비지도학습
- Clustering(군집) : 비슷한 샘플을 모음
- Outier detection(이상치 탐지) : 정상 데이터가 어떻게 보이는지 학습, 비정상 샘플을 감지
- 밀도 추정 : 데이터셋의 확률 밀도 함수 Probability Density Function PDF를 추정. 이상치 탐지 등에 사용
K-Means
- 군집화에서 가장 일반적인 알고리즘
- 군집 중심(centroid)이라는 임의의 지점을 선택해서 해당 중심에 가장 가까운 포인트들을 선택하는 군집화
- 일반적인 군집화에서 가장 많이 사용되는 기법
- 거리 기반 알고리즘으로 속성의 개수가 매우 많을 경우 군집화의 정확도가 떨어짐
K-Means 알고리즘
- 입력: 훈련집합 X = {x1,...xn}, 군집의 개수 k
- 출력: 군집집합 C = {c1,...,ck}
k개의 군집 중심 Z = {z1,..,zk}를 초기화한다.
while(true)
for (i=1 to n)
xi를 가장 가까운 군집 중심에 배정
if (이루어진 배정이 이전 루프에서의 배정과 같으면)
for (j=1 to k)
zj에 배정된 샘플의 평균으로 zj를 대치
for (j=1 to k)
zj에 배정된 샘플을 cj에 대입원리
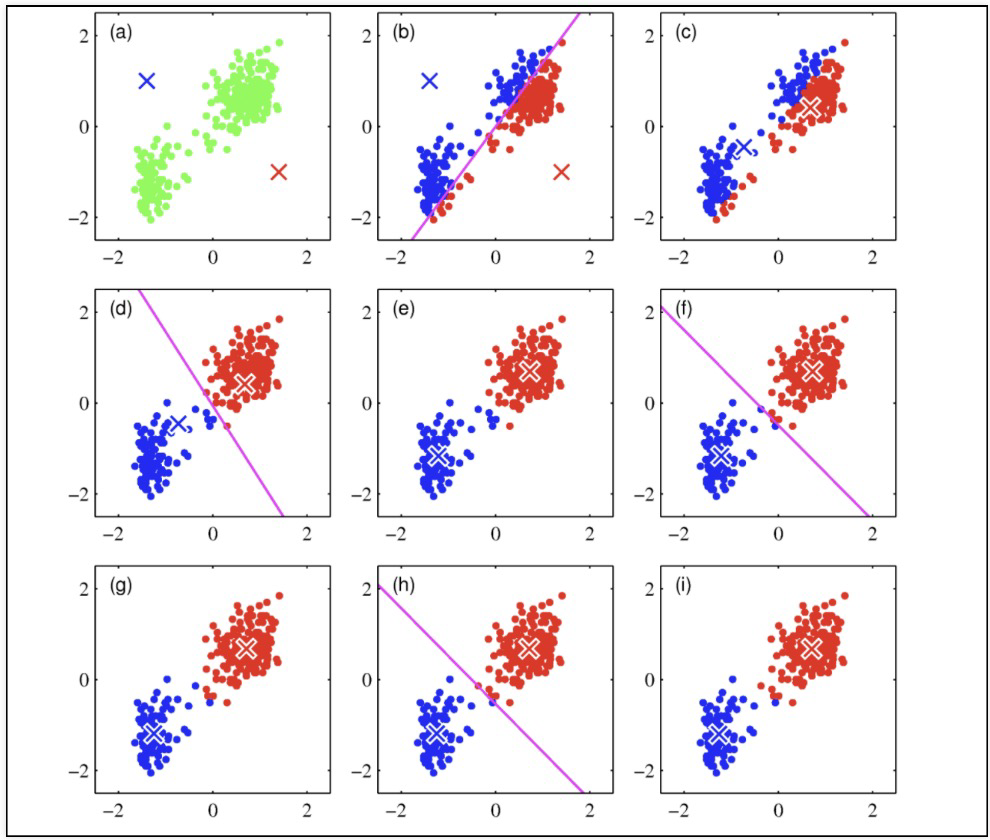
- 초기 중심점을 설정
- 각 데이터는 가장 가까운 중심점에 소속
- 중심점에 할당된 평균값으로 중심점 이동
- 각 데이터는 이동된 중심점 기준으로 가장 가까운 중심점에 소속
- 다시 중심점에 할당된 데이터들의 평균값으로 중심점 이동
- 데이터들의 중심점 소속 변경이 없으면 종료
KMeans vs K-Means++
- K개의 임의의 중심점(centroid)을 배치
- 각 데이터들을 가장 가까운 중심점으로 할당
- 군집으로 지정된 데이터들을 기반으로 해당 군집의 중심점을 업데이트
- 수렴이 될 때까지 반복
vs
- 데이터 무작위 1개 선택 후 첫 번째 중심으로 설정
- 나머지 데이터 포인트들에 대해 그 첫번째 중심점까지의 거리를 계산
- 두번째 중심점은 각 점들로부터 거리비례 확률에 따라 선택(최대한 먼 곳에 배치된 데이터를 다음 중심점으로 지정)
- 중심점이 k개가 될 때까지 반복
Reference
1) 제로베이스 데이터스쿨 강의자료
2) https://hleecaster.com/k-means-clustering-concept/

데이터 사이언스 / just do it