개요
GPT-4, BingAI, Bard와 같은 거대 언어모델부터 웹사이트에 있는 간단한 QA챗봇까지 기존의 챗봇들은 보통 정보성 챗봇들이 많다.
질문에 적절한 정보를 내주는 챗봇들은 사용자와의 대화에 초점이 맞춰져있기 보단 정확한 정보를 주거나 질의를 정확히 이해해서 원하는 내용을 보여주는 데에 초점이 맞춰져있다. 요즘은 GPT4가 너무 잘해주고 있다..!
그러나 우리 조가 원하는 것은 그보단 대화가 잘 통하고 말을 잘 들어주는 찐 F 성향의 챗봇이다. 정보만 얻어내는 삭막한 챗봇이 아닌 진짜 내 이야기를 들어주고 물어봐주고 공감해주는 챗봇을 만들길 원한다!
지금까지 정의한 우리의 챗봇
- 사용자와 대화를 통해 공감하고 위로해주는 공감형 챗봇
- 대화의 맥락을 이해한 질문을 계속하며 이어나가게 하는 챗봇
방향
처음엔 ChatGPT API를 활용한 방법도 생각했지만 fine-tuning이 쉽지 않아 포기했다. 물론 프롬프트를 활용한 In-context tuning 방법도 있겠지만 원하는 모델을 직접 tuning 하는 것이 아니라 흥미가 떨어졌다.
그러다 최근 LoRA(Low Rank Adapter)와 8-bit 이하의 양자화를 이용한 parameter efficient fine-tuning을 통해 12.8B 정도의 LLM을 단일 GPU(우리의 경우, Tesla V100 32G)로 학습시킬 수 있는 방법이 등장했다.
기존엔 수많은 병렬 GPU와 대용량 분산 인프라를 갖춘 기업만 거대모델 학습이 가능했다면 이젠 개인도 방구석에서 LLM을 간접적으로나마 튜닝해볼 수 있게 된 것이다! (thanks to Meta...)
물론 GPT3 기반의 거대모델의 비하면 성능이나 inference 측면에서 아직은 많이 부족하지만 아무렴 어떤가! 오픈소스의 발전은 한계가 없다!
따라서 우리가 처음부터 모델을 구축하고 데이터를 만들어 pre-training 시키기엔 한계가 명확해서 어느정도의 성능을 보이는 sLLM(작은 거대언어모델, 모순이긴 하다)을 기반으로 우리가 원하는 형태로 답변을 할 수 있게 Input-Output을 주고 fine-tuning 해보고자 한다.
Backbone model
사실 사용할만한 공개되어있는 한국어 기반 챗봇은 많지 않다.
ElutherAI가 공개한 Polyglot-ko 모델은 상업적으로 이용가능하고 이 모델을 기반으로 Koalpaca, KULLM과 같은 모델들이 공개되었다.
sLLM을 fine-tuning하는 것은 우리가 원하는 형태의 Input-Output을 학습시켜 원하는 결과를 생성해내도록 유도하는 것이지 모델의 성능을 올려주는 작업이 아니라고 배웠다.
즉, backbone model의 원래 성능이 처음부터 좋지 않다면 fine-tuning을 아무리 열심히 해도 소용이 없단 뜻이다. 우리의 task인 '공감형 대화'의 형태에 더 알맞는 생성을 해내는 모델을 찾아서 backbone model로 학습을 진행하게 될 것이다.
대화의 맥락 파악
모델 학습 이전에 중요한 것이 있다.
"어떻게 사용자와의 대화 속 맥락을 모델에게 줄 것인가"
이걸 어떻게 다룰 것인지에 대해 많은 고민들이 있었다.
단순히 이전 대화를 전부 input으로 붙이거나 요약 모델을 한 번 통과시키고 중요한 부분을 뽑아서 함께 학습시킨다거나 하는 생각들을 했다.
구현이 쉽진 않겠지만(모델 코드 뿐만 아니라 벡엔드, inference 속도, 단일 GPU 서빙 등 신경써야 할 것들이 많다..ㅜ) 최대한 가능한 도전들을 해보려고 한다.
그 이전에 기존의 대화형 챗봇들이 어떤 방식으로 대화를 기억하고 반영했는지 찾아봤는데 마침 Naver Deview 2023에서 "Remember Me: 맞춤 케어를 위한 기억하기 챗봇"이라는 세션을 진행했다는 사실을 알게 되었다. 이후부턴 당시 세션을 보고 우리에게 필요한 내용들을 정리해보았다.
1. 클로바 케어콜
클로바 케어콜은 돌봄이 필요한 대상자에게 AI가 주기적으로 전화를 걸어 안부를 묻고 이상 징후를 모니터링하는 AI 콜 서비스이다.
어르신 한분 한분의 상태와 대화를 기억해서 자연스러운 대화를 통해 마음을 위로하는 따뜻한 말벗이 되어준다.
