What is list?
가장 먼저 살펴볼 data structure는 list입니다. abstract list(or list ADT )는 programmer가 ordering을 define한 linearly ordered data로 정의됩니다. 즉, data들이 linear한 order를 가져 일렬로 나열된 형태의 data structure를 말합니다. list ADT는 기본적으로 다음 operation들을 포함할 수 있으며, 필요에 따라 더 다양한 functionality를 부여할 수 있습니다.
- access to the object (find)
- erase an object (remove)
- insertion of a new object (insert)
- replacement of the object (replace)
list를 구현하기 위한 가장 obvious한 implementation으로는 array와 linked list가 있습니다.
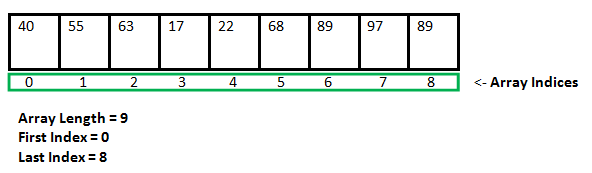
Array
- Definition
array는 contiguous한 memory space를 allocate해 address 순서대로 정렬된 index를 활용하는 data structure입니다. 모든 entry가 index를 이용해 그 위치가 정해져있기 때문에 data를 find하기에 매우 용이하고 data를 저장하기 위한 memory space가 정확히 data size와 동일하다는 장점을 가지고 있지만, array의 중간 지점에 data를 insert하거나 erase하기 위해서 그 뒤의 data들을 모두 copy해 다른 index로 옮겨주어야 한다는 단점이 있습니다.
// image - array //
- Run time of array operation
array에서 각 operation을 특정 위치에서 수행하기 위한 time complexity는 다음과 같습니다.
Front(1th) node | kth node | Last(nth) node | |
|---|---|---|---|
| Find | |||
| Insert before | * | ||
| Insert after | * | ||
| Replace | |||
| Erase | |||
| Next | N/A | ||
| Previous | N/A |
* only if the array is not full
표에서 볼 수 있는 특징은 array에서 find와 관련된 operation(Find, Replace, Next, Previous)은 모두 time으로 수행할 수 있다는 점입니다. insert와 erase는 해당 array index 뒤에 얼마나 많은 entry를 copy해야 하는지에 따라 변하므로, 평균적으로 time이 필요합니다. 여기에 더해, array에 할당된 memory가 가득 찼을 때, nth entry에서 insert를 수행하는 것은 새로운 memory를 할당받는 operation이 필요하고, 할당받은 memory space에 모든 entry를 copy하여 옮겨주어야 하기 때문에 만큼의 시간이 필요합니다.
- Two-ended array
표에서 나타난 것과 같이 array의 first entry에 가까울수록 insert와 erase에 불리한 특징을 가지고 있습니다. 이를 해소하기 위해 등장한 개념이 바로 two-ended array입니다. 기존의 array가 한 방향으로만 grow할 수 있는 것과 달리 two-ended array는 양 방향으로 모두 grow할 수 있도록 설계한 형태의 data structure입니다. 이로 인해 first entry에서 insert와 erase를 수행하더라도 time에 이를 수행할 수 있고, arbitrary position에 대해서도 평균적으로 더 빠르게 수행할 수 있게 됩니다. 하지만, 중간 지점에서 여전히 insert, erase operation에 time이 필요하며 first entry 방향의 grow를 implement하기 위해 last entry를 가리키는 pointer가 추가적으로 필요합니다.
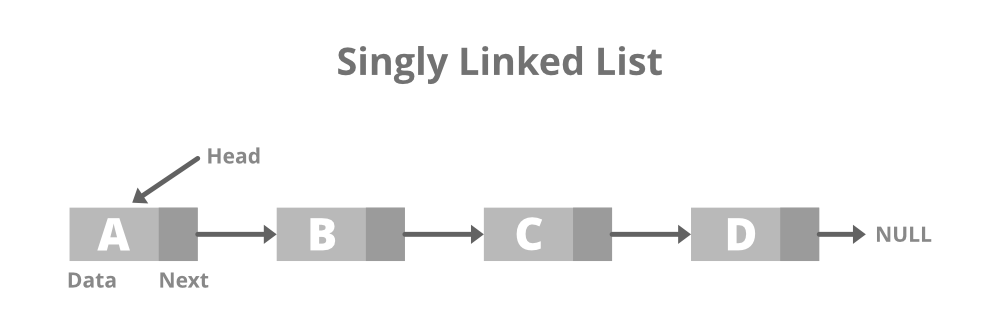
Linked list
- Definition
linked list는 각 data를 node에 저장하고 한 node가 다른 node를 가리키도록 pointer를 같이 저장해 series of node를 형성하는 data structure입니다. 가장 기본적인 형태의 linked list는 한 방향으로 다음 node를 point하도록 구현한 singly linked list입니다. singly linked list에서 front node를 가리키는 pointer를 head, last node를 가리키는 pointer를 tail이라고 하며, 마지막 node는 어떠한 node도 point하고 있지 않습니다(c++에서 nullptr 활용).
