1. 군집화 연습을 위한 데이터 생성기
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=200, n_features=2, centers=3, cluster_std=0.8, random_state=0)
print(X.shape, y.shape) # (200, 2) (200,)
unique, counts = np.unique(y, return_counts=True)
print(unique, counts) # [0 1 2] [67 67 66]2. 데이터 정리
cluster_df = pd.DataFrame(data=X, columns=['ftr1', 'ftr2'])
cluster_df['target'] = y3. 군집화 & 데이터 정리
kmeans = KMeans(n_clusters=3, init='k-means++', max_iter=200, random_state=13)
cluster_labels = kmeans.fit_predict(X)
cluster_df['kmeans_label'] = cluster_labels4. 결과 도식화
centers = kmeans.cluster_centers_
unique_labels = np.unique(cluster_labels)
markers = ['o', 's', '^', 'P', 'D', 'H', 'x']
for label in unique_labels:
label_cluster = cluster_df[cluster_df['kmeans_label']==label]
center_x_y = centers[label]
plt.scatter(x=label_cluster['ftr1'], y=label_cluster['ftr2'], edgecolors='k', marker=markers[label])
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=200, marker=markers[label], color='white', edgecolors='k', alpha=0.8)
plt.scatter(x=center_x_y[0], y=center_x_y[1], s=70, marker='$%d$' %label, color='k', edgecolors='k')
plt.show()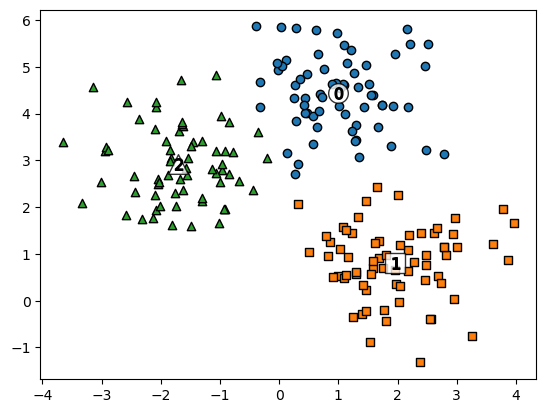
5. 결과 확인
print(cluster_df.groupby('target')['kmeans_label'].value_counts())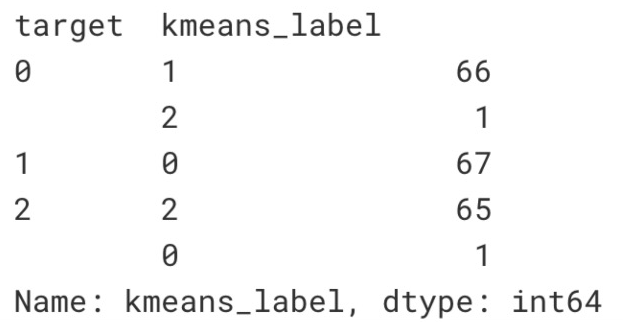
Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it