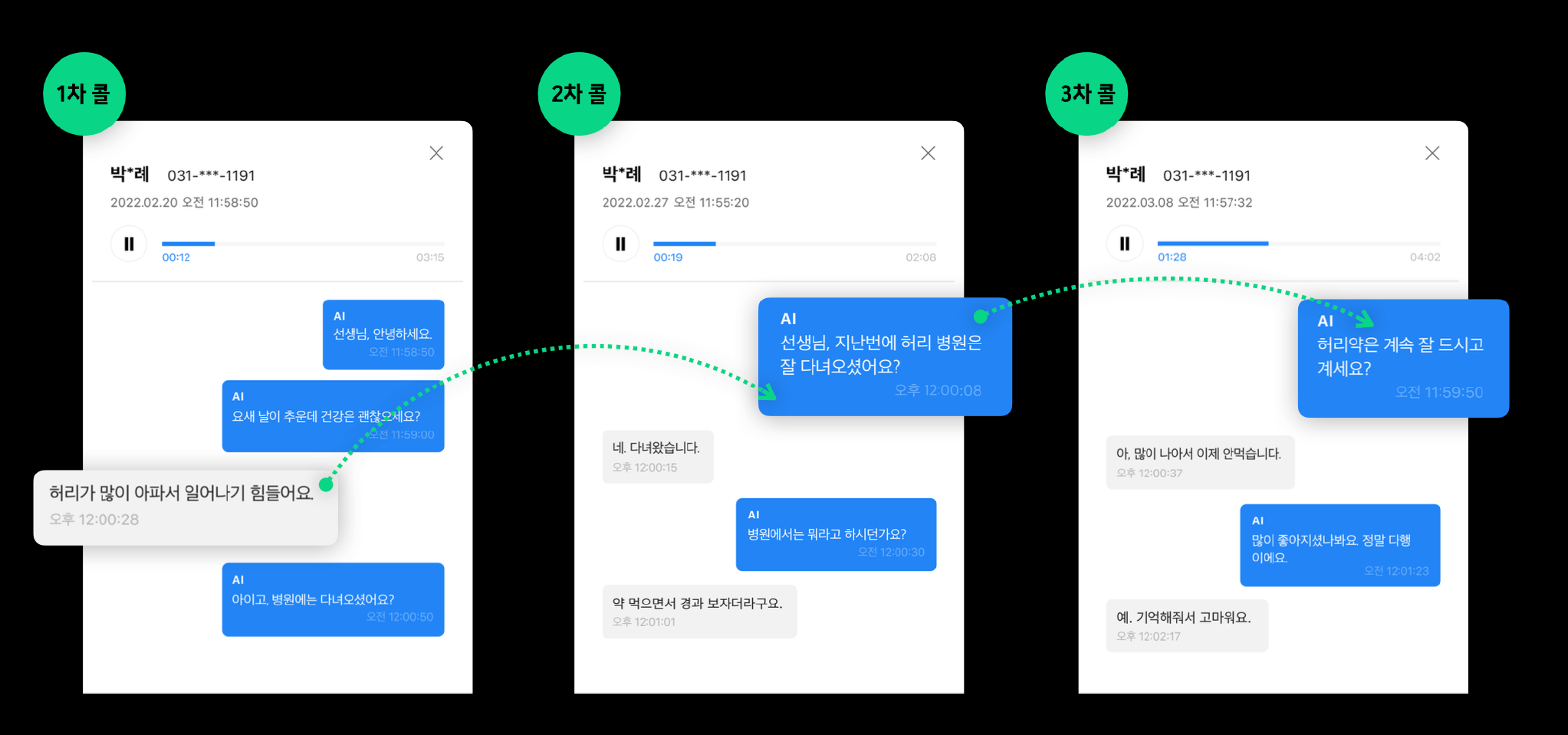
딱딱하고 사무적인 말투로 로봇과 대화하는 느낌의 정보성 챗봇과 다르게 클로바 케어콜은 사진처럼 사용자의 이전 대화를 기억해서 더 따뜻하고 배려심있는 질문과 공감을 해주는 것이 특징이다.
세심한 공감 대화, 관심 표현으로 친밀감을 높이는 관계를 형성하여 사람을 닮은 대화 시스템을 구축하는 것이 대화에서 기억의 중요성이라고 한다.
 |  |
|---|
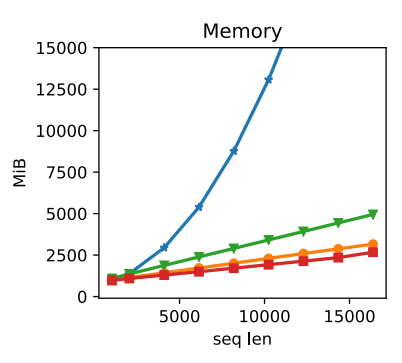
하지만 기억 기반의 대화는 난관이 많다고 한다. LLM은 최대 입력 토큰길이에 제한이 있기 때문이다.
self-attention 기반의 transformer 모델은 sequence 길이의 제곱에 비례해서 메모리 사용량이 급증하게 된다. 따라서 연산 효율성과 inference 비용을 고려하여 max_sequence 길이를 제한하게 된다. 때문에 최근 대화만을 입력으로 받아서 생성할 수 밖에 없게 된다.
