1. 교차검증
- 과적합 감지
- 나에게 주어진 데이터에 적용한 모델의 성능을 정확히 표현하기 위해서도 유용
- 검증 validation이 끝난 후 test용 데이터로 최종 평가

k-fold cross validation
- KFold는 index를 반환한다
- 예시: 와인 맛 분류 모델 정확도 신뢰할만 한가?
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
wine['taste'] = [1. if grade>5 else 0. for grade in wine['quality']]
X = wine.drop(['taste', 'quality'], axis=1)
y = wine['taste']
# KFold
from sklearn.model_selection import KFold
kfold = KFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_acuuracy = []
# 각각의 fold에 대한 학습 후 acc
for train_idx, test_idx in kfold.split(X):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_acuuracy.append(accuracy_score(y_test, pred))
# 각 acc의 분산이 크지 않다면 평균을 대표 값으로 한다
np.mean(cv_acuuracy) # 0.709578255462782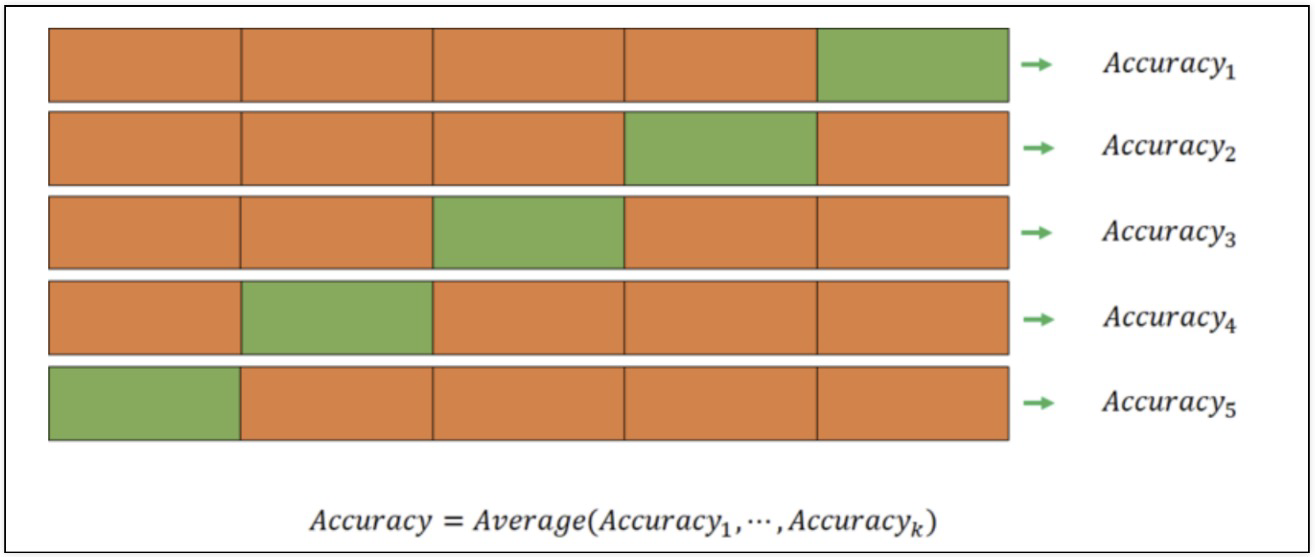
stratified k-fold cross validation
