넘파이와 판다스 라이브러리
넘파이의 배열
넘파이(NumPy)는 Numurical Python의 약자로, 숫자 데이터를 포함한 벡터와 행렬 연산에 유용합니다. 넘파이를 익혀 두면 데이터 분석 특화 라이브러리인 판다스와 맷플롯립까지 제대로 활용할 수 있습니다.
구글 Colab이나 아나콘다 환경에서는 이미 넘파이가 설치되어 있지만, 그렇지 않은 경우 pip 명령어로 넘파이 라이브러리를 설치하여 사용합니다.
pip install numpy;배열은 넘파이의 핵심 객체로, 파이썬의 리스트와 비슷하게 데이터를 모아 저장하는 자료구조 입니다.
넘파이 배열의 차원
-
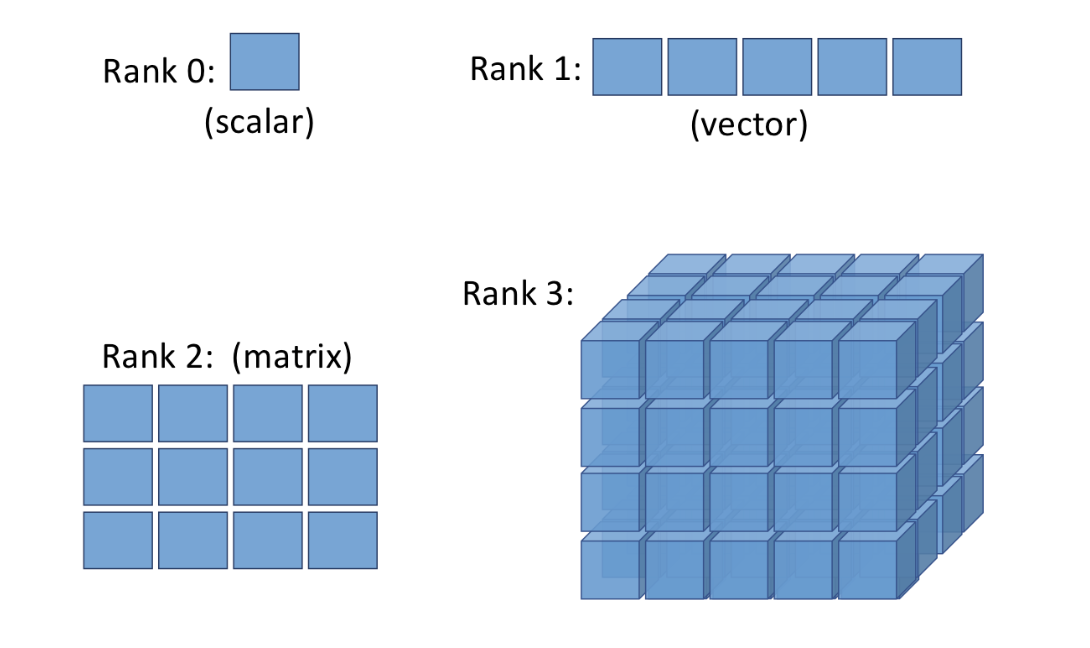
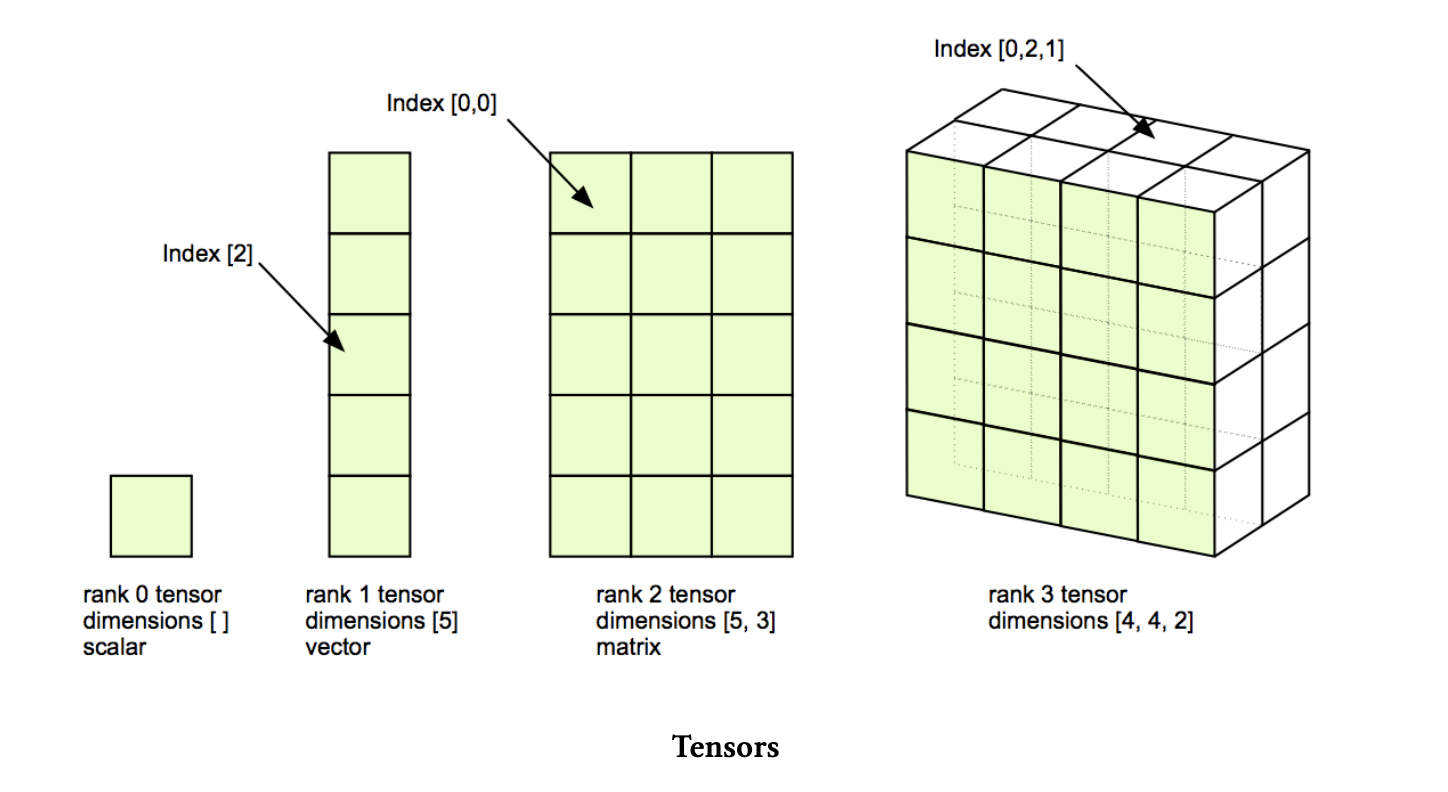
차원(Dimension) : 관측하고자 하는 데이터의 속성의 수 또는 측정 항목의 수
-
스칼라(Scalar) : 0차원 배열, 배열에서 값을 표현하는 가장 기본 단위로, 하나의 실수를 담을 수 있음
-
벡터(Vector) : 1차원 배열, 스칼라(값) 여러 개를 나열한 튜플
-
행렬(Matrix) : 2차원 배열, 1차원 배열을 여러 개 묶은 배열
-
텐서(Tensor) : 벡터의 집합, 3차원 이상의 배열, 행렬보다 넓은 개념(1차원배열, 2차원 배열 포함)
-
랭크(Rank) : 차원의 수
-
모양(Shape) : 배열의 차원과 크기
ex) 행이 3개, 열이 4개인 2차원 배열 -> 랭크 = 2, 모양 = (3,4)
ndarray
넘파이의 다차원 배열 객체를 ndarray라고 합니다.
특징은 다음과 같습니다.
- 자료형이 모두 같은 데이터를 담은 다차원 배열
- 정수 또는 실수(부동 소수점 수)를 저장
- 배열 데이터에도 순서가 있으므로 인덱싱과 슬라이싱이 가능
넘파이 배열의 인덱싱과 축
배열을 정수나 다른 배열, 논리값, 음이 아닌 정수의 튜플(Tuple)로 인덱싱할 수 있습니다.
