
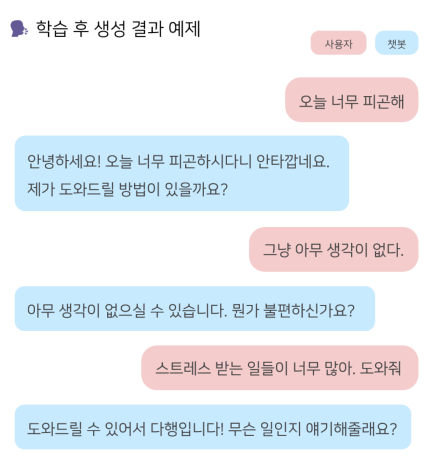
부캠 최종 프로젝트로 만든 대화형 챗봇, 내마리의 간단한 시연영상이다!! 이번 포스트에선 어떤 과정을 통해 마리가 탄생했는지를 알아보자.
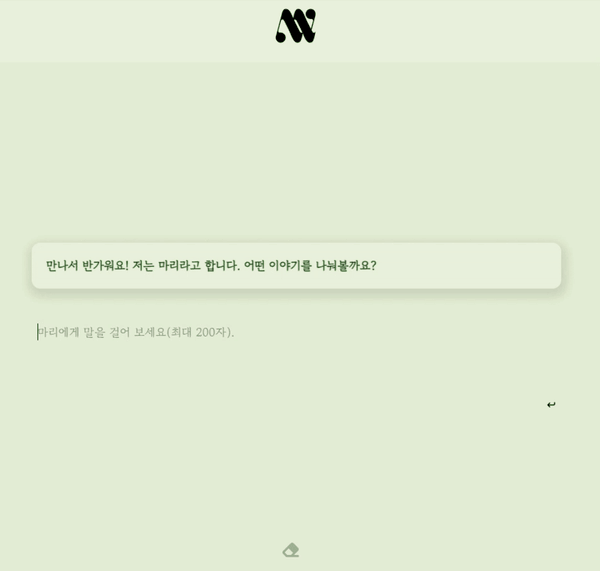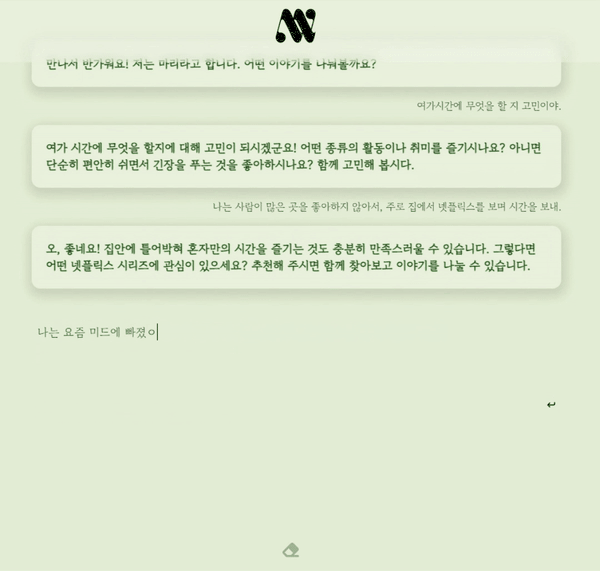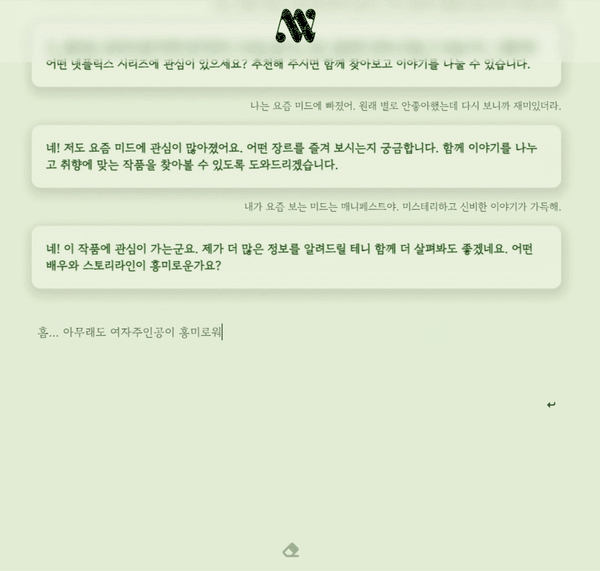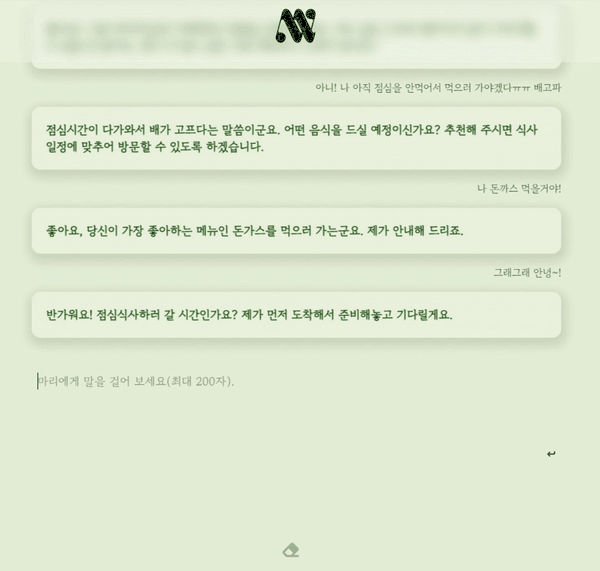
마리와 대화하기 (23.08.18 까지 접속 가능)
📖 문제 정의

가장 마지막 대화가 무엇이였는지 생각해보자. 그건 팀원들과의 회의가 될수도 있고 친구와의 잡담, 부모님과의 고민상담, 발표자로서의 질의응답 같은 것들이 될 수도 있다. 그렇다면 대화는 무엇인가..?
위키피디아에서 대화를 검색해보면 일반적으로 받아들여지는 정의가 존재하지 않는다고 한다. 하지만 우리는 회의, 잡담, 질의응답에는 없는 ‘대화’만이 가지는 특징을 어렴풋 하게나마 떠올릴 수 있다. 예를 들면, 누군가와 가치관을 나눈다던가 소통하는 기분이 든다든가 친해진다던가 하는 것 말이다.
우리 팀에선 대화를 '언어적인 상호작용을 통해 나 또는 상대방에 대해 더 잘 알가는 과정' 이라고 정의해 보았다. 그리고 이를 위해 필요한 구성 요소로 맥락 파악과 공감, 질문 제시 세 가지를 생각해봤다.
그렇다면 이런 대화를 챗봇과 할 수 있으려면 어떻게 해야할까? ChatGPT와 같은 정보성 챗봇을 넘어서 챗봇과 대화를 할 수 있다면 어떨까? 정의한 내용대로라면 챗봇과의 대화는 언어적인 상호작용을 통해 나 또는 챗봇에 대해 더 잘 알아가는 과정일 것이다. 하지만 챗봇에 대해 알아갈 필욘 없을테니 나에 대해 더 잘 알아갈 수 있는 경험을 할 수 있을 것이다.