- 정확도가 더 나쁜 경우가 존재
from sklearn.model_selection import StratifiedKFold
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cv_acuuracy = []
for train_idx, test_idx in skfold.split(X, y):
X_train, X_test = X.iloc[train_idx], X.iloc[test_idx]
y_train, y_test = y.iloc[train_idx], y.iloc[test_idx]
wine_tree_cv.fit(X_train, y_train)
pred = wine_tree_cv.predict(X_test)
cv_acuuracy.append(accuracy_score(y_test, pred))
np.mean(cv_acuuracy) # 0.6888004974240539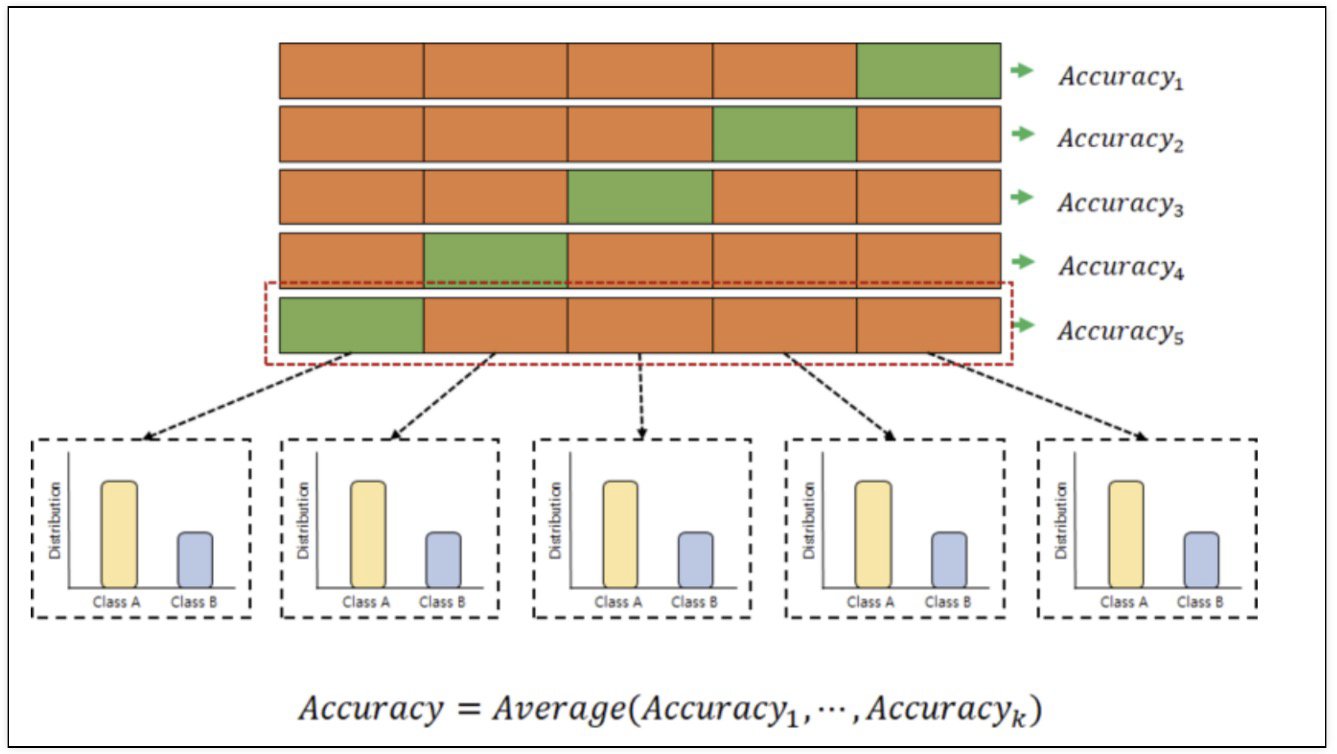
cross validation
- cross_val_score: 위의 과정을 간편하게 표현
- cv: cross validation를 의미
- depth가 높다고 무조건 acc가 좋아지는 것도 아니다
- cross_validate: train score와 함께 출력
from sklearn.model_selection import cross_val_score
skfold = StratifiedKFold(n_splits=5)
wine_tree_cv = DecisionTreeClassifier(max_depth=2, random_state=13)
