1. 레드 와인 / 화이트 와인 분류기
데이터 분리
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# 라벨 분리
X = wine.drop(['color'], axis=1)
y = wine['color']
# 데이터 분리: 훈련용, 테스트용
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
# 결정나무 훈련
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
# 학습결과, 정확도
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print(accuracy_score(y_train, y_pred_tr)) # 0.9553588608812776
print(accuracy_score(y_test, y_pred_test)) # 0.9569230769230769MinMaxScaler & StandardScaler
- 컬럼들의 최대/최소 범위가 각각 다르고, 평균과 분산이 각각 다르다.
- 특성(feature)의 편향 문제는 최적의 모델을 찾는데 방해가 될 수도 있다.
- 결정나무에서는 이런 전처리는 의미를 가지지 않는다.
- 주로 Cost Function을 최적화할 때 유효할 때가 있다.
- MinMaxScaler와 StandardScaler 중 어떤 것이 좋을지는 해봐야 안다.
from sklearn.preprocessing import MinMaxScaler, StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
# MinMaxScaler & StandardScaler
MMS = MinMaxScaler()
SS = StandardScaler()
MMS.fit(X)
SS.fit(X)
X_mms = MMS.transform(X)
X_ss = SS.transform(X)
X_mms_pd = pd.DataFrame(X_mms, columns=X.columns)
X_ss_pd = pd.DataFrame(X_ss, columns=X.columns)