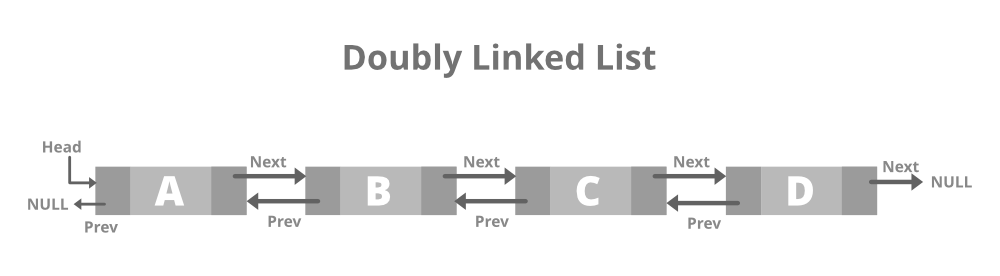
singly linked list는 data의 insert와 erase에 대해 장점을 가지고 있습니다. 모든 data를 node의 형태로 저장하고 있고, 두 data 간의 ordering을 pointer로 지정하고 있기 때문에 insert는 이전 node가 새로운 node를 가리키고 또 새로운 node가 다음 node를 가리키도록 modify하는 것으로 수행할 수 있습니다. 그 외에도 두 linked list를 concatenation하는 것 또한 각 list의 front node와 last node를 연결해주는 것으로 수행할 수 있기 때문에 빠르게 수행할 수 있다는 장점이 있습니다. 반면 arbitrary position에 대해 find operation을 수행하는 것은 항상 맨 첫 node에서부터 pointing하는 다음 node들을 차례로 탐색해야 하기 때문에 수행 시간이 길고, next node의 address를 각 node에 저장해야 하기 때문에 array에 비해 더 많은 memory space를 사용해야 한다는 단점이 있습니다.
- Run time of linked list operation
singly linked list에서 각 operation을 수행하기 위한 time complexity는 다음과 같습니다.
Front(1th) node | kth node | Last(nth) node | |
|---|---|---|---|
| Find | |||
| Insert before | *, ** | ** | |
| Insert after | * | ||
| Replace | * | ||
| Erase | *, ** | ||
| Next | * | N/A | |
| Previous | N/A |
* These assume we have already accessed the kth entry - $O(n) operation
** By replacing the value in the node, we can speed up
singly linked list의 특징으로는 front node에서의 operation이 모두 time으로 수행할 수 있어 그 특성이 매우 좋다는 점입니다. 단, arbitrary position에서 operation을 수행하기 위해서는 find operation이 선행되어야 하기 때문에 대부분의 상황에서 time이 필요합니다. 하지만 code 작성에서 한 번 search한 entry에 대해 여러 operation을 수행한다고 했을 때, find operation을 재차 수행할 필요가 없기 때문에 표에서와 같이 구분할 필요가 있습니다.
arbitrary position에서의 erase operation에 대해 잠시 설명하자면, 이전 node의 주소를 알지 못하기 때문에 이전 node가 다음 node를 point하기 위해서는 일반적으로 time이 필요합니다. 하지만, 만약 다음 node의 data를 copy해 현재 node를 replace한 후, 다음 node를 erase하는 operation으로 수정한다면 결과는 동일하지만 operation time을 으로 줄일 수 있습니다.
- Doubly linked list
singly linked list는 front node에서의 operation이 매우 빠른 반면, last node에서의 erase operation에 time이 필요하다는 단점이 있습니다. last node에 대해서도 front node의 좋은 특성을 활용하기 위한 data structure로 doubly linked list가 있습니다. doubly linked list는 한 node에서 두 개의 pointer로 이전 node와 다음 node를 모두 point해 양 방향으로 모두 search하도록 구현한 data structure입니다. last node에서 다음 node에 해당하는 pointer를 nullptr로 정한 것과 같이 front node의 이전 node를 nullptr로 가리키는 것이 필요합니다. doubly linked list는 last node와 first node가 동일한 특성을 가진다는 점과 여전히 concatenation에 유리하다는 장점을 가지고 있으나, singly linked list보다도 더 많은 memory space가 필요하다는 단점이 있습니다.
How to choose appropriate data structure?
지금까지 list를 구현할 수 있는 두 가지 방법인 array와 linked list에 대해 살펴보았다. 실제 data를 list의 형태로 저장하고자 할 때, 두 형태의 data structure 중 하나를 선택할 것이다. 여기서 어떤 structure를 사용할 지는 실제 code에서 어떤 oepration을 자주 사용하게 되는지가 매우 중요할 것이다.
만약 작성한 algorithm이 arbitrary position의 data search를 자주 수행해야 한다면 array가 적합한 data structure가 될 것이다. array는 find operation을 time에 수행할 수 있지만 linked list는 time이 필요하기 때문이다. 하지만 algorithm이 data insert와 erase를 자주 수행한다면 여기에 time으로 수행 가능한 linked list가 더 적합할 것이다.
ADT(Abstract Data Structure) : models of the storage and access of information
reference
"Data Structure & Algorithm Analysis in C++", 4th ed, Pearson, M. A. Weiss