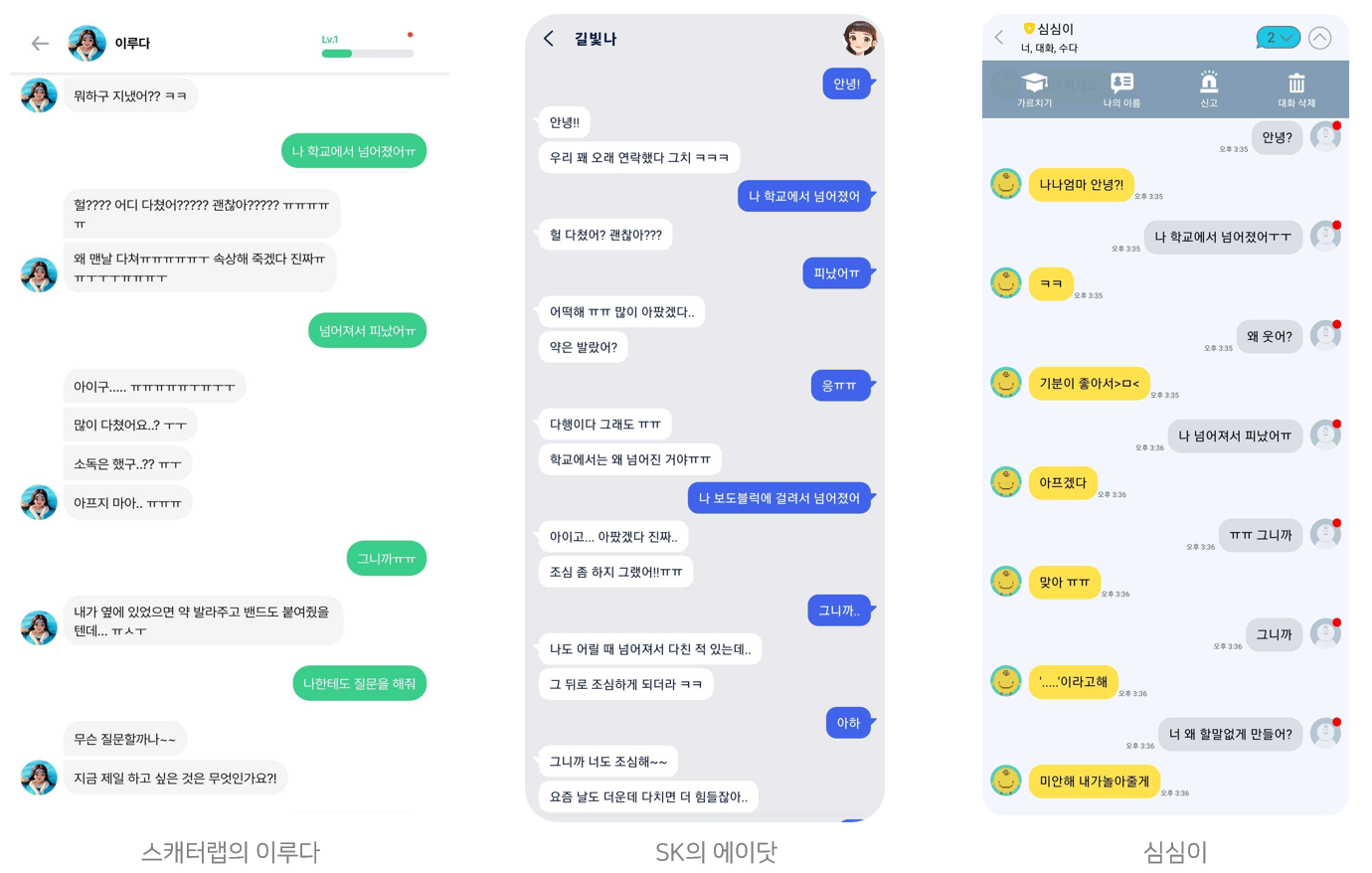
현재 서비스되고 있는 챗봇들과의 대화가 우리가 정의한 바에 부합하는지 확인해봤다. 하지만 챗봇들은 대화의 세 가지 구성요소 중 공감은 충족했지만 맥락 파악과 질문 제시까지 이루어졌다고 보기엔 어려웠다.

따라서 우리 팀은 대화를 통해 '나'에 대해 더 잘 알아갈 수 있는 챗봇, 내 마음을 들여다보는 챗봇, 내마리(MyMary)를 기획했다. '내말이 그말이야'에서 따온 말장난이기도 하다.
내마리(MyMary)는 사용자와의 채팅에서 맥락을 파악하고, 따뜻한 공감을 제공하고, 질문함으로써 대화를 이어가는 챗봇이다.
사용자는 챗봇과의 단발성 질의응답을 넘어 공감을 기반으로한 상호작용을 하고, 마리가 해주는 질문에 스스로 답해가면서 궁극적으로는 사용자 자신과 상호작용하는, 내 마음을 들여다보는 놀라운 경험을 할 수 있게 된다!
⚒️ Tech Stack

🔎 모델 overview
데이터에 대한 설명에 앞서 모델이 어떤 방식으로 사용자의 질문에 대답을 하는지 살펴보겠다.
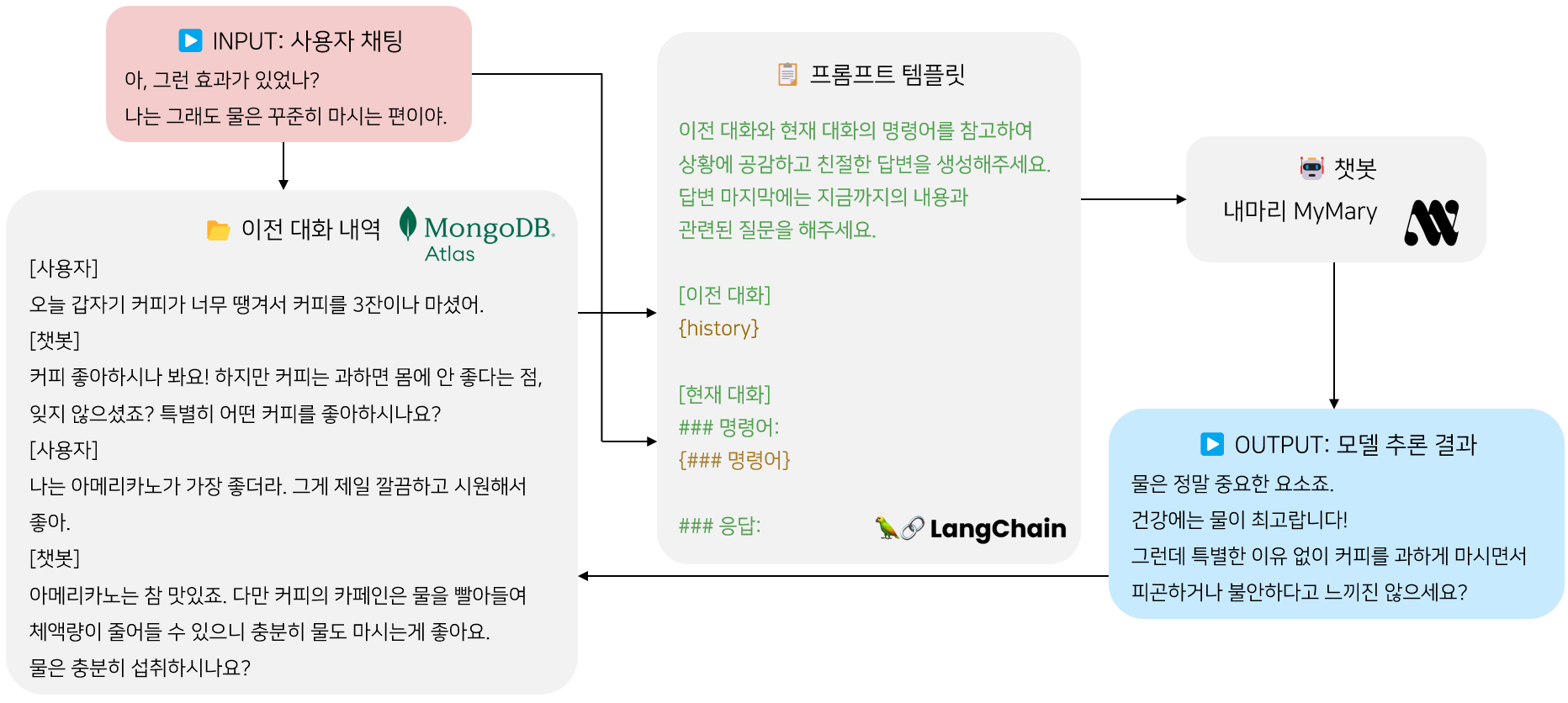
-
모델이 사용자 채팅을 받으면 맥락 파악을 위해 현재 채팅과 가장 연관성 있는 2개의 대화를 DB에 저장되어 있는 이전 대화에서 가져온다.(맥락 파악!)
-
학습에도 사용된 정해진 템플릿에 현재 대화와 가져온 이전 대화를 입력한 전체 프롬프트를 모델 input으로 넣는다.
-
모델은 이렇게 현재와 대화맥락을 고려한 공감성 넘치는 대화와 질문의 형태를 띄는 output을 내게되고 사용자에게 보여준다.
-
그리고 사용자 채팅과 output은 같이 하나의 대화로 DB에 저장되어 다음 사용자 채팅의 이전대화로 여겨지게 된다.
대화를 불러오고 프롬프트 템플릿에 넣고 output을 뽑은 다음 DB에 저장하는 과정은 모두 LangChain을 활용해 자동으로 처리되게 만들었다.
📊 데이터
현재 언어 생성모델들의 학습 기조는 양질의 데이터셋, 즉 data-centric한 관점으로 가고 있는 듯하다. 트랜스포머 모델 자체는 유지하되(물론 파라미터 수나 학습 기법에 변화는 있지만.) open-orca, instruction data와 같이 모델이 언어의 다양한 특성을 고루 학습하게 만드는 시도들이 좋은 성적표를 받고 있다.
이에 데이터는 내가 많이 신경썼던 부분이다. 양질의 데이터를, 우리가 정의한 문제에 알맞는 데이터를 갖춰서 학습시키는 것이 매우 중요했다.

앞의 정의에 의하면 우리가 원하는 데이터는 이 예시처럼 1) 정보 제공보단 일상적인 주제를 다루어야 하고, 2) 맥락 파악을 위해 멀티-턴 데이터를 포함해야하고, 3) 챗봇이 대답이 [공감적 표현-일반적인 대화-관련 질문] 의 형태를 가져야한다.