cross_val_score(wine_tree_cv, X, y, scoring=None, cv=skfold)
# array([0.55230769, 0.68846154, 0.71439569, 0.73210162, 0.75673595])
---------------------------------------------
from sklearn.model_selection import cross_validate
cross_validate(wine_tree_cv, X, y, scoring=None, cv=skfold, return_train_score=True)
'''
{'fit_time': array([0.00900006, 0.00780416, 0.00802684, 0.00782323, 0.00946403]),
'score_time': array([0.00290084, 0.0029459 , 0.00184917, 0.0019629 , 0.00274992]),
'test_score': array([0.55230769, 0.68846154, 0.71439569, 0.73210162, 0.75673595]),
'train_score': array([0.74773908, 0.74696941, 0.74317045, 0.73509042, 0.73258946])}
'''2. 하이퍼파라미터 튜닝
- 모델의 성능을 확보하기 위해 조절하는 설정 값
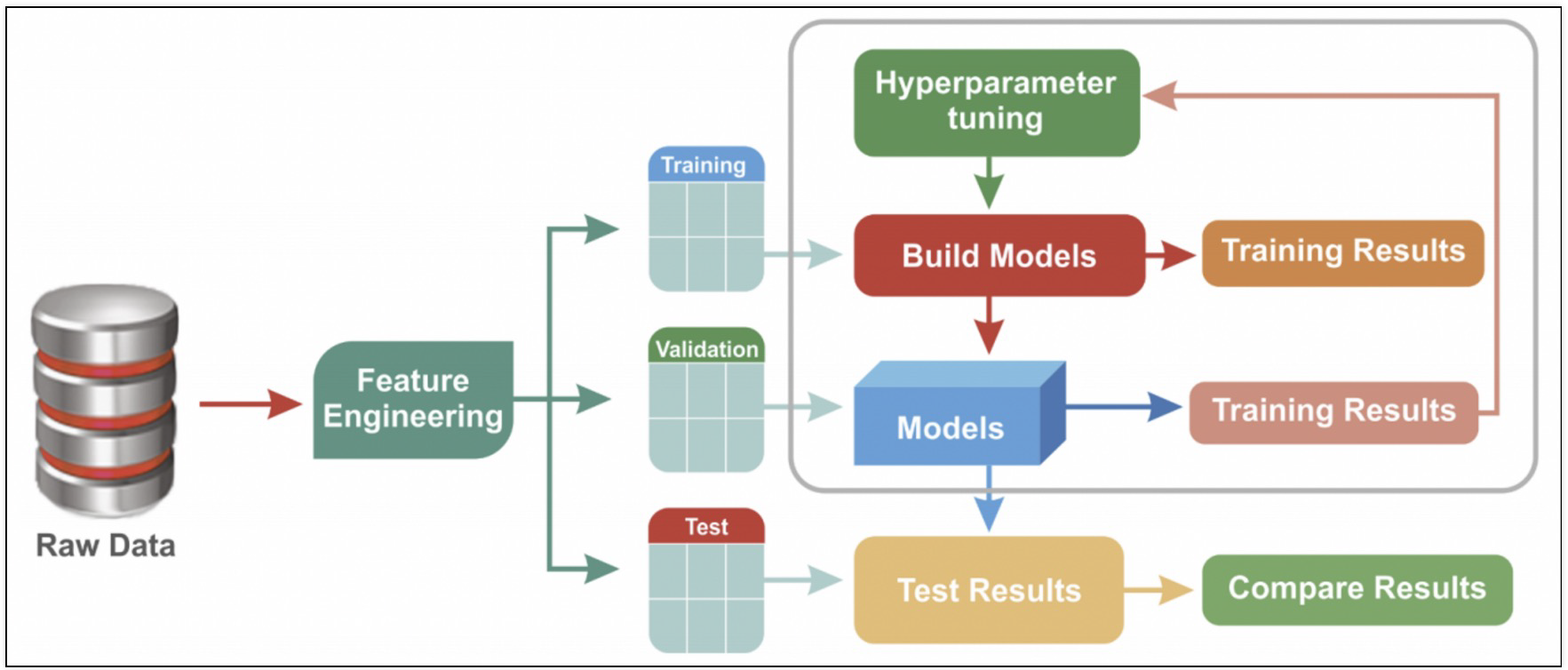
GridSearchCV
- n_jobs 옵션을 높여주면 CPU의 코어를 보다 병렬로 활용한다. Core가 많을수록 n_jobs를 높이면 속도가 빨라진다.
