군집 평가
- 분류기는 평가 기준(정답)을 가지고 있지만, 군집은 그렇지 않다.
- 군집 결과를 평가하기 위해 실루엣 분석을 많이 활용한다.
실루엣 분석
- 실루엣 분석은 각 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지 나타냄
- 다른 군집과는 거리가 떨어져 있고, 동일 군집간의 데이터는 서로 가깝게 잘 뭉쳐 있는지 확인
- 군집화가 잘 되어 있을 수록 개별 군집은 비슷한 정도의 여유공간을 가지고 있음
- 실루엣 계수 : 개별 데이터가 가지는 군집화 지표
1. 데이터 & 군집화
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.cluster import KMeans
iris = load_iris()
feature_names = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width']
iris_df = pd.DataFrame(data=iris.data, columns=feature_names)
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=300, random_state=0).fit(iris_df)
iris_df['cluster'] = kmeans.labels_2. silhouette_samples, silhouette_score
sklearn.metrics.silhouette_samples(X, labels, metric=’euclidean’, **kwds): X feature 데이터 셋 & 각 피처 데이터 셋이 속한 군집 레이블 값인 labels 데이터 → 각 데이터 포인트의 실루엣 계수를 계산해 반환sklearn.metrics.silhouette_score(X, labels, metric=’euclidean’, smaple_szie = None, **kwds): X feature 데이터 셋 & 각 피처 데이터 셋이 속한 군집 레이블 값인 labels 데이터 → 전체 데이터의 실루엣 계수 값을 평균해 반환 = np.mead(silhouette_samples()) 높을수록 군집화가 어느정도 잘 됐다고 판단할 수는 있다.(절대적이지 않다.)
from sklearn.metrics import silhouette_samples, silhouette_score
avg_value = silhouette_score(iris.data, iris_df['cluster'])
score_value = silhouette_samples(iris.data, iris_df['cluster'])
print('avg_value', avg_value)
print('silhouette_samples() return 값의 shape', score_value.shape)
# avg_value 0.5528190123564091
# silhouette_samples() return 값의 shape (150,)3. yellowbrick
pip install yellowbrick
from yellowbrick.cluster import silhouette_visualizer
silhouette_visualizer(kmeans, iris.data, colors='yellowbrick')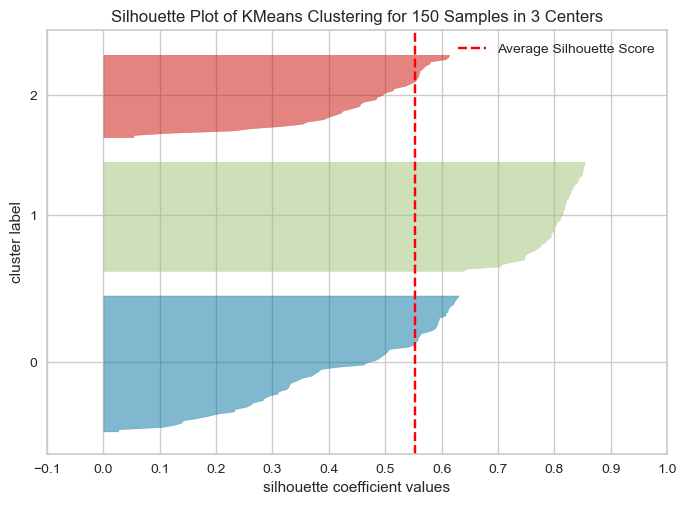
Reference
1) 제로베이스 데이터스쿨 강의자료
2) https://ariz1623.tistory.com/224

데이터 사이언스 / just do it