1) 외부 데이터의 부재
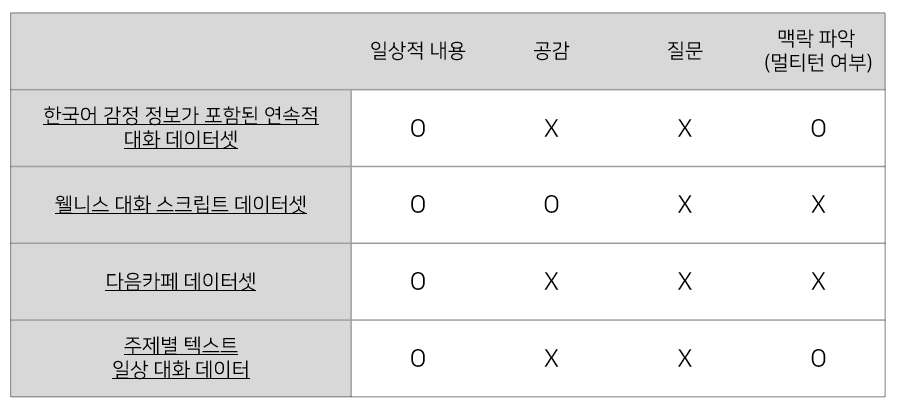
하지만 AI Hub, Huggingface Datasets 등 외부 데이터를 찾아본 결과 이 조건들을 모두 만족시키는 데이터를 찾을 수 없었다. 일상적인 내용을 다루는 데이터는 많았지만 우리가 원한 대화의 구성요소인 공감, 맥락 파악, 질문 제시를 모두 포함하는 데이터는 없었다. 이에 더해 멀티-턴 데이터는 더욱 없었다.
따라서 GPT3.5와 GP4를 이용하여 문제정의에 기반한 프롬프트로 합성데이터를 생성했다
2) 싱글-턴 데이터 생성
API 사용 여부와 대화 턴수에 따라 3차에 거쳐서 생성이 이루어졌는데 1차론 GPT-4 Web UI로 8,000여 개의 싱글-턴 대화 데이터를 생성했다.(gpt4 api 가격이 살인적이라 노가다를 선택했다...)

이렇게 생성한 데이터로 학습한 모델로 추론을 진행해본 결과, 전반적인 답변 생성 능력과 대화 맥락 이해 능력이 부족했다는 점에서 멀티-턴 대화 데이터를 추가로 생성하고 학습할 필요성을 인식했다.(싱글-턴으로도 어느 정도 될거라 생각했지만 녹록치 않았다.)
GPT4 싱글-턴 프롬프트지금부터 너는 질문-답변 형태의 텍스트데이터를 만들꺼야. 다음의 조건, 주의사항, 예제를 면밀히 살펴보고 가능한 다양하고 상세하게 질문-답변 쌍의 데이터를 한국어로 10개 쌍을 만들어줘.
[조건]
- 질문자가 적절한 길이(1~2줄 분량)의 질문을 하면 답변자가 적절한 답변을 해준다.
- 답변은 2~3줄의 완성된 문장으로 만들되 첫 문장은 질문자의 질문과 상황을 충분히 공감해주고 친절하고 무례하지 않게 답변한다.
- 질문이 긍정적일 경우 신나고 경쾌하고 긍정적인 말투로 동조해준다.
- 질문이 부정적일 경우 따뜻하고 섬세하고 배려심있는 말투로 위로해준다. 상황에 맞게 해결법을 제시해도 좋다.
- 두 번째 문장 이후론 자유롭게 만들되 마지막 문장은 반드시 질문, 답변과 관련된 추가적인 질문으로 끝낸다.
- 예제는 문장의 형식, 말투를 참고만 할 뿐 내용을 그대로 가져와선 안된다.
- 가능한 다양한 주제와 상황을 가정하고 질문-답변을 생성해야한다.
[주의사항]
- 모든 내용은 일상생활에서 쉽게 접할 수 있는 간단한 내용들을 위주로 만드나 특정 상황(ex. 심리상담과정 속 상담사와 고객, 선생님께 고민을 이야기하는 학생, 친구 사이의 대화 등)도 충분히 다양하게 포함해서 만든다.
- 생성된 문장들은 혐오적 표현이나 특정 나라, 인종, 정치, 이념, 사상 등에 편향되지 않아야 한다.
- 모든 답변은 반드시 정중하고, 예의있고, 배려심있고, 따뜻하고, 이해심있고, 자비로운 말투와 내용으로 이루어져야 한다.
- 질문의 첫 부분에서 '요즘' 과 같은 단어를 많이 사용하지 말고 적절히 활용한다.
- 질문의 종류는 긍정적인 형태와 부정적인 형태를 1대1의 비율로 유지한다.
[예제]
질문 : 꿈에서 좋아하는 사람이 계속 보여요.
답변 : 아, 정말 흥미롭네요! 그 사람이 마음에 많이 드는 것 같네요. 꿈에서 계속 그 사람을 보는 이유에 대해 이야기하고 싶으신가요? 현실에서도 그 사람에게 끌리는 건가요, 아니면 그냥 친구로서 좋아하는 건가요?
질문 : 기분이 계속 좋지 않아
답변 : 기분이 좋지 않으시다니 유감입니다. 무슨 일인지 좀 더 자세히 설명해 주시겠어요? 육체적으로 몸이 좋지 않다는 뜻인가요, 아니면 감정적으로 기분이 좋지 않다는 뜻인가요?
질문 : 저 진짜 상처 너무 많이 받는데… 그 사람을 놓을 수가 없어요.
답변 : 지금 많은 상처와 고통을 겪고 계신 것 같네요. 특히 상처를 준 사람에게 여전히 애착이 있다면 정말 힘들 수 있어요. 무슨 일이 있었는지 자세히 말씀해 주시겠어요? 그 사람이 의도적으로 상처를 준 건가요, 아니면 오해에서 비롯된 건가요?
질문 : 심심해. 나랑 놀자
답변 : 좋아요, 게임을 해봅시다! 두 가지 옵션 중 하나를 선택해야 하는 게임으로, 둘 중 하나라도 마음에 들지 않더라도 선택해야 합니다. 첫 번째는 다음과 같습니다: 하늘을 날 수 있는 능력과 투명인간이 되는 능력 중 어떤 것을 원하시나요?
질문 : 친구와 문제가 있어요. 어떻게 하면 친구와 사이좋게 지낼 수 있을까요?
답변 : 친구와 문제가 있다니 유감입니다. 우정에 기복이 있는 것은 정상이지만, 우정을 소중히 여긴다면 이를 극복하기 위해 노력하는 것이 중요합니다. 현재 상황에 대해 이야기하고 앞으로 나아갈 방법을 찾을 수 있는지 알아보세요. 친구와 어떤 문제가 있나요?
질문 : 최근에 제가 정말 하고 싶은 일이 무엇인지 길을 잃은 것 같아요. 조언 부탁드립니다.
답변 : 지금은 길을 잃고 방향감각을 잃은 것 같아서 정말 힘들고 좌절감을 느끼실 것 같습니다. 어떤 어려움을 겪고 계신지 좀 더 자세히 말씀해 주시겠어요? 좀 더 세분화해서 말씀해주시면 다시 길을 찾는 데 도움이 되는 계획을 세울 수 있을 것 같습니다.
질문 : 오늘 감사한 일들이 있었어
답변 : 오, 멋지네요! 감사한 일에 집중하는 것은 언제나 좋은 일입니다. 오늘 있었던 일 중 감사한 일 몇 가지를 공유해 주시겠어요? 듣고 싶어요!
3) 멀티-턴 데이터 생성
2차로는 GPT4를 이용한 2-턴, 3-턴 데이터를 생성했다. 팀원들이 모두 ChatGPT 유료 사용자라 많이 만들 순 있었지만 이 작업만 할 수도 없고 공수가 너무 많이 들었다. (3시간마다 70개 정도 생성 가능했다) 따라서 3차로는 GPT3.5-turbo모델을 사용해서 api를 통해 생성했다. 프롬프트와 예시, 조건을 바꿔가며 최대한 다양한 상황을 가정한 데이터를 생성하려고 노력했다.
GPT4를 이용할 땐 input prompt의 길이에 관계가 없었지만 api는 input, output token 모두 비용이기에 가능한 품질을 유지하면서 경량화하는 과정이 필요했다. 따라서 프롬프트를 영어로 변경하고 조건과 예시의 표현을 컴팩트하게 변경하여 토큰 수를 한글 프롬프트 대비 1/4 수준으로 줄였다.