배열의 요소에 접근할 때는 대괄호([])를 사용하며, 인덱스는 0부터 시작합니다.
배열이 2차원이라면 대괄호 안에서 행 다음에 콤마, 를 찍고 열의 인덱스를 붙입니다.
3차원이라면, 면, 행, 열 순으로 인덱스를 붙입니다.
ex) 2행 3열의 2차원 배열에서 두 번째 행 첫 번째 열의 원소 = a[1,0]
ex) 3면 2행 3열의 3배열에서 두 번째 면 첫 번째 행 세 번째 열의 요소 = a[1,0,2]
또한, 축은 인덱스가 증가하는 방향입니다.
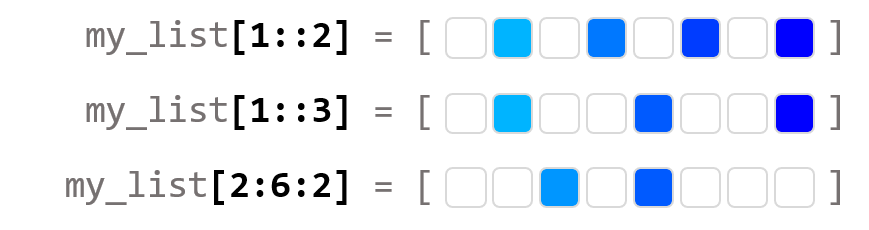
🌠⭐넘파이 배열의 슬라이싱
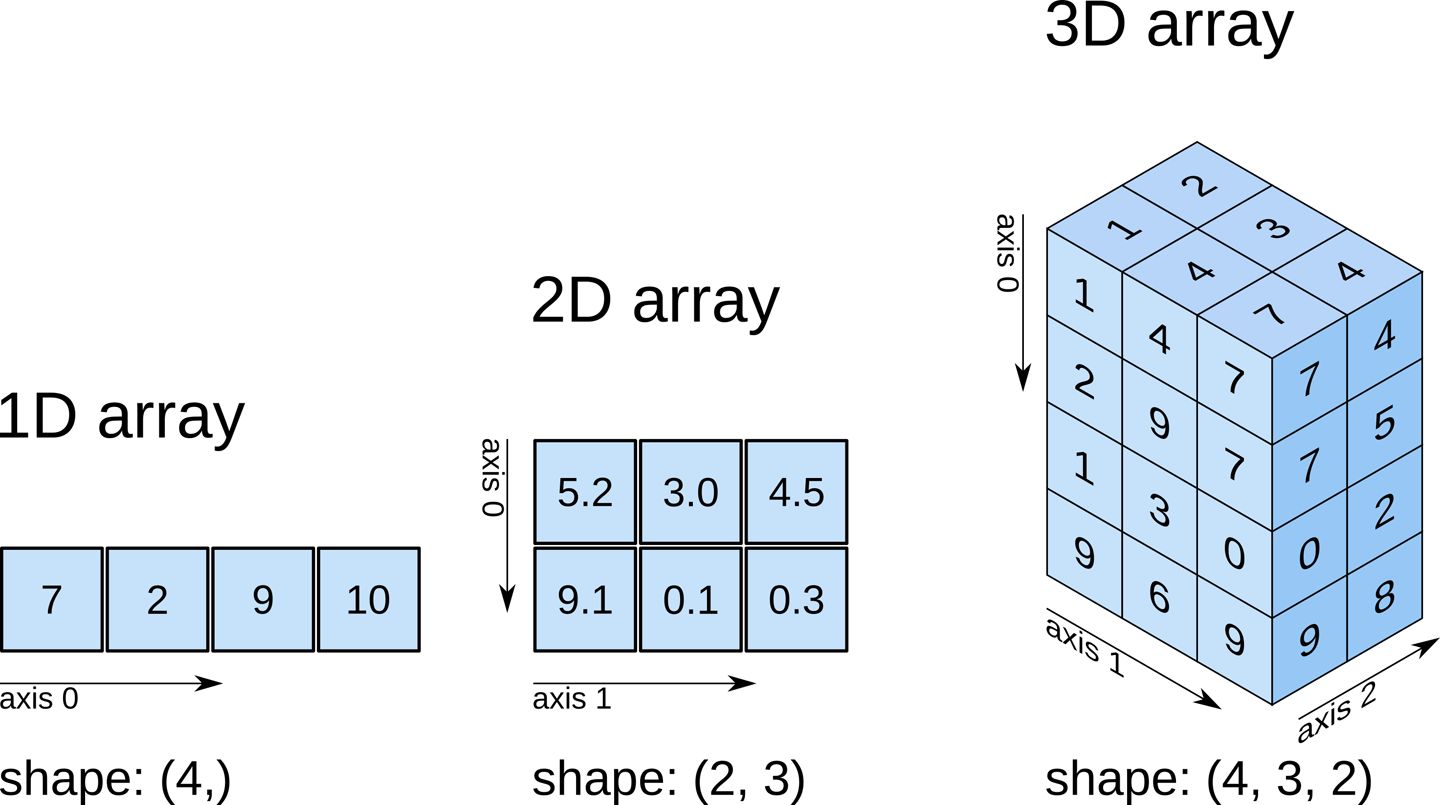
슬라이싱(Slicing) 은 배열에서 연속한 일부분을 잘라 선택하는 것으로, 선택된 배열 조각을 슬라이스 라고 합니다.
인덱스와 콜론:을 사용합니다. 배열이 2차원 이상인 경우, 행의 인덱스인지, 열의 인덱스인지 주의해야 합니다.
ex) 모양이 (3,3)인 배열 a의 슬라이싱
콜론 왼쪽에 있는 숫자부터 콜론 오른쪽에 있는 숫자보다 1 작은 숫자까지 범위에 해당하는 인덱스를 선택합니다.
콜론 왼쪽 숫자를 생략하면 0번 인덱스를 의미하고, 오른쪽에 숫자를 적지 않으면 마지막까지 선택합니다.
열이나 행, 면 전체를 선택하려면 숫자 대신 콜론을 사용합니다.
따라서 a[0,:] 은 위 그림의 (c)와 같이 나타나며, 첫번째 행의 열 전체를 슬라이싱 하게 됩니다.
