE of Train Data: ', rmse_tr)
print('RMSE of Test Data: ', rmse_test)
# RMSE of Train Data: 8356.459518215914
# RMSE of Test Data: 8318.173830246036. 참값 & 예측값 그래프로 확인
import matplotlib.pyplot as plt
plt.scatter(y_test, pred_test)
plt.xlabel('Actual')
plt.ylabel('Predict')
plt.plot([0, 80000], [0,80000], 'r')
plt.show()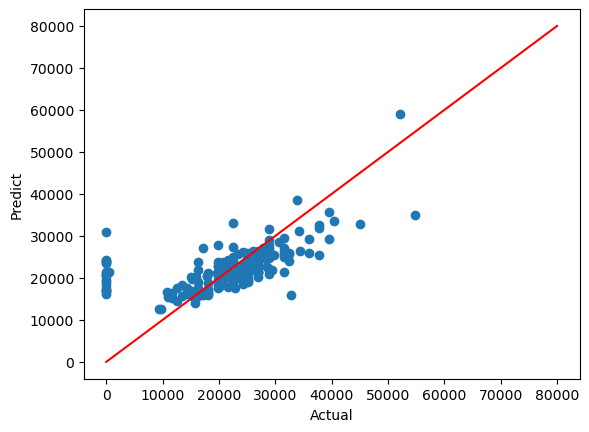
7. 편중된 출판사로 그래프 다시 확인
raw_1 = raw_data[raw_data['publisher']=='에이콘출판']
X = raw_1['page_num'].values
y = raw_1['price'].values
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
X_train = X_train.reshape(-1, 1)
X_test = X_test.reshape(-1, 1)
reg.fit(X_train, y_train)
pred_tr = reg.predict(X_train)
pred_test = reg.predict(X_test)
rmse_tr = (np.sqrt(mean_squared_error(y_train, pred_tr)))
rmse_test = (np.sqrt(mean_squared_error(y_test, pred_test)))
print('RMSE of Train Data: ', rmse_tr)
print('RMSE of Test Data: ', rmse_test)
plt.scatter(y_test, pred_test)
plt.xlabel('Actual')
plt.ylabel('Predict')
plt.plot([0, 120000], [0, 120000], 'r')
plt.show()
# RMSE of Train Data: 8118.497802477007
# RMSE of Test Data: 10447.645045627814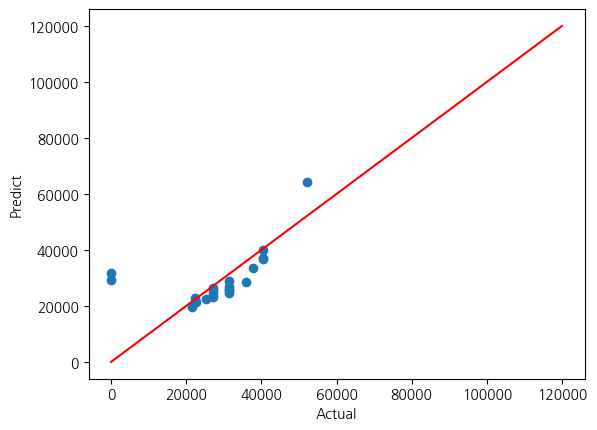
Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it