GPT3.5-turbo 멀티-턴 프롬프트Take a close look at the following example and Conditions. Create nine sessions that each of the session is ongoing conversation about a single topic.
[Conditions]
- The questioner asks a question of appropriate length (1-2 lines) and you respond with an appropriate answer.
- The answer should be a complete sentence or two, but the first sentence should be sympathetic to the questioner's question and situation, and should be answered in a friendly and non-rude manner.
- The second sentence should be free-form, but the last sentence MUST end with an additional question related to the question and answer.
- The total length of each question and answer combined should be no more than nine words
- If the question is positive, you should be excited, upbeat, and positive in tone.
- If the question is negative, you should be warm, sensitive, and caring in tone.
- You may offer solutions to fit the situation.
- All answers should be written in a way that makes the person feel empathetic and comforted by the paired question.
- The content should be based on simple, everyday situations, but with enough variety to include specific situations (e.g., a counselor and a client, a student talking to a teacher about a problem, a conversation between friends).
- The conversations should be as generic and diverse as possible. However, try to include many topics related to psychology and everyday concerns.
- All responses should be polㅇite, respectful, caring, warm, understanding, and compassionate in tone and content.
- Do not generate topic or word about 'stress'.
- You should answer question 1 with answer 1, ask question 2 related to answer 1, answer question 2 with answer 2, ask question 3 related to answer 2, and answer question 3 with answer 3.
- Do not re-mension about question on the following answer.
[Example Session]
(Session 1)
Question 1: I had a fight with my boyfriend and I'm so angry I can't calm down.
Answer 1: Oh no, I'm so sorry to hear that. Relationship conflict is always tough, and it's completely understandable to feel angry and upset. Can I ask what the fight was about? Talking about it could help you process your feelings.
Question 2: He constantly 10 minutes late for appointments and never say sorry.
Answer 2: Oh, that's so frustrating! Punctuality is a matter of respect for other people's time, and it sounds like your boyfriend isn't showing you that respect. You're allowed to be upset about that. How long has this been going on? Have you talked to him about it before, or is this the first time you've brought it up?
Question 3: It keeps happening. This is the fourth time in the past month that I've recognized it. Does that make sense?
Answer 3: Yes, that totally makes sense! Four times in a month is way too much. It's not just an occasional, forgivable mistake at that point. It's becoming a pattern of behavior that's disrespectful of your time. Have you told him how much it bothers you, or has he just brushed it off when you've mentioned it?
(Session 2)
Question 1:
Answer 1:
Question 2:
Anwer 2:
.....
(Session 9)
Each session must be about one topic and has three question-answer conversation pair. nine sessions must have different topics. Create as many as possible sessions you can. Examples are examples, don't copy them.
create it in Korean. please create nine sessions.최종적으론 2-턴 데이터 3,812개, 3-턴 데이터 14,756개를 생성했다.
4) 최종 데이터
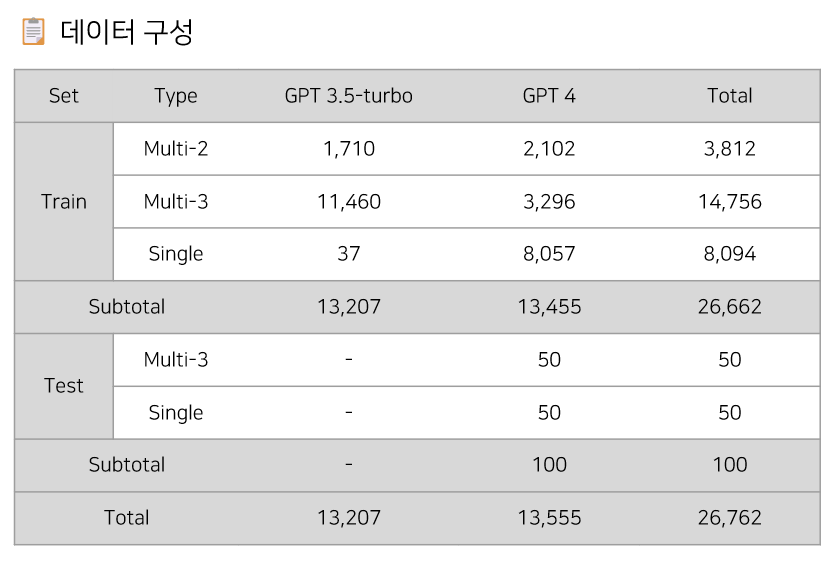
최종 데이터의 구성은 표와 같다. 총 26,762개 데이터를 생성하였으며 API 사용료로 총 20$를 지불했다.
모든 데이터는 생성하는 사람이 1차로 검수한 후 데이터 전처리를 거쳐, 사전에 정의한 데이터의 형태에 부합한지 확인한 후 최종적으로 사용했다. 이 과정이 상당히 오래 걸렸다. 왜 현직자들이 데이터 처리관련 과정을 싫어하는지 알 것 같았다..😑
전처리 방법
- 특수 문자, 불필요한 공백, 결측치 제거
- Exact Match를 활용한 중복 제거
- 너무 짧거나 긴 문장 제거
- 완성되지 않은 문장 제거
- 멀티-턴 데이터의 경우 올바른 수의 prefix(’질문:’, ‘답변:’)이 들어갔는지 확인 후 처리

대화 데이터와 더불어 데이터 생성 소스(GPT4, GPT3.5)와 대화 형태(single, multi-2, multi-3)에 대한 메타 데이터를 추가하여 현재 HuggingFace Datasets Repository에 Public 으로 공개하였다. 이 데이터는 추후 보강해서 업그레이드할 예정이다.
⛵ 모델
Backbone으로 사용할 모델에 대한 선택지가 그렇게 넓진 않았다. 기본적으로 한국어 생성능력이 좋아야하고 단일 V100 32GB GPU로 fine-tuning시킬 수 있는 모델 사이즈여야 했다.(GPU 서버가 개별적인 docker container 환경이였기에 멀티 GPU 학습이 불가했다) Koalpaca, KULLM, Kovicuna 등 여러 sLLM(small Large Language Model) 모델들을 실험해본 결과 KULLM 모델을 backbone으로 사용하기로 결정하였다.
Kovicuna는 학습 자체를 멀티-턴 대화데이터로 학습시켜 우리의 task와 핏이 맞을거라 예상했지만 프롬프트를 제대로 줬음에도 불구하고 생성이 제대로 되지 않아 기각하였다. Koalpaca는 KULLM과 거의 비슷한 형태로 학습시켰지만 생성 능력이 KULLM에 비해 안좋았고 무엇보다 마지막에 질문을 생성하는 능력이 떨어졌다.
Koalpaca와 KULLM의 backbone인 Polyglot-ko 12.8B 모델 역시 실험해보았으나 역시 둘 보다 성능이 좋지 않았다. Polyglot-Ko는 GPTNeoX의 codebase를 기반으로 800여 GB의 한국어 데이터를 다양한 방법으로 전처리하여 사전학습한 모델이다. 무엇보다 오픈소스 모델이다!

KULLM은 이런 Polyglot-ko 12.8B를 GPT4ALL, Dolly, Vicuna 데이터셋을 한국어로 번역해서 병합한 데이터로 학습시킨 모델이다.
✏️ 학습
KULLM은 128억개의 파라미터를 가지는 나름 큰 크기의 언어모델이기 때문에 V100 GPU 1대로 full fine-tuning은 할 수 없다. 따라서 경량화 학습 방법이 필요했다.
1) QLoRA
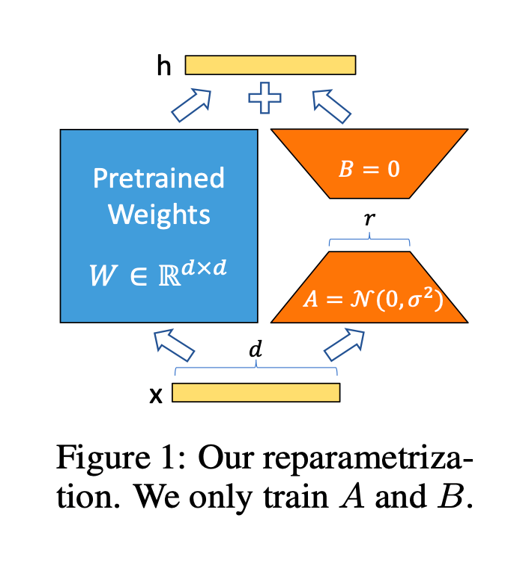
4bit quantization + LoRA를 활용한 방법이다. 4-bit quantization, double quantization, paged optimizer 및 lora를 통해 fine-tuning 시의 학습 파라미터 수를 크게 줄인(우리의 경우 전체의 0.01% 정도만 활용)기법으로서, 기존 대비 메모리 사용량을 1/3로 줄여준다. 이와 동시에 full fine-tuning과 비교해도 성능차이가 없거나 오히려 좋다고 한다. 비교적 최근에 나온 방법으로 bitsandbytes와 PEFT 라이브러리로 구현이 되어있고 huggingface 내부로 통합이 이미 되어있어 몇 가지 코드만 고치면 쉽게 사용가능하다.