Clova 팀은 이를 해결하기 위해 메모리 효율성을 높여서 이전 대화를 전부 다 입력을 넣어봤지만 효과가 없었다고 한다. 이전 대화에서 어느 부분을 사용해야 할지를 모르고 이런 대화 데이터로 학습된 적이 없었기 때문이라고 한다. 또한 평균적으로 15턴 길이인 대화 데이터를 확보하기 힘들다는 점도 한 몫 한다고 한다.
따라서 대화 내용을 기억하는 방법으로 자연어로 된 텍스트를 사용하기로 했다고 한다.
대화 내용 기억하기
자유주제의 대화 내에서 발생 가능한 다양한 상황을 사전에 정의하지 않고도 커버할 수 있어야 하기 때문에 비정형 데이터를 사용하는 것이 알맞을 것이라 판단했다고 한다. 이는 최근 Hyper Scale의 생성 모델의 추론능력이 뛰어나졌기 때문에 가능한 것이라고 한다.
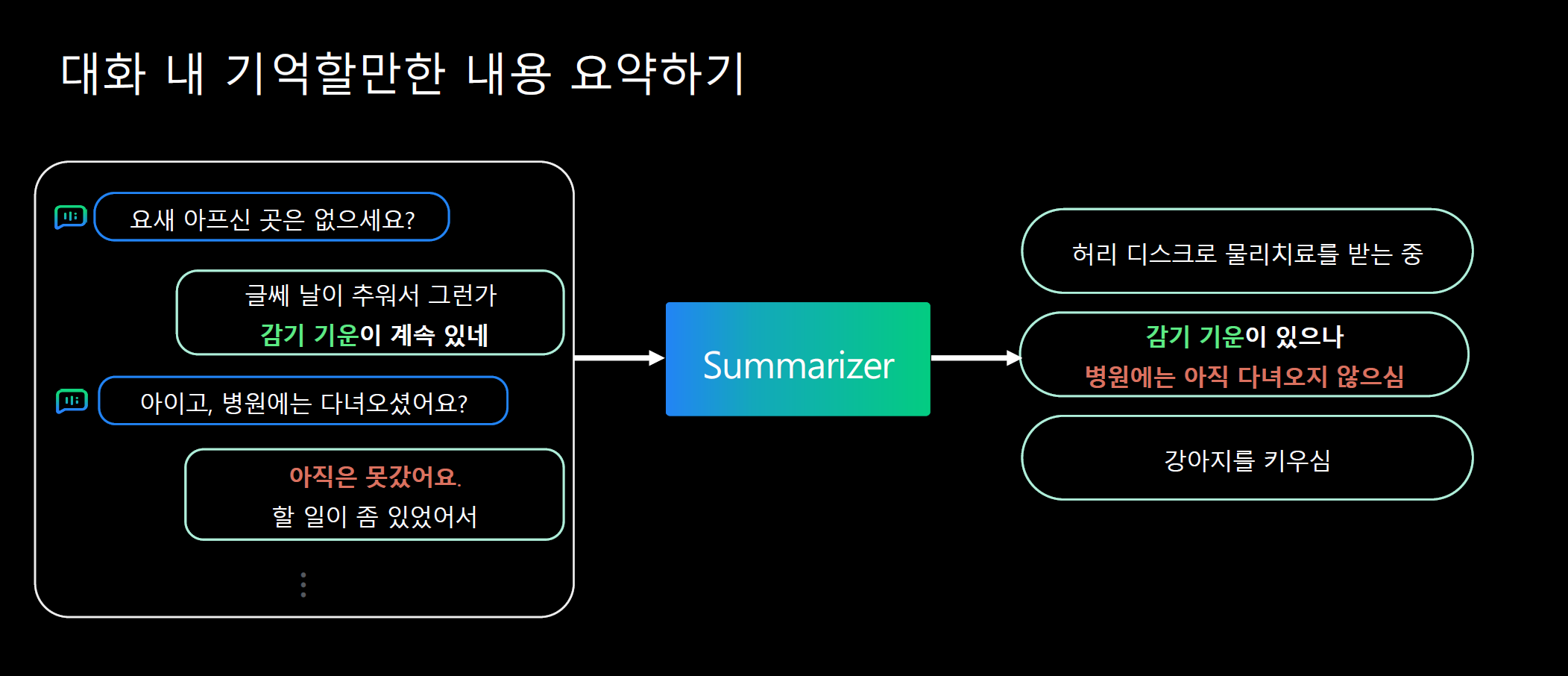
대화 내용이 주어지면 기억할만한 주요 정보들을 학습된 하이퍼클로바 요약모델을 통해 생성해내는 방법을 사용했다.