# MinMaxScaler를 이용한 결정나무 훈련
X_train, X_test, y_train, y_test = train_test_split(X_mms_pd, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print(accuracy_score(y_train, y_pred_tr)) # 0.9553588608812776
print(accuracy_score(y_test, y_pred_test)) # 0.9569230769230769
# StandardScaler을 이용한 결정나무 훈련
X_train, X_test, y_train, y_test = train_test_split(X_ss_pd, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print(accuracy_score(y_train, y_pred_tr)) # 0.9553588608812776
print(accuracy_score(y_test, y_pred_test)) # 0.9569230769230769
# 결정나무모델
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(wine_tree, feature_names=X.columns)
# 레드와인과 화이트와인을 구분하는 중요 특성 확인
dict(zip(X_train.columns, wine_tree.feature_importances_))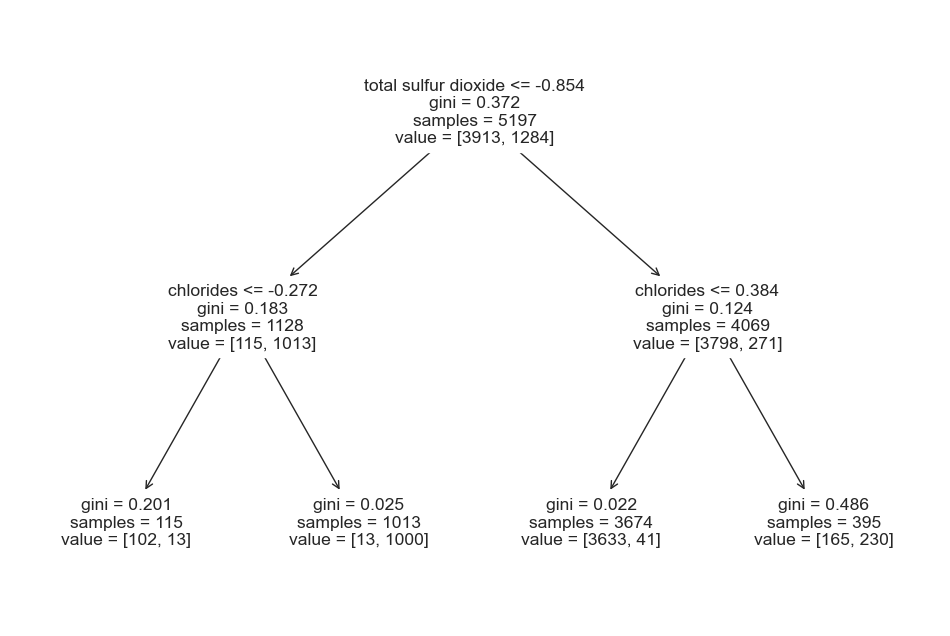
2. 와인 맛에 대한 분류-이진 분류(0 or 1, False or True)
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
from sklearn.tree import plot_tree
# quality 컬럼 이진화
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
# taste가 quality로부터 만들어져서 두 컬럼 모두 제거
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
# 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13)
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
wine_tree.fit(X_train, y_train)
# 예측 정확도
y_pred_tr = wine_tree.predict(X_train)