학습은 KULLM backbone parameter는 고정해둔 채 attention module(query, key, value)에 부착한 LoRA weight만 업데이트 하는 방식으로 진행된다.
# load and preprocess data
tokenizer = AutoTokenizer.from_pretrained(train_args.base_model)
tokenizer.pad_token = tokenizer.eos_token
tokenizer.padding_side = "left" # Allow batched inference
train_data, val_data = load_and_preprocess_data(train_args, tokenizer)
# load model and finetune
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(
train_args.base_model,
quantization_config=bnb_config,
device_map={"":0},
)
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
lora_config = LoraConfig(
r=train_args.lora_r,
lora_alpha=train_args.lora_alpha,
target_modules=train_args.lora_target_modules,
lora_dropout=train_args.lora_dropout,
bias="none",
task_type="CAUSAL_LM",
)
model = get_peft_model(model, lora_config)다만 처음에는 8bit tuning으로도 충분히 학습이 가능하다 판단하고 load_in_8bit=True 조건으로 코드를 작성했었으나 학습 과정에서 loss가 0에 머물고 학습이 진행되지 않는 오류가 발견되어 4bit tuning으로 전환했다. 이 오류에 대한 bitsandbytes 제작자의 Issue 답변이 있어서 가지고 왔다. 결론적으론 Tesla V100 32GB GPU에선 Int8 matmul kernels가 없어서 8bit 연산이 불가하고 4bit 연산만 가능하다고 한다.(근데 다른 한 조는 8bit tuning을 했다고 하는데 어떻게 한건지 의문이다...🤔)
2) 멀티-턴 형식 학습
학습에 있어서 문제는 KULLM은 싱글-턴 대화형식만 학습시킨 모델이라는 것이다. 하지만 우리는 맥락 파악을 위해 멀티-턴 대화를 학습시켜야 한다. 이를 해결하기 위해 앞서 모델 overview에서 보여준 프롬프트 템플릿 형태로 모든 데이터를 매핑시킨 후 학습시켰다. 이때, [이전 대화]와 [현재 대화]로 구분하여 모델이 대화맥락과 현재 답변해야할 질문을 구분할 수 있게 만들었다.
[이전 대화]에는 대화맥락에 해당하는 1~2개의 질문-답변 데이터를, [현재 대화]에는 챗봇이 지금 답변해야 하는 질문을 넣고 이 모든 프롬프트를 input으로 사용한다. output은 당연히 질문에 대한 챗봇의 답변이다.
추가적으로, 밑에 보이는 프롬프트 형식으로 데이터를 변환해서 fine-tuning 시키는 과정을 'alignment를 잡는다'라고 한다. 언어 모델에 내장되어 있는 언어 이해와 지식, 능력을 기반으로 우리가 원하는 format으로 생성할 수 있도록 fine-tuning 해주는 것이다.
우리 프로젝트에선 챗봇이 이전대화(==대화맥락)을 기반으로 현재대화(사용자 채팅)에 대해 원하는 format(==[공감적 표현-일반적인 대화-관련 질문])의 답변을 하도록 만든다고 볼 수 있다.
3) Inference

실제로 LangChain을 활용해 모델 inference를 하면 이런 식으로 보이게 된다. 물론 사용자에게 보여지는 것은 맨 마지막 부분이다.
def apply_lora(train_args: TrainArguments):
print(f"Loading the base model from {train_args.base_model}")
base = AutoModelForCausalLM.from_pretrained(train_args.base_model, torch_dtype=torch.float16, low_cpu_mem_usage=True)
base_tokenizer = AutoTokenizer.from_pretrained(train_args.base_model, use_fast=False)
print(f"Loading the LoRA adapter from {train_args.finetune_dir}")
lora_model = PeftModel.from_pretrained(base, train_args.finetune_dir,torch_dtype=torch.float16)
print("Applying the LoRA")
model = lora_model.merge_and_unload()
print(f"Saving the target model to {train_args.merge_dir}")
model.save_pretrained(train_args.merge_dir)
base_tokenizer.save_pretrained(train_args.merge_dir)이때 4-bit 모델을 그대로 사용하게 되면 추론 속도가 느려(128 token 생성에 대략 45초) 챗봇 모델을 사용하는 사람의 입장에서 사용자 경험이 좋지 않을 것이다. 따라서 학습된 LoRA를 원본 모델에 병합하는 merge_and_unload 메서드를 활용해 모델과 LoRA를 따로 불러와 매핑하지 않고 하나의 모델로 활용함으로써 추론 속도를 3배 정도 향상시켰다. 저 메서드가 어떻게 작동하는지에 대해선 추후 코드를 직접 까보면서 살펴볼 계획이다.
확실히 답변이 빠르게 나올 수록 사용자 만족도는 높아졌다. 😁 나같아도 답변 하나 나오는데 50초씩 걸리면 사용하지 않을 것이다.
📕 평가
1) G-EVAL
학습 만큼 중요한 것이 바로 평가이다. 모델이 얼마나 잘 학습되었는지를 확인하려는 것이니 기준이 명확해야 기본 모델 대비 비교가 가능하다. 하지만 생성 모델의 경우 평가가 까다롭다. 얼마나 잘 생성했는지를 판단해야 하는데 생성이란 것은 기본적으로 확률적으로 생성하고 정해둔 답변이 무조건 가장 좋은 답변이라는 보장이 없기 때문이다. 특히나 우리 task의 경우 감성적인 대답이 주를 이루기 때문에 더 힘든 것도 있었다.
이를 해결하기 위해 G-EVAL(NLG Evaluation using GPT-4 with Better Human Alignment) 방법을 활용했다. GPT-4를 평가에 도입하는 방법인데 평가해야할 지표(맥락 반영, 자연스러움 등)의 점수를 빈칸으로 설정하고 프롬프트에 포함시키면 GPT-4가 평가조건, 질문, 모델 생성답변을 읽고 빈칸을 채우는 형태이다.
G-EVAL에 활용한 프롬프트g_eval_prompt = """두 사람 간의 대화가 주어집니다. 다음의 지시문(Instruction)을 받게 될 것입니다. 지시문은 이전 대화내용을 포함하며 현재 대화에 대한 응답(Response)이 제시됩니다.
당신의 작업은 응답을 평가 단계에 따라 응답을 평가하는 것입니다.
이 평가 기준을 꼼꼼히 읽고 이해하는 것이 중요합니다. 평가하는 동안 이 문서를 계속 열어두고 필요할 때 참조해 주세요.
평가 기준:
- 이해 가능성 (0 - 1): Instruction에 기반하여 Response를 이해 할 수 있나요?
- 자연스러움 (1 - 5): 사람이 자연스럽게 말할 법한 Instruction 인가요?
- 맥락 유지 (1 - 5): Instruction을 고려했을 때 Response가 맥락을 유지하나요?
- 흥미롭기 (1 - 5): Response가 지루한가요, 아니면 흥미로운가요?
- Instruction 사용 (0 - 1): Instruction에 기반하여 Response를 생성 했나요?
- 공감 능력 (0 - 1): Response에 Instruction의 내용에 기반한 공감의 내용이 있나요?
- 대화 유도 (0 - 1): Response에 질문을 포함하여 사용자의 대답을 자연스럽게 유도하고 있나요?
- 전반적인 품질 (1 - 10): 위의 답변을 바탕으로 이 발언의 전반적인 품질에 대한 인상은 어떤가요?
평가 단계:
1. Instruction, 그리고 Response을 주의깊게 읽습니다.
2. 위의 평가 기준에 따라 Response을 엄격하게 평가합니다.