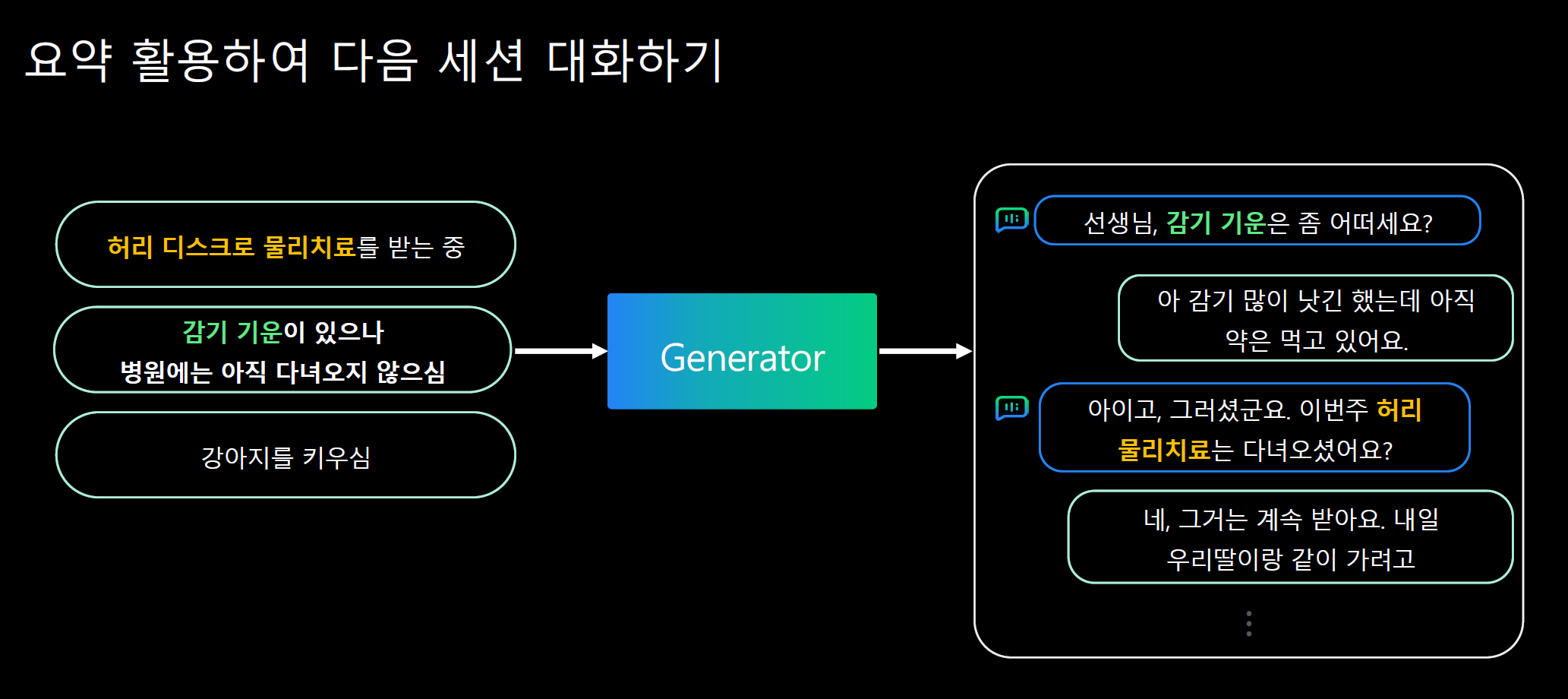
현재 문맥과 관련된 기억된 정보를 주고 이를 대화에서 자연스럽게 활용하도록 Generator를 학습시켰다고 한다. 이렇게만 말하면 어떤 방식으로 학습시킨 것인지를 잘 모르겠다.
그림에서 보인 예시는 이틀전, 사흘전과 같은 과거 사람이 대답한 데이터를 요약해놨다가 현재의 대화에서 모델이 질문을 생성하는 방식으로 활용한 듯 하다. 이는 하나의 대화 세션에서 정보를 기억했다가 대화를 이어나가는 형태를 원하는 우리의 경우와 잘 맞진 않는 것 같다.