import pprint
from sklearn.model_selection import GridSearchCV
from sklearn.tree import DecisionTreeClassifier
# 확인하고 싶은 파라미터 정의(여기서는 max_depth)
params = {'max_depth': [2,4,7,10]}
wine_tree = DecisionTreeClassifier(max_depth=2, random_state=13)
gridsearch = GridSearchCV(estimator=wine_tree, param_grid=params, cv=5)
gridsearch.fit(X, y)
pp = pprint.PrettyPrinter(indent=4)
# GridSearchCV의 결과
pp.pprint(gridsearch.cv_results_)
# 최적의 성능을 가진 모델 파악하기
gridsearch.best_estimator_
gridsearch.best_score_
gridsearch.best_params_pipeline & GridSearch
from sklearn.pipeline import Pipeline
from sklearn.tree import DecisionTreeClassifier
from sklearn.preprocessing import StandardScaler
estimators = [('scaler', StandardScaler()), ('clf', DecisionTreeClassifier(random_state=13))]
pipe = Pipeline(estimators)
param_grid = [{'clf__max_depth': [2,4,7.10]}]
GridSearch = GridSearchCV(estimator=pipe, param_grid=param_grid, cv=5)
GridSearch.fit(X, y)
# 최고 모델
GridSearch.best_estimator_
GridSearch.best_score_
GridSearch.best_params_
# 결정나무모델
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(12,8))
plot_tree(GridSearch.best_estimator_['clf'], feature_names=X.columns)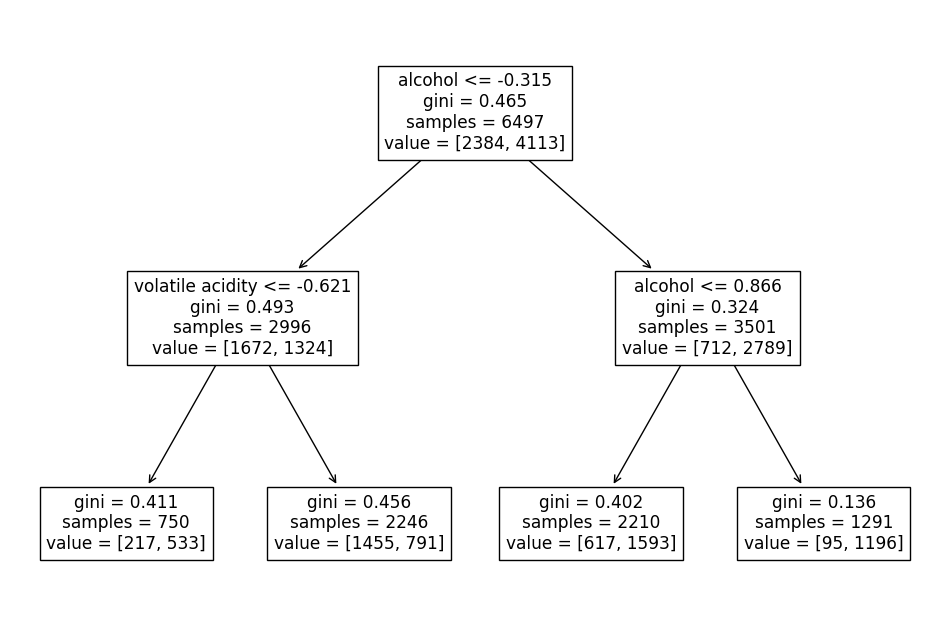
Reference
1) 제로베이스 데이터스쿨 강의자료

데이터 사이언스 / just do it