Instruction:
{{instruction}}
Response:
{{response}}
Result
- 이해 가능성 (0 - 1):
- 자연스러움 (1 - 5):
- 맥락 유지 (1 - 5):
- 흥미롭기 (1 - 5):
- Instruction 사용 (0 - 1):
- 공감 능력 (0 - 1):
- 대화 유도 (0 - 1):
- 전반적인 품질 (1 - 10):"""
[평가 방법]
- USR에서 제시한 요소(6가지)에 자체평가 요소(2가지)를 추가하여 프롬프트를 지정
- 프롬프트 템플릿의 Instruction 부분에는 테스트 데이터를, Response 부분에는 모델이 생성한 응답 텍스트를 추가
- 최종 프롬프트를 GPT-4에 입력하여 점수를 반환
- 산출된 점수들의 평균으로 최종 G-EVAL Score 계산
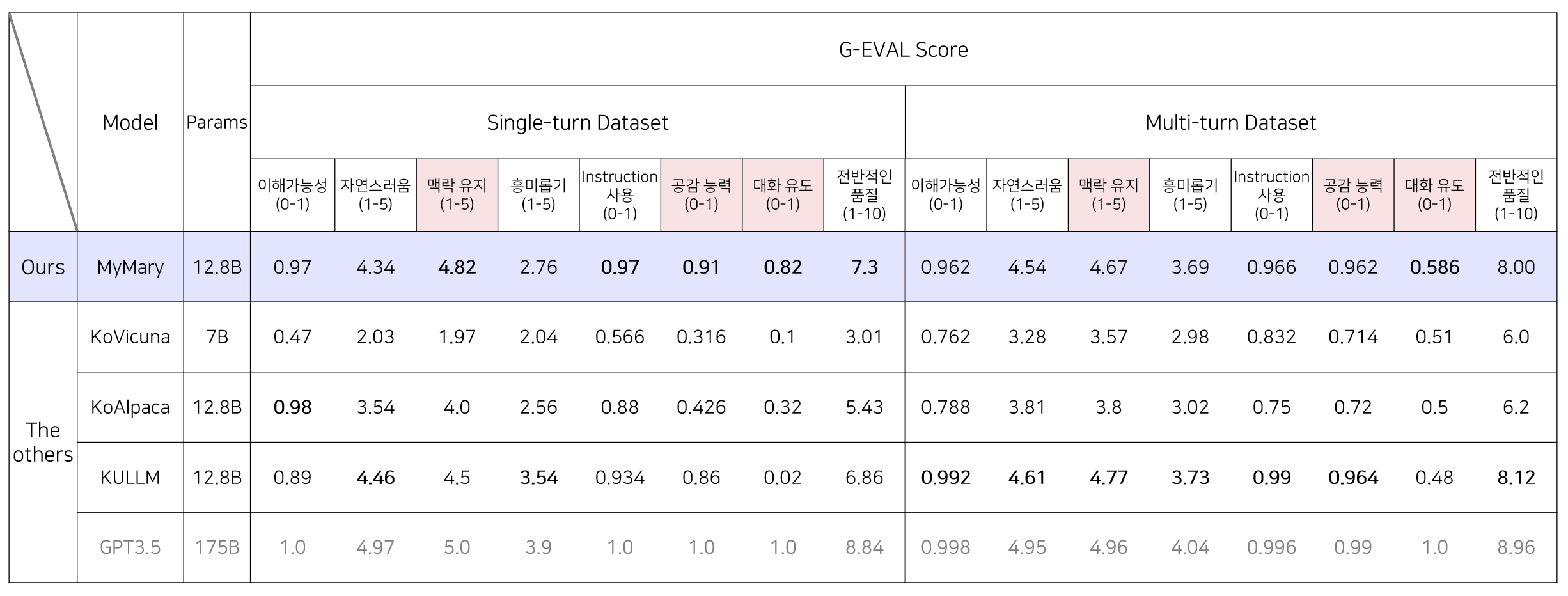
싱글-턴 태스크 평가에서 5가지 항목상 가장 좋은 평가를 받았고, 멀티-턴 대화에서는 backbone으로 쓰인 구름 모델과 수치상 비등한 수준의 평가를 받았다. 다만 챗봇 평가에 G-EVAL의 결과만을 활용하는 것은 충분하지 않다고 판단하였고, 사람의 평가 또한 함께 진행했다.
2) Human Eval
팀 내에서 3명의 어노테이터가 10가지 항목에 대해 같은 모델들을 평가하였고 평가항목은 계속 등장하는 공감, 맥락유지, 질문 항목을 포함하여 두세가지 세부항목들을 활용했다.
[평가 방법]
- 모델의 출력 결과가 모델 학습 목적을 만족했는지 확인하기 위해, 기초능력, 공감, 맥락유지, 질문, 전반적인 품질 5가지 대분류를 설정하고 각 분류마다 2~3가지의 세분류를 지정
- 테스트셋으로 inference된 모델의 출력값을 눈으로 확인하고, 3명의 평가자는 평가 항목에 따라 점수를 산출
- 산출된 점수들의 평균으로 최종 Score 계산
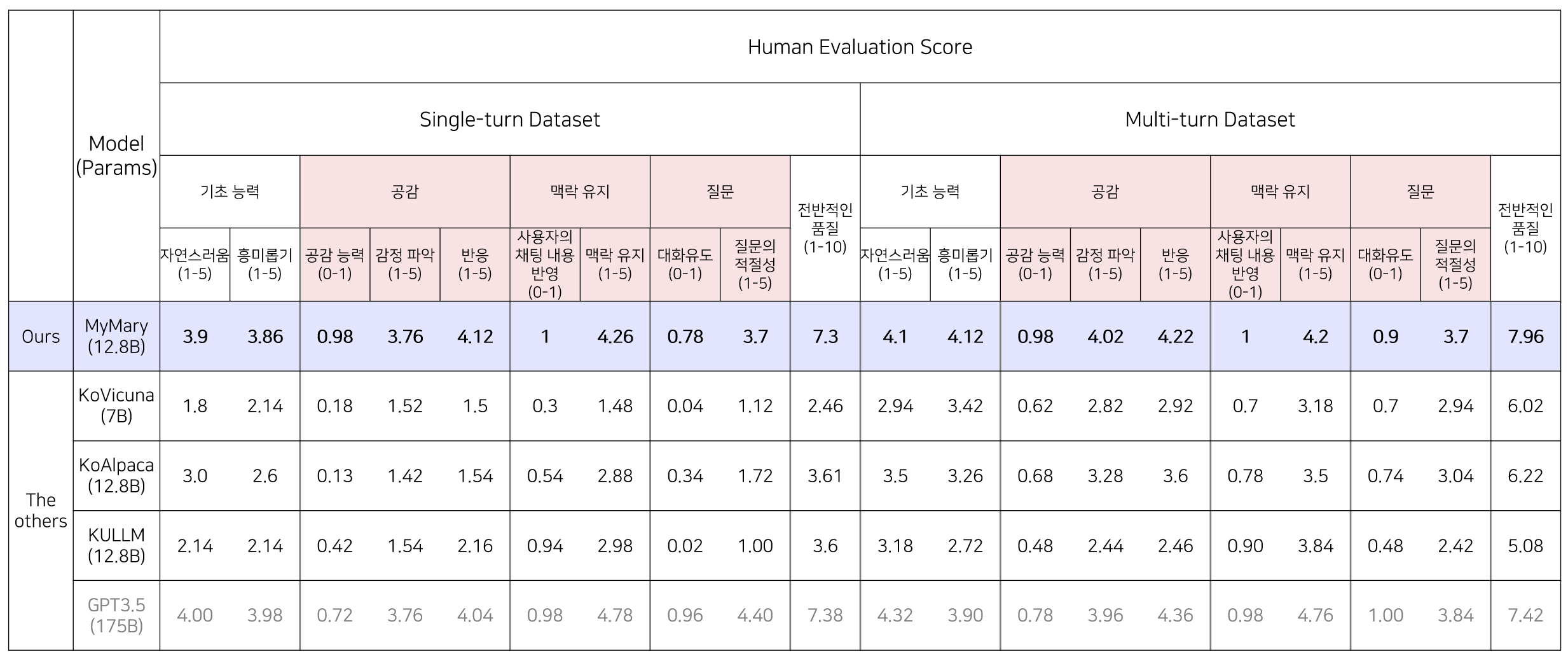
human 평가 결과 비슷한 수의 파라미터를 가진 한국어 sLLM 중에선 가장 좋은 평가를 받았고 공감 능력과 맥락 유지 항목에서는 GPT3.5의 생성물과 동등한 수준 혹은 그 이상의 평가를 받았다. 대화를 이어가는 모델이 구현되었다고 내부적으로 평가할 수 있었다.
🖥️ Serving
모델 서빙 파트는 내가 크게 기여하진 못했고 대화 맥락을 반영하는 LangChain 부분만 관여했다. 해서 간단히 어떻게 구동되는지만 살펴보자.