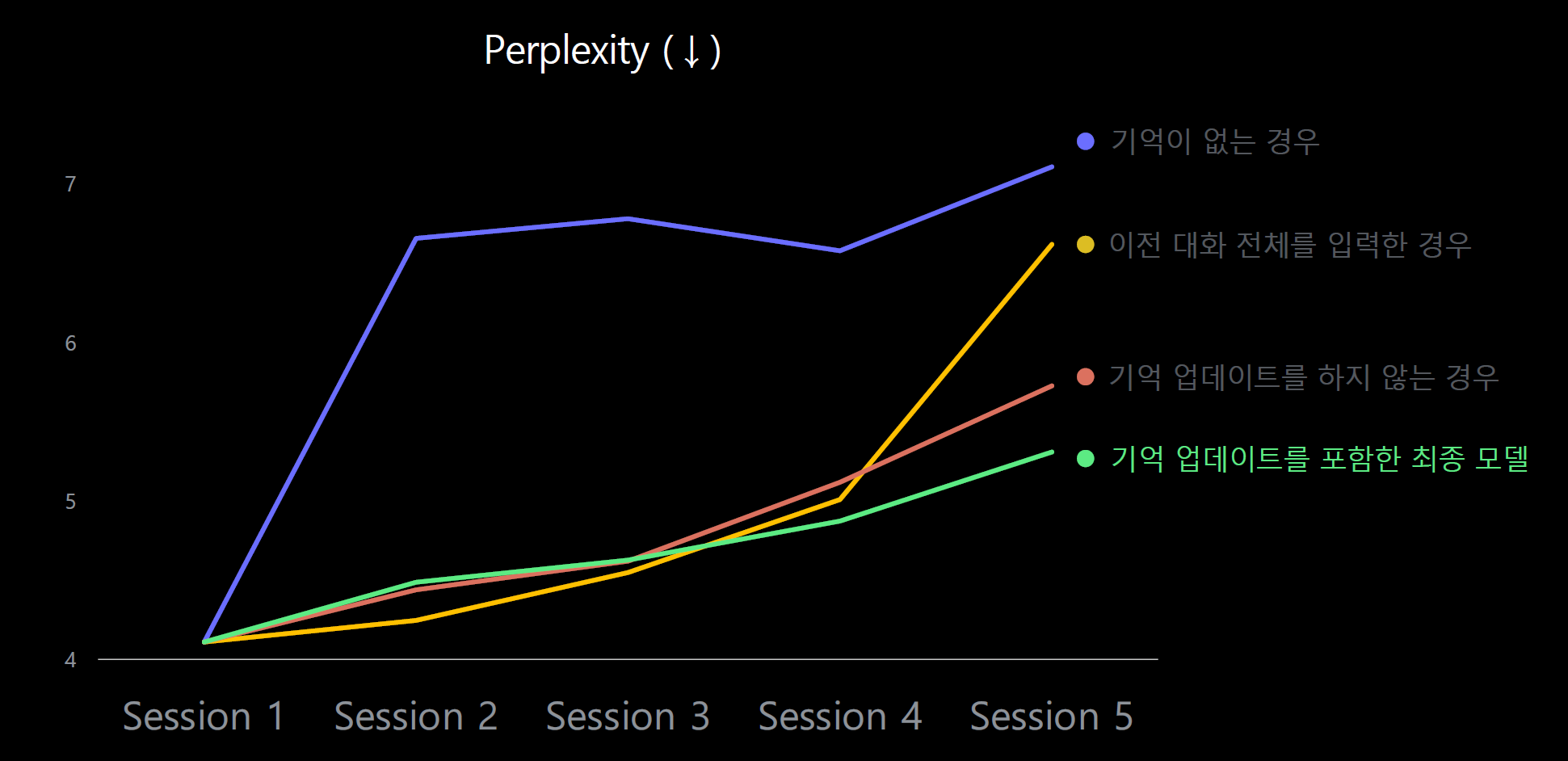
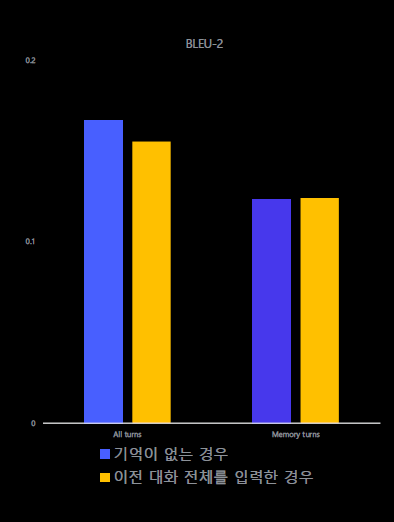
다만 다음 그래프처럼 Session이 진행됨에 따라 이전 대화 전체를 입력한 경우가 Perplexity 측면에서 기억이 없는 경우보다 낮은 경향을 보인다. 우리의 경우처럼 상대적으로 짧은 전체 대화 길이의 경우 이전 대화를 요약한 내용을 입력 프롬프트로 일부 추가하는 경우는 고려해볼만 한 것 같다.
다만 특정된 입력형태(ex. ## 질문 ~~~ ## 답변 )으로 학습된 모델이 대화가 이어짐에 따라 시시각각 변하는 프롬프트를 추가로 주고 inference를 수행할 때 제대로된 모델의 성능과 결과물이 나올지는 아직 의문이다.