마찬가지로 a[:,2]는 세번째 열의 행 전체를 슬라이싱 합니다.
더 많은 예를 보면, 다음과 같습니다.

시작 (start)/끝 (stop)/간격 (step)
판다스의 시리즈와 데이터프레임
판다스(Pandas)는 데이터프레임 자료구조를 제공하여 데이터 분석을 돕는 파이썬의 핵심 패키지입니다.
마찬가지로, 판다스 라이브러리는 구글 Colab에 이미 설치되어 있지만, 설치 명령어는 다음과 같습니다.
pip install pandas;시리즈와 데이터프레임
시리즈(Series) 는 인덱스와 값이 한 쌍을 이루는 1차원 자료구조 객체입니다.
리스트는 값만 있고, 인덱스가 0부터 자동 생성되는 반면, 시리즈는 사용자가 직접 인덱스를 정할 수 있습니다. 따라서 시리즈는 딕셔너리와 성격이 유사합니다.
pd.Series({'x':10, 'y':20})는 x, y라는 인덱스가 값 10, 20과 대응하는 시리즈 객체입니다.
이는 pd.Series([10, 20], index=['x', 'y']) 로 생성하는 것과 같습니다.
데이터프레임(Dataframe)은 판다스의 기본 구조인 자료구조 객체로, 시리즈를 여러 개 묶어 데이터프레임을 만들 수 있습니다. 따라서 형태는 2차원 배열과 유사하며, 각 시리즈는 데이터프레임의 열이 됩니다.
모든 열은 같은 길이이며, 각 열은 서로 다른 자료형이여도 됩니다.
데이터프레임은 행 인덱스, 열 이름(또는 열 인덱스), 값으로 구성됩니다.