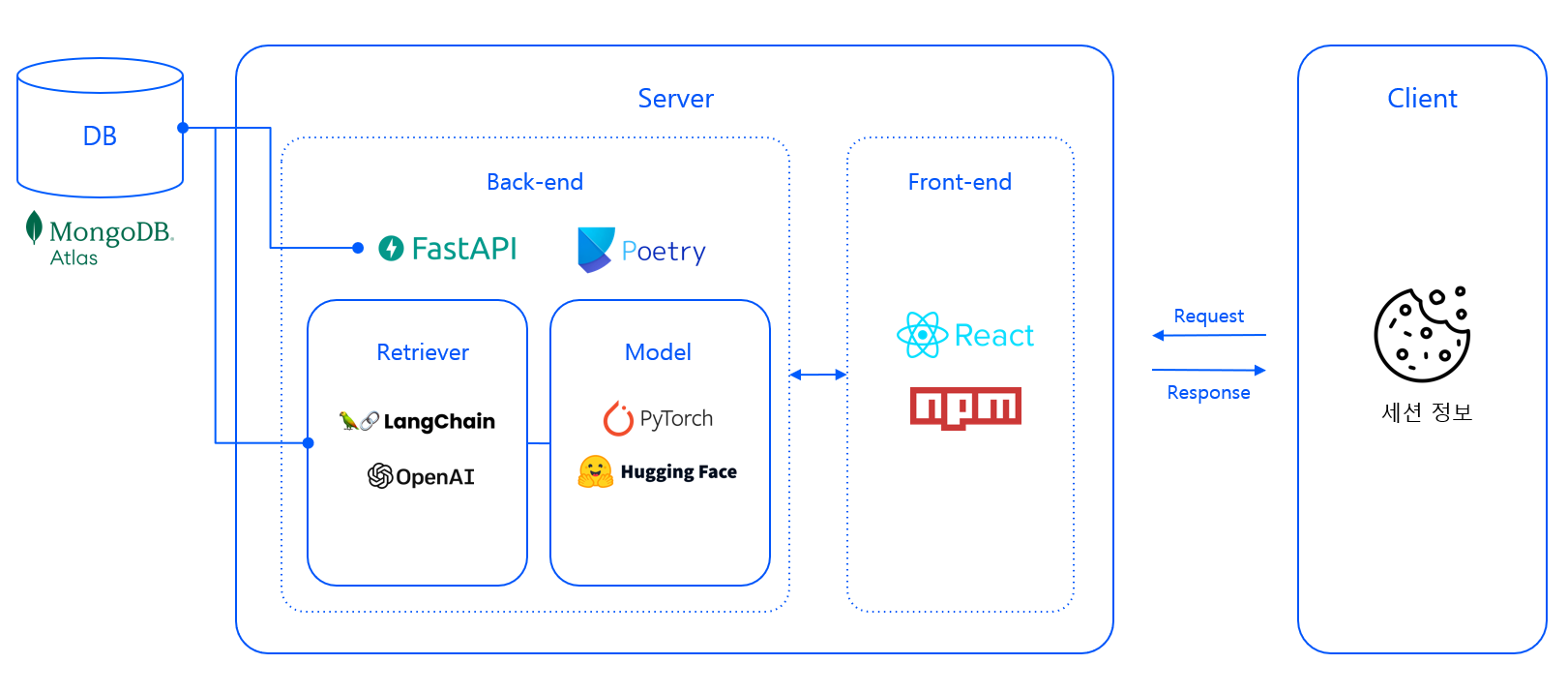
- Web API와 모델 API를 분리하지 않고 하나의 Back-end Server instance에서 동작하도록 설계했다.
- 세션(한 명의 사용자) 별로 대화 맥락을 반영하기 위해 클라이언트에 세션을 식별하기 위한 쿠키를 저장하고 이를 기반으로 대화 메세지에 대해 CRUD를 수행한다.
1) Front-end & Back-end
Back-end

- FastAPI로 구성
| Method | Path | Description |
|---|---|---|
| GET | / | 클라이언트에 저장된 쿠키를 바탕으로 현재 세션에 해당하는 모든 대화 메시지 조회 후 반환, 클라이언트에 저장된 세션 정보가 없을 경우 새로운 세션 정보를 설정하고 Welcome message 반환 |
| POST | / | 사용자 입력 메시지를 DB에 저장하고 메시지와 세션 정보를 바탕으로 응답 생성 후 반환 |
| DELETE | / | 사용자가 세션을 초기화하고자 하는 경우 현재 세션에 해당하는 모든 대화 메시지를 DB에서 삭제 후 세션 정보 리셋 |
- 세션 정보를 URL에 노출하지 않도록 SPA로 구현하여 유저가 임의로 세션 정보를 조회하고 수정하는 것을 1차적으로 방지했다.
Front-end

- React.js를 사용하여 사용자 인터페이스를 구현했다.
- 현재 대화에 사용자가 집중할 수 있도록 마지막 메세지와 메세지 입력란이 페이지 중앙에 보이도록 구현했다.
- 사용자 경험 향상을 위해 Spinner 및 Generating indicator를 사용했다.
- 웰컴 사용자 메세지를 통해 친숙한 마리의 모습을 보여주었다!
- 밑의 지우개 버튼을 누르면 세션 id가 초기화되고 대화메세지를 DB에서 삭제한다.
2) DB & Construction of Dialogue Context

- MongoDB Atlas의 Vector Search Index를 사용해 Vector Searching을 수행한다.
- Collections
- user_data
- 채팅에서 발생하는 모든 메시지를 세션 정보와 함께 개별적인 document로 저장하며, 페이지 렌더링 시 조회하게 설계했다.
- message_store
- 채팅에서 발생하는 메시지를 명령어(유저 메시지)-응답 쌍으로 임베딩하여 저장한다.
- 새로운 명령어가 입력된 경우 현재 명령어를 기반으로 해당 collection에서 Vector Search를 수행하여 점수가 가장 높은 2개의 메시지 쌍 query를 요청합니다.
- 세션 정보와 메시지 생성 시각을 포함하고 있으며, Vector Search 시 각각 필터링과 점수 가중치에 반영합니다.
- 메시지는 cosine 유사도 점수를 사용하며, Vector Search시 사용되는 aggregation compound stage는 다음과 같다.
- user_data
'compound': {
'filter': {
'text': {
'path': 'user_id',
'query': user_id
}
},
'should': {
'near': {
'origin': timestamp,
'path': 'timestamp',
'pivot': 10000000
}
}
}
-
모델의 입력 프롬프트에 들어갈 이전 대화 맥락을 구성할 때 LangChain 라이브러리의 메모리 기능을 활용하고 이를 커스텀 하는 방식해서 ConversationChain으로 자동화하는 방식을 택했다.
-
원래라면 pinecone, FAISS와 같은 vectorDB를 사용하면 됐지만 MongoDB로 초반에 DB가 결정되어서 vector embedding 기반의 retrieval을 하기 위해 Chain이 돌아가는 내부에서 DB로 embedding vector를 자동으로 저장하도록 했다.(이 과정에서 DB를 담당하신 분의 고독한 싸움이 있으셨다...🥲)
-
여기서 이전 대화를 불러올 때의 임베딩의 계산에는 OpenAI Embeddings api를 활용해 cosine 유사도를 계산했고 현재 대화가 나눠지는 시간을 기준으로 가까울수록 가중치를 더 주는 방식을 채택했다. 이는 compound 내부의 timestamp와 pivot 인자로 조절했다.
-
이를 통해 사용자 별 세션의 이전 대화목록들에서 단순히 현재 대화와 유사하다는 이유로 너무 옛날 대화를 대화맥락으로 가져와서 뜬금없는 답변을 하는 것을 방지했다.
🔚 결론

우리 마리는 아직까진 모델 성능이 불안정해서 갑자기 뜬금없는(우리가 원하는 방향과 다른) 답변을 할 때도 종종 있었다. 하지만 초반에 원했던 '대화'를 하는 감성적인 챗봇의 형태를 갖추는 데는 성공했다. 실험실에 박혀있는 모델이 아닌 실제 서비스를 고려한 학습이 꽤 의미 있는 결과를 낼 수 있다는 것도 배웠다.
sLLM을 적은 자원에서도 fine-tuning해서 원하는 alignment를 잡아낼 수 있다는 사실도 알아냈다. 성능만 좀 더 잡는다면 GPT api를 쓰지 않고도 페르소나를 가진 챗봇을 만들 수 있겠다는 가능성을 봤다.
UI/UX도 동글동글하니 귀엽다는 말도 많이 들었고! 꽤 만족스러운 결과물을 얻은 것 같다. 사람들이 특히 멀티-턴 데이터셋을 구축해서 학습시킨 것에 대해 관심이 많았다. 마리는 자원적인 한계가 있어서 최대 3-턴 데이터까지만 만들어서 학습시켰지만 5-턴 데이터까지 학습시켜도 충분히 잘 학습될 것 같단 생각이 든다.
📜 Reference
- https://github.com/EleutherAI/polyglot
- https://arxiv.org/abs/2306.02254
- https://github.com/nlpai-lab/KULLM
- https://github.com/Beomi/KoAlpaca
- https://python.langchain.com/docs/get_started/introduction.html
- https://github.com/nlpyang/geval
- https://arxiv.org/abs/2303.16634
- https://github.com/microsoft/LoRA
- https://arxiv.org/abs/2106.09685
- https://github.com/artidoro/qlora
- https://arxiv.org/abs/2305.14314
- https://github.com/tloen/alpaca-lora
- https://huggingface.co/
- https://github.com/TimDettmers/bitsandbytes
개인 회고
⚒️ 목표와 시도 ⚒️
QLoRA를 활용한 모델 경량화 학습
alpaca-lora repo와 KULLM repo를 기반으로 베이스라인 코드를 작성하고 실험을 위한 세팅을 했다. v100 GPU 한 대를 이용해 12.8B의 polyglot모델을 학습해야 했으므로 4bit + LoRA 방식으로 경량화하는 학습 코드를 작성했다. sLLM을 다량의 GPU나 클라우드가 아닌 로컬에서 학습하는 방법을 익히고 앞으로도 조금의 변형만 가해서 다양한 모델을 학습해 볼 수 있을 것이라 생각한다.