위의 의문을 해결하기 위한 실험을 진행해봐야겠다. 가장 좋은 방향은 대화를 주고받는 스크립트를 하나의 input으로 받는 데이터를 새로 구축하여 학습시키고 각 대화 턴마다 이전 대화들의 요약내용을 추가해서 학습시키는 것 같다.
generation 기반 요약 모델의 경우 실제 서비스 시 inference 속도에 악영향을 끼치면 안되므로 성능이 무조건 좋은 모델보단 가볍고 적당한 성능의 모델 (ex. KoGPT-2, KoBART)을 사용해야 할 것 같다. 물론 대화 내에서 맥락 상 중요하다고 여겨질 부분을 잘 캐치해서 요약할 수 있는 능력을 갖춰야하겠지만 말이다.
2. Koalpaca
Koalpaca 데모버전의 설명에서 '최대 512 토큰의 응답을 생성하며, 이전 맥락은 (신규 생성 답변을 포함해) 최대 1024 토큰을 기억합니다.' 라고 되어있던 문구를 본 것 같은데 소스코드를 뜯어보며 어떻게 한건지 살펴봤다.
Koalpaca gradio app code에서 Inference가 어떻게 이루어지는지 보면 알 수 있다. 특별한 기법을 사용한 것은 아니고 transformers 패키지의 pipeline과 gradio의 session state 기능을 활용해서 이전 대화들을 state에 계속 쌓아서 다음 대화의 앞에 그대로 붙이는 단순한 형태였다. 가장 쉬운 방법이라고 볼 수 있겠다.
- transformers의 pipeline 함수에 모델을 넣어준다.
import gradio as gr
import torch
from transformers import pipeline, AutoModelForCausalLM
MODEL = "beomi/KoAlpaca-Polyglot-12.8B"
model = AutoModelForCausalLM.from_pretrained(
MODEL,
device_map="auto",
load_in_8bit=True,
revision="8bit",
# max_memory=f'{int(torch.cuda.mem_get_info()[0]/1024**3)-2}GB'
)
pipe = pipeline(
"text-generation",
model=model,
tokenizer=MODEL,
# device=2,
)- 들어온 질문에 대답하는 answer 함수를 만든다.
def answer(state, state_chatbot, text):
messages = state + [{"role": "질문", "content": text}] # 첫 부분의 모델에 대한 설명과 이전 대화들이 저장되어 있는 state에 현재 들어온 질문을 messages에 더해준다.
conversation_history = "\n".join(
[f"### {msg['role']}:\n{msg['content']}" for msg in messages] # conversation_history를 역할 : 메세지 형태의 리스트로 만든다.
)
ans = pipe(
conversation_history + "\n\n### 답변:",
do_sample=True,
max_new_tokens=512,
temperature=0.7,
top_p=0.9,
return_full_text=False,
eos_token_id=2,
) # pipe 객체에 통과시켜 그 답변을 max_nex_tokens 만큼 생성한다.
msg = ans[0]["generated_text"] # 응답만 가져오는 과정
if "###" in msg:
msg = msg.split("###")[0] # 현재 ### 질문, ### 응답 형태로 이루어져 있어 가끔 ###이 붙어있는 경우가 있는데 이걸 방지하는 역할인 것 같다.
new_state = [{"role": "이전 질문", "content": text}, {"role": "이전 답변", "content": msg}] # 새로운 state를 추가해준다. 이때 다음 질문 기준으론 현재의 질문-대답이 이전 질문과 대답이므로 role을 저렇게 지정해줘서 과거의 대화임을 명시해준다.
state = state + new_state # state(답변 과거기록들)을 업데이트 하고
state_chatbot = state_chatbot + [(text, msg)] # 챗봇 자체의 질문-답변 리스트도 업데이트 한다.
print(state)
print(state_chatbot)
return state, state_chatbot, state_chatbot - Gradio UI로 간단한 demo 버전을 보여준다.
with gr.Blocks(css="#chatbot .overflow-y-auto{height:750px}") as demo:
state = gr.State(
[
{
"role": "맥락",
"content": "KoAlpaca(코알파카)는 EleutherAI에서 개발한 Polyglot-ko 라는 한국어 모델을 기반으로, 자연어 처리 연구자 Beomi가 개발한 모델입니다.",
},
{
"role": "맥락",
"content": "ChatKoAlpaca(챗코알파카)는 KoAlpaca를 채팅형으로 만든 것입니다.",
},
{"role": "명령어", "content": "친절한 AI 챗봇인 ChatKoAlpaca 로서 답변을 합니다."},
{
"role": "명령어",
"content": "인사에는 짧고 간단한 친절한 인사로 답하고, 아래 대화에 간단하고 짧게 답해주세요.",
},
]
)
state_chatbot = gr.State([])
with gr.Row():
gr.HTML(
"""<div style="text-align: center; max-width: 500px; margin: 0 auto;">
<div>
<h1>ChatKoAlpaca 12.8B (v1.1b-chat-8bit)</h1>
</div>
<div>
Demo runs on RTX 3090 (24GB) with 8bit quantized
</div>
</div>"""
)
with gr.Row():
chatbot = gr.Chatbot(elem_id="chatbot")
with gr.Row():
txt = gr.Textbox(show_label=False, placeholder="Send a message...").style(
container=False
)
txt.submit(answer, [state, state_chatbot, txt], [state, state_chatbot, chatbot]) # answer 함수들에 인자를 넣어줘서 generation 하는 과정이다. 왼쪽은 입력이고, 오른쪽은 출력이다.