y_pred_test = wine_tree.predict(X_test)
print(accuracy_score(y_train, y_pred_tr))
print(accuracy_score(y_test, y_pred_test))
# 결정나무모델
plt.figure(figsize=(12,8))
plot_tree(wine_tree, feature_names=X.columns)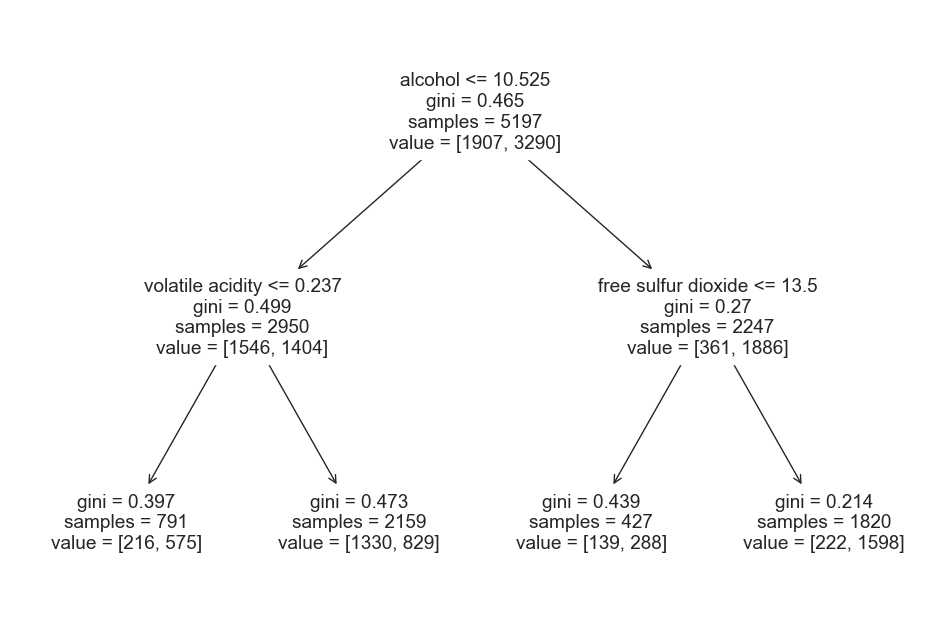
3. Pipeline
- 데이터의 전처리와 여러 알고리즘의 반복 실행, 하이퍼 파라미터의 튜닝 과정 중 발생하는 혼돈을 방지해주는 기능
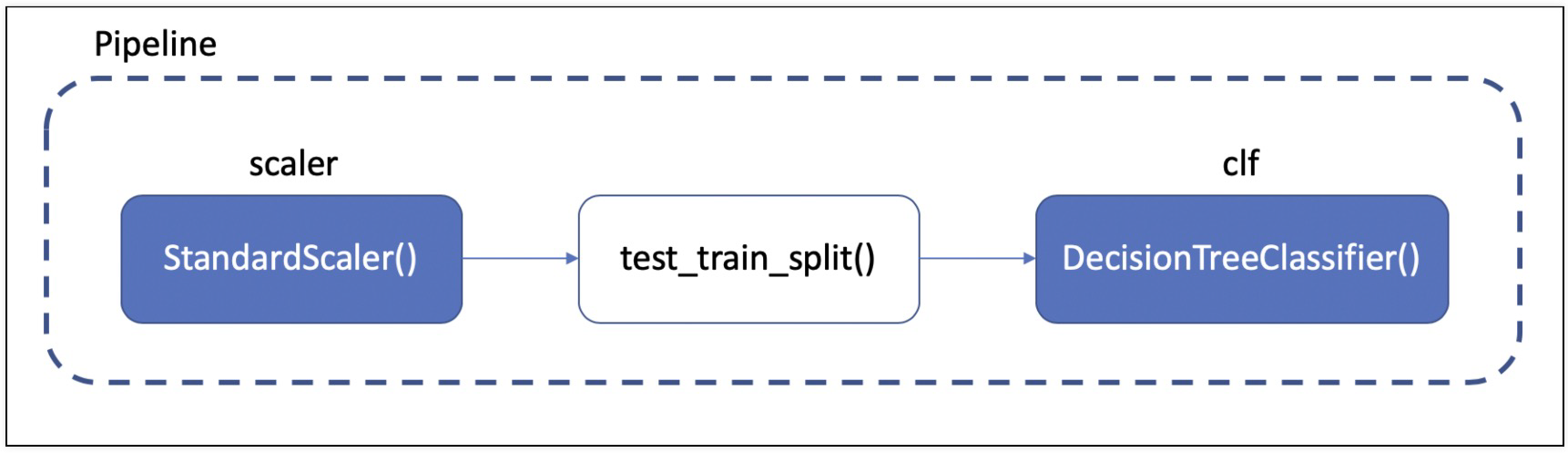
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# pipeline으로 scaler, clf설정
estimators = [('scaler', StandardScaler()), ('clf', DecisionTreeClassifier())]
pipe = Pipeline(estimators)
pipe.set_params(clf__max_depth=2)
pipe.set_params(clf__random_state=13)
# 데이터 분리는 pipeline에 속하지 않는다
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=13, stratify=y)
pipe.fit(X_train, y_train)
y_pred_tr = pipe.predict(X_train)
y_pred_test = pipe.predict(X_test)
print(accuracy_score(y_train, y_pred_tr)) # 0.9657494708485664
print(accuracy_score(y_test, y_pred_test)) # 0.9576923076923077
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(pipe['clf'], feature_names=X.columns)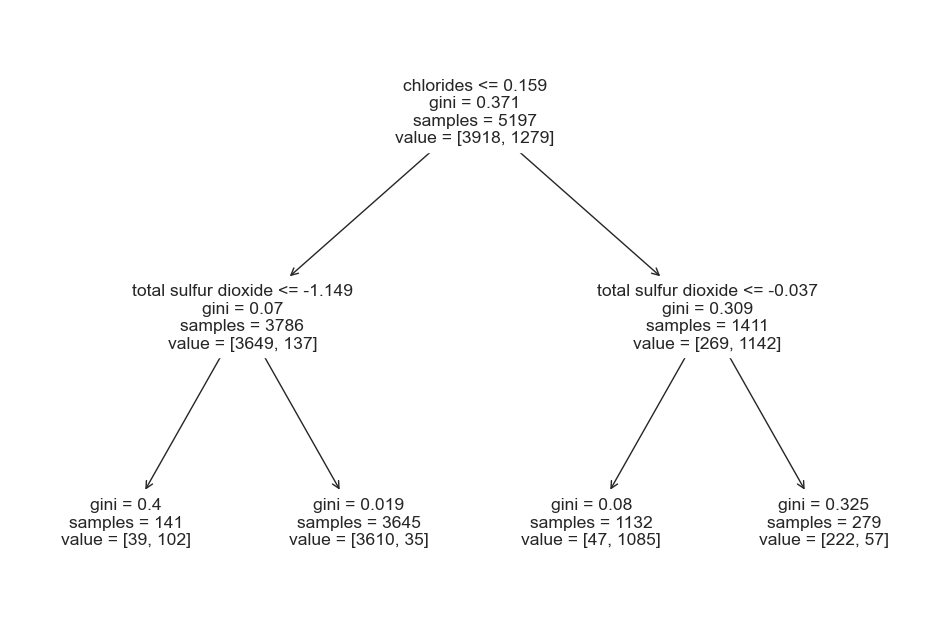
Reference
1) 데이터스쿨 강의자료

데이터 사이언스 / just do it