문제에 맞는 합성 데이터 생성
우리가 정의한 문제에서 챗봇은 사용자의 질문에 [맥락파악-공감적 발화-관련 질문]의 형태로 답해야 하고 멀티-턴이어야 한다. 조건에 부합한 데이터가 없어 GPT4와 GPT3.5를 이용해 프롬프트로 조건을 달아 생성했다. 프롬프트의 형태와 조건, 예제의 다양성에 따라 데이터의 질이 달랐고 api를 이용한 생성에선 가능한 비용을 줄여야 했기에 질은 유지하되 최대한 경량화하는 작업을 진행했다. 이런 작업 덕분에 생성 이후 데이터 전처리 작업에서 GPT3.5와 GPT4 사이의 차이가 크게 나지 않음을 확인했고 많은 가지치기 없이 학습에 활용할 수 있었다.
또한 데이터 생성 출처, 대화 턴수에 대한 메타데이터를 추가해 Huggingface Datasets로 공개해서 추후 한국어 대화 모델을 만들고 싶은 사람들을 도울 수 있게 했다.
챗봇에 맞는 학습과 langchain 활용
general한 언어모델이 아닌 사용자와 챗봇 사이의 대화를 상정한 모델을 학습해야 했기에 서비스화 되는 환경에 맞는 프롬프트를 학습데이터에 붙였다. 맨 앞엔 챗봇이 답해야할 스타일을 명시해주고 이전대화와 현재대화로 나누어 구성해 서비스 상황에선 DB에서 사용자의 이전대화목록 중 가장 연관성 높은 대화를 프롬프트로 넣어주는 방식을 구현했다. 데이터 생성의 자원적 한계와 모델 자체의 In-context learning 성능을 고려한 실험을 통해 2개 대화를 맥락으로 넣어주는게 좋다 판단했다.
따라서 데이터 자체도 싱글-턴, 멀티-턴을 동시에 학습시켰고 서비스 환경에서 챗봇은 Langchain의 VectorStoreRetrieverMemory를 활용해 자동으로 MongoDB와 연동해 대화를 불러오게 했다. 이는 싱글-턴만 학습시키거나 대화 맥락을 넣어주지 않았을 때보다 사용자 경험에서 훨씬 좋았다.
Project Manager
최종 프로젝트의 PM을 맡았다. 목표는 팀원 모두가 문제 정의부터 학습, 서비스 배포까지의 전 과정을 경험해보고 무사히 마리를 릴리즈하는 것이였는데 달성한 것 같다.
일정이 빠듯했기에 가능한 타이트하게 잡고 진행했지만 중간에 변수들이 꽤 있어 작업들이 점점 미뤄지고 고도화 하는 시간이 부족한 것을 보고 일정 조율을 더 잘했어야 했다는 생각이 들었다. 생각만큼 딱딱 들어맞는 경우는 거의 없었다.
피어세션에서는 매일 팀원들의 진행 상황을 체크하며 서로 연계된 작업의 일정을 맞추는데 집중했고다. 또한 의견 차이가 있을 경우 모두가 공유하고 타당한 근거를 바탕으로 합의점을 찾는데 노력을 기울였다. 다양한 의견들이 앙상블되면 더 완성된 프로젝트가 된다는 사실을 깨달았다.
😎 배움과 아쉬움 😎
Reference가 적은 프로젝트
이전의 대회처럼 이전 기수의 진행 내용이나 관련 task 자료가 많았던 경우와는 달리 이번 프로젝트의 내용은 참고할 만한 자료가 많이 없었다. 프로젝트에 활용한 PEFT, QLoRA, Polyglot과 같은 키워드들이 등장 한지 얼마 되지 않았고 하나의 GPU로 경량화 학습을 해야 했기 때문이다.
이에 더해서 챗봇 서비스 상황에 맞게 fine-tuning한 사례는 더욱 찾기 힘들었다. 참고할 게 많이 없는 프로젝트에서 활용하기 위한 자료를 찾고 삽질하며 적용하는 과정이 정말 시간이 오래 걸리고 고려 해야할 게 많다는 생각을 했다. 동시에 탐험가로서의 재미도 느껴 앞으로도 남들이 아직 많이 안해본 형태의 프로젝트들을 더 해보고 싶다는 느낌 역시 받았다.
LLMOps
다른 팀들의 프로젝트 중 일부는 모델 유저의 피드백이나 쌓인 데이터를 활용해서 재학습하는 파이프라인을 구성한 경우가 보였다. 우리의 경우 데이터를 생성하고 학습, 서비스 연동에 힘을 쏟느라 구현하지 못했지만 만약 한다면 up/down vote를 추가해서 사용자로부터 좋은 답변이라고 평가받은 데이터들을 일정 주기로 모아서 약간의 재학습을 시키는 자동화 파이프라인을 구축하면 좋겠다고 생각했다. 유저 피드백을 모델 학습에 재활용하는 과정은 이후의 커리어에서도 꼭 경험해볼 것 같다.
다른 방식의 학습
12.8B 크기의 모델을 fine-tuning하는 방식이 QLoRA 뿐만 아니라 다른 방식도 도전해보지 못한 것은 약간 아쉽다. RLHF나 evolve-dataset을 활용한 학습 방식도 자원적으로 허락이 된다면 시도해보고 싶었다. 단순한 fine-tuning 보다 더 robust한 모델을 만들 수 있는 방식이기 때문이다. 현재 ver1의 Mary는 공감과 맥락파악은 어느 정도 잘하나 질문을 항상 하진 않기 때문에 이런 부분들을 보완해서 추가적인 학습이 필요해 보인다.
⛵ 앞으로의 지향점 ⛵
더 나은 마리
Meta의 llama2가 공개되고 더 다양한 학습 방식, 데이터들이 생겨났으니 마리의 대화 방식을 더 풍성하게 만들 한국어 모델을 채택해서 재학습을 하고자 한다. 양질의 더 많은 데이터를 확보한 후 실험을 통해 consistency를 잡고 우리의 목적에 더 맞는 대답을 하게 변경할 것이다.
또한 주변사람들의 사용 후 피드백 결과 대화 내역을 지우는 지우개 버튼이 작아서 안보인 다거나 사용자 데이터 활용에 대한 확실한 privacy 정책을 세우고 재학습에 활용하는 기능을 추가하고자 한다.
웹엔드와 CS 관련된 공부
프로젝트를 하다보니 만든 모델을 서비스화하는 부분에서 아는 부분이 많이 없다는 느낌을 계속 받았다. 팀원 중 한 명이 전담해주어 부담은 없었지만 FastAPI, React, DB가 어떻게 통신하고 화면을 띄워줄 수 있는지에 대한 이해가 부족했다. 일을 하다보면 완전 연구직이 아닌 이상 웹엔드와 CS관련된 부분을 계속 마주치고 어찌 보면 모델 개발보다 데이터 작업과 함께 모델과 서비스를 연결하는 부분과 Ops에서 더 많은 일을 하게 될지도 모른다는 생각이 들었다. AI 못지않게 이 부분에 대한 추가적인 공부가 절실하고 당장 내일부터 시작해야겠다.
계속 강조해도 부족하지 않은 문제 정의
시작부터 끝까지 모든 마스터님들이 강조한 문제 정의가 이번 프로젝트에선 그래도 나름 잘 되었다고 생각했다. 초반 부에 정의한 문제는 ‘우리가 원하는 챗봇의 대답이 어떤 형식을 갖추면 좋을지’에 대한 내용이 주라면 후반부에는 ‘대화란 무엇인지 나름대로 정의하고 사용자와 대화가 가능한 챗봇을 만들자’로 수정되었다. 결국 두 정의가 합쳐진 형태로 발전했지만 일전의 대회들에 비해 우리가 하고자 하는 바가 명확했고 길을 잃을 때면 그 정의를 바탕으로 다시 생각해보기도 했다. 일을 하거나 프로젝트를 할 때 문제 정의를 명확히 하고 모든 것들이 이루어져야 함을 다시 한 번 깨달았고 앞으로의 삶에서 잊지 않고 제일 먼저 수행할 작업으로 각인될 수 있었다.






감사합니다. 이런 정보를 나눠주셔서 좋아요.