넘파이와 판다스 비교
넘파이의 특징
다차원 배열 객체 ⭐
객체 ndarray를 사용해 다차원 배열을 생성하고 관리하는 기능이 넘 파이의 핵심
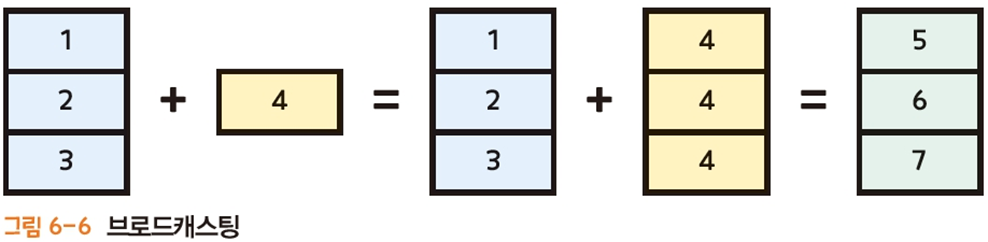
정교한 브로드캐스팅
브로드캐스팅이란, 넘파이에서 모양(Shape)이 서로 다른 배열끼리 연산하는 방식입니다.
넘파이에서 배열의 브로드캐스팅을 활용해 코드를 간결하게 작성할 수 있습니다.
C, C++, 포트란 코드를 통합
넘파이 내부의 복잡한 알고리즘이나 고성능이 필요한 부분은 C언어나 C++, 포트란(Fotran)코드로 구현되어 있습니다. 파이썬은 사용하기 간편한 대신 실행이 비교적 느리다는 단점이 있는데, 넘파이에서는 다른 언어를 함께 사용해 이러한 한계를 극복했습니다.
수학적 알고리즘 제공
넘파이에서는 선형대수의 함수, 푸리에 변환, 난수 기능 등 다양한 수학 알고리즘을 제공합니다.
이러한 알고리즘을 활용해 머닝러신 모형을 만들 수 있습니다.
판다스의 특징
대용량 데이터 처리
판다스를 활용하면 시리즈와 데이터프레임 자료구조로 대용량 데이터를 빠르게 처리해 데이터 분석 성능을 높일 수 있습니다.
시각적으로 알아보기 편리한 표 형태
데이터 구조가 표 형태이기 때문에, 사용자가 데이터를 알아보기 편리합니다.
데이터 분석 도구 제공
판다스에서 제공하는 기능 중 데이터 분석에 자주 사용하는 기능은 결측치 처리, 관계 연산, 시계열입니다.
⭐ 판다스의 데이터프레임과 넘파이의 다차원 배열은 서로 변환이 가능합니다.
넘파이 활용
넘파이의 기본 데이터 구조는 다차원 배열 ndarray로, ndarray의 요소로는 모두 같은 자료형의 데이터를 담아야 합니다.
넘파이 배열 생성
넘파이 배열 객체 ndarray를 만들기 위해 array() 함수를 사용합니다.
import numpy as np
#리스트를 생성하고 배열로 변환
list1 = [1, 2, 3, 4]
a = np.array(list1)
print('a.shape: ', a.shape)
print('a[0]: ', a[0])
# 2차원 배열 생성
b = np.array([[1,2,3],[4,5,6]])
print('b.shape: ', b.shape)
print('b[0,0]: ', b[0,0])
print('b[0]: ', b[0])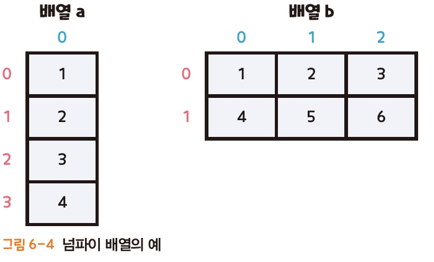
배열 생성 함수

a = np.ones(4)
print('a\n', a)
b = np.zeros((2,2))
print('b\n', b)
c = np.ones((2,3))
print('c\n', c)
d = np.full((2,3), 5)
print('d\n', d)
e = np.eye(3)
print('e\n', e)
넘파이 자료형
정수, 부호 없는 정수, 실수, 복소수, 논리값을 포함합니다 .
다만, 정수형과 실수형은 자료형 뒤에 그 자료형이 사용하는 메모리 비트 수를 붙입니다.
