Adam이 무엇인지 찾다가 여기까지 왔음
참고 :
https://seamless.tistory.com/38
https://www.slideshare.net/yongho/ss-79607172
https://blog.naver.com/bya135/222299927749
Optimizer
n. a person or thing that optimizes(최대한 활용하다), 즉 최적화기...?
우리가 Network를 학습시키는 이유는 loss 를 줄이기 위해서였다.
loss 를 줄이기 위해서 Gradient Descent 라는 방법을 사용하였음.

기존의 Gradient Descent 방법은 우리가 가진 Data를 한바퀴 다 돌고난 다음에 Gradient Descent Step을 1번 밟는 방식이었다. 이 방식은 너무 오래걸림!

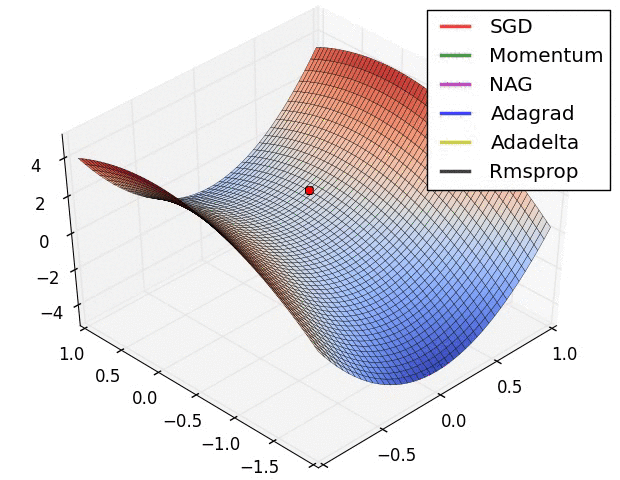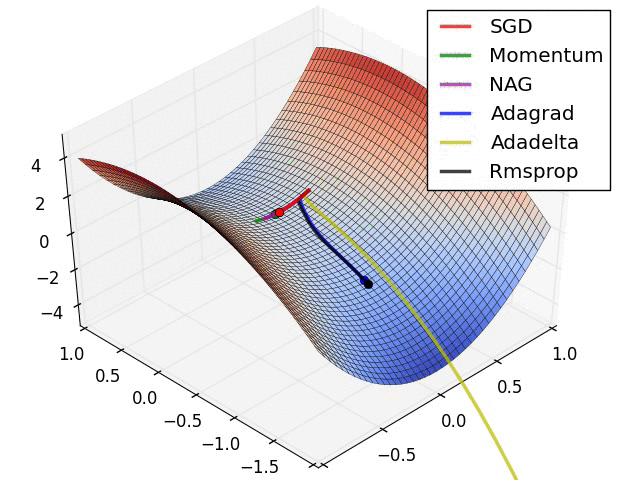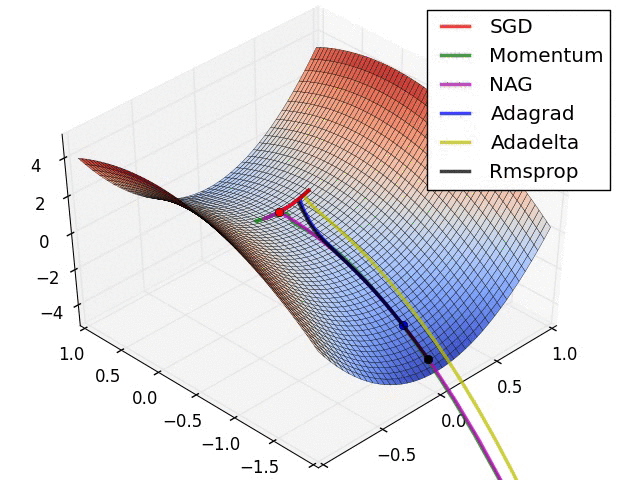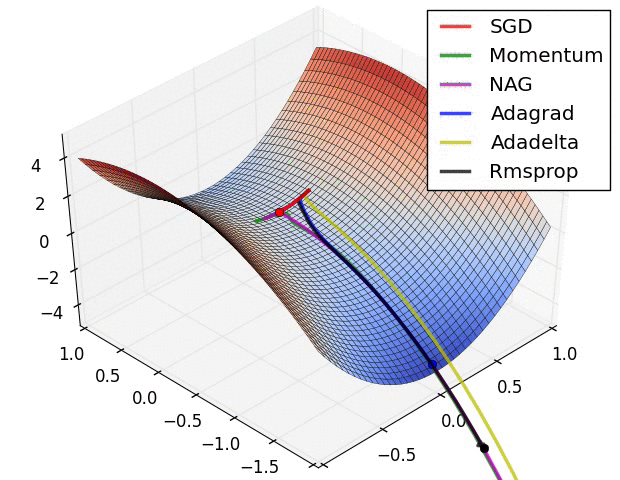
위 그림처럼 mini-batch를 통해서 한 걸음을 밟는 SGD(Stochastic Gradient Descent) 방식이 나옴. (이런게 바로 최적화기, 즉 Optimizer야!)
Gradient Descent vs Stochastic Gradient Descent
기존의 GD는 데이터 전부다 읽고나서 최적의 1스텝을 밟음
신중하지만 매우 느린편SGD는 데이터 토막토막만 읽고나서 1스텝을 밟음
술취한 사람처럼 방향이 다소 부정확하지만 꽤 빠른편
무엇이든지 장점이 있으면 단점이 있는 편...
SGD(Stochastic Gradient Descent) 또한 단점이 있음.
- 방향이 부정확한 편
- (첫번째 단점과 함께...) 보폭, 즉 Learning Rate가 너무 작으면 계속 헤멜것이고, 너무 크면 아예 다른 길로 가버릴 수 있음!
사람들은 더 많은 Optimizer들을 만들어냄
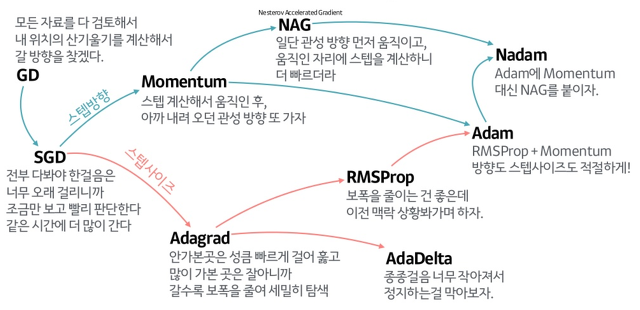
※ Keypoint
SGD(Stochastic Gradient Descent)에서 방향과 보폭(Learning Rate)에 대해서 위와 같이 나눠진다.
저기에 Adam(Adaptive Moment Assessment)만 기억하고 가자.
Adam Optimizer에 대해 간략히 설명하면 다음과 같다.
변수와 한걸음마다 다른 보폭을 이용, 모멘텀도 사용! 매우 좋음
[+] 모멘텀에 대하여...
Deep Learning - Neural Networks : Lesson 3. Training Neural Networks (4)
~ About the Momentum
Another way to solve the local minimum problem is with momentum.
Momentum is a constant between and .
We use to get a sort of weighted average of the previous steps:
Beta는 0~1사이의 숫자이므로 제곱제곱할수록 값이 줄어듬!
따라서 최신 스텝에 대한 영향이 제일 크고, 이전이전이전~ 스텝일수록 영향이 매우 작아짐