txt.submit(lambda: "", None, txt)
demo.launch(debug=True, server_name="0.0.0.0")KULLM adapter model에 적용해보기
100 step 정도 짧게 학습시키고 lora adapter로 저장해서 불러온 모델에다가 적용시키는 코드로 바꿔서 inference를 해봤다. 아직 학습이 불안정해서 대답을 제대로 하진 못하지만 어제 지갑샀다고 하고 한번 건너 내가 어제 뭐샀냐고 물어보니 지갑을 샀다고 기억하고 있는 모습을 보여준다.
app.pyimport torch
from typing import Optional, Tuple
import gradio as gr
from threading import Lock
from transformers import pipeline, AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import PeftModel, PeftConfig
def load_model():
"""Load the local Hugging Face model."""
peft_model_id = "ohilikeit/kullm-polyglot-12.8b-v2_100steps"
config = PeftConfig.from_pretrained(peft_model_id)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(config.base_model_name_or_path,
quantization_config=bnb_config, device_map={"":0})
model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model.eval()
return model, tokenizer
model, tokenizer = load_model()
pipe = pipeline(
'text-generation',
model = model,
tokenizer = tokenizer,
)
def answer(state, state_chatbot, text):
messages = state + [{'role' : '명령어', 'content' : text}]
conversation_history = '\n'.join(
[f"### {msg['role']}:\n{msg['content']}" for msg in messages]
)
print(conversation_history)
ans = pipe(
conversation_history + '\n### 응답:',
do_sample = True,
max_new_tokens = 50,
temperature = 0.7,
top_p = 0.9,
return_full_text = False,
eos_token_id = 2,
)
msg = ans[0]['generated_text']
if '###' in msg:
msg = msg.split('###')[0]
new_state = [{'role' : '이전 명령어', 'content' : text},
{'role' : '이전 응답', 'content' : msg}]
state = state + new_state
state_chatbot = state_chatbot + [[text, msg]]
print('state : ', state)
print('state_chatbot : ', state_chatbot)
return state, state_chatbot, state_chatbot
with gr.Blocks(css="#chatbot .overflow-y-auto{height:750px}") as demo:
state = gr.State(
[
{
'role' : '맥락',
'content' : '공감을 잘하는 챗봇 "내마리" 입니다. 사람들의 질문에 친절하게 답변해줍니다.'
},
{
'role' : '맥락',
'content' : '제 목표는 유용하고 친절하며 재미있는 챗봇이 되는 것입니다. 저에게 조언을 구하거나 답변을 요청하거나 무슨 일이든 이야기할 수 있습니다.'
},
{
"role": "명령",
"content": "인사에는 짧고 간단한 친절한 인사로 답하고, 아래 대화에 간단하고 짧게 답해주세요.",
},
]
)
state_chatbot = gr.State([])
with gr.Row():
gr.Markdown("<h3><center>공감능력 개쩌는 부덕이와의 대화</center></h3>")
chatbot = gr.Chatbot()
with gr.Row():
txt = gr.Textbox(
label="어떤 것을 묻고 싶나요?",
placeholder="찐 F인 부덕이에게 어떤 말이든 자유롭게 해주세요!",
lines=1,
).style(container = False)
gr.HTML("Demo application of a Polyglot-ko, Huggingface")
gr.HTML(
"<center>Powered by <a href='https://github.com/hwchase17/langchain'>LangChain 🦜️🔗</a></center>"
)
txt.submit(answer, [state, state_chatbot, txt], [state, state_chatbot, chatbot])
txt.submit(lambda: "", None, txt)
demo.launch(debug=True, share=True)
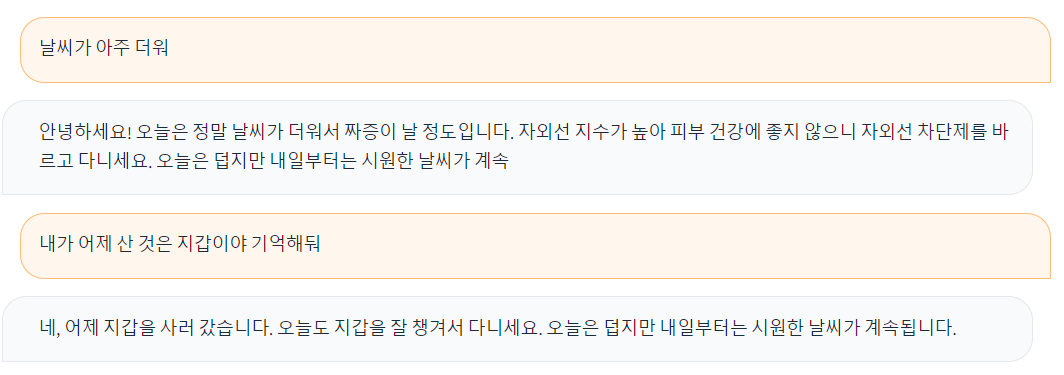
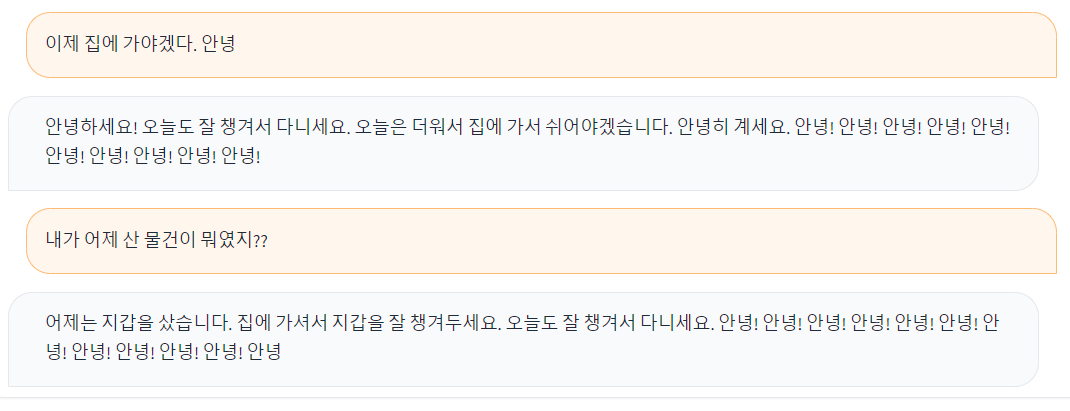
중간에 conversation_history를 찍어보면 이런식으로 마지막 질문인 '내가 어제 산 물건이 뭐였지??' 에 대한 답변을 생성하기 위해 초반 맥락과 명령 뿐만 아니라 이전 대화기록을 이전 명령어-이전 응답 페어로 모두 갖고 있는 것을 알 수 있다. 참고로 input의 길이가 길어진다고 해도 generation 속도는 차이가 없었다.

해결해야할 문제들
지금 보이는 문제점들은 다음과 같다.
-
기본적인 모델의 generation 성능이 우리가 원하는 형태의 적절한 답변을 해줄지 의문이다.
=> 우리의 데이터로 fine-tuning 시켜보고 다시 고민해봐야겠다. -
지금처럼 모든 질문-답변을 그대로 붙이는 경우 max_token_size인 512를 넘기게 될 경우 input에서 이미 512를 다 채워서 답변이 생성되지 않고 오류가 떴다.
=> 질문-답변 쌍이 여러개 있는 대화에서 맥락 상 중요한 부분만을 요약해주는 간단한 요약모델을 학습시키고 실제 질문에 대한 답변이 이루어질때마다 요약해서 저장하는 형태로 가야할 것 같다. 먼저 생성을 해서 답변을 내놓고 그 다음에 요약해서 저장하는 과정을 넣으면 되지 않을까 싶다. langchain의 ConversationChain 함수 기능을 활용해서 메모리 효율적으로 활용가능한 방법이 있다면 고려해볼 것 같다.
- 현재는 max_token을 50으로 해둬서 생성하는데에 15초 정도 걸리지만 더 길어져야 하고 생성 속도는 더 짧아져야 한다. 또한 답변이 잘려서 나오는 경우도 후처리로 방지해야 한다.
=> 현재는 adapter weight를 로드해서 사용하고 있으나 inference 결과가 더 좋게 나오는 방향으로 학습한 모델을 저장하는 방안을 찾아봐야 한다. 원본 16bit에서 양자화되거나 weight가 압축될수록 inference 성능이 안좋고 속도도 느려지기 때문이다.
마무리
대화 맥락을 기억하는 챗봇이 생각보다 까다로운 것 같다. 학습시킬 모델에 따라 데이터의 형태가 달라질 것이기에 빠르게 활용할 방법이나 실험을 확정지어야 하는데 시간이 부족하다 ㅠㅠ
우선적으로 GPT4로 생성한 Input-Output 기반의 synthetic data를 fine-tuning 시켜보고 해당 모델이 어느 정도의 inference 성능을 보이는지 확인하고 결정해봐야겠다.
Care Call 에서 요약 모델과 응답 생성 모델 학습에 활용한 데이터는 모두 적절한 Seed 데이터를 손으로 생성하고 HyperClova를 LoRA fine-tuning해서 자동생성한 synthetic data라고 한다. 사실 GPT4로 전부 생성하고 있는 동안 약간의 현타가 왔었는데 네이버에서도 이런 방법을 사용해서 자원효율적으로 진행한다는 말을 듣고 마음이 한 켠 놓였다..!!