자료형 지정
array()함수로 배열을 생성할 때 dtype 옵션을 추가해 배열의 넘파이 자료형을 지정할 수 있습니다.
반대로, 배열 객체에 dtype 속성을 사용하면 넘파이 자료형을 확인할 수 있습니다.
자료형 변환
배열 객체에 astype() 함수를 적용하고, 인자로 넘파이 자료형을 입력하면 배열의 넘파이 자료형을 변환할 수 있습니다.
#실수형 배열 생성
a = np.array([1, 2], dtype=np.float64)
print(a.dtype)
#정수형 배열로 변환
a_i8 = a.astype(np.int8)
print(a_i8.dtype)
넘파이 배열의 속성
다차원 배열 객체 ndarray는 다음 그림과 같은 속성을 갖습니다.

ndim: ‘number of dimensions’의 약자, 배열의 차원dtype: 배열 요소의 자료형itemsize: 요소의 바이트 수size: 요소의 개수nbytes: 배열 전체의 바이트 수Shape: 배열의 모양T: 행과 열을 바꾼 교체 배열
속성 호출은 객체.속성 으로 합니다.
arr = np.array([[0, 1, 2], [3, 4, 5]])
print('type(arr):',type(arr))
print('arr.ndim:',arr.ndim)
print('arr.dtype:',arr.dtype)
print('arr.itemsize:',arr.itemsize)
print('arr.size:',arr.size)
print('arr.nbytes:',arr.nbytes)
print('arr.T:\n',arr.T)
print('arr.shape:',arr.shape)
배열의 모양
넘파이 배열의 전체 요소 개수를 유지하면서 모양을 변경할 수 있습니다.
| 제목 | 내용 |
|---|---|
| flatten() | 1차원 배열로 변경 |
| resize(i,j) | 배열의 모양을 i x j 로 변경 |
| transpose() | 열과 행 교차 |
배열의 shape 속성에 튜플을 할당해 모양을 지정합니다.
객체.shape = (행 크기, 열 크기)
#1차원 배열 생성
a = np.arange(8)
print('a\n', a)
#다차원 배열로 변경
a.shape = (2,4)
print('shape\n', a)
#1차원 배열로 변경
print('flatten\n', a.flatten( ))
#resize 함수로 모양
a.resize((4,2))
print('resize\n', a)
# 행과 열 교차 - T는 속성, transpose()는 함수
b = a.transpose()
print('b\n', b)
c = a.T
print('c\n', c) 
넘파이 배열 다루기
마스킹
= 논리값 인덱싱(Boolean indexing)
마스킹(Masking)은 조건에 맞는 값을 출력하는 기능입니다.
특히, 데이터 양이 많을 때, 조건을 검사하지 않고도 원하는 데이터를 찾을 수 있습니다.
배열로 마스킹
#코드 6-7
mask = np.array([0, 1, 1, 0], dtype=bool)
print(mask)
data = np.random.randn(4,2)
print('\ndata 출력\n',data) #랜덤 데이터 배열 data는 책과 다르게 나타남
print('\n마스킹된 데이터 출력\n',data[mask])
print('\n마스킹 역전된 데이터 출력\n',data[~mask])- True와 False 대신 1, 0을 사용해 마스크 배열 mask 생성
data[mask]는 mask 배열의 1에 해당하는 data 배열의 요소를 인덱싱data[~mask]는 mask 배열의 1에해당하지 않는 data 배열의 요소 인덱싱random.randn()-> 평균이 0이고 표준편차가 1인 정규분포를 따르는 난수 생성
조건식으로 마스킹
posit = data[data > 0] # 양수 데이터
#다중 조건
over1 = data[1][data[1]>0] # 두번째 행의 양수 데이터유니버설 함수와 브로드캐스팅
유니버설 함수는 덧셈, 뺄셈, 곱셈, 거듭제곱처럼 배열 요소끼리의 기본 연산을 수행하는 함수입니다.
넘파이 배열은 반복문을 활용하는 파이썬의 리스트 연산보다 월등히 빠르고 효율적인 연산을 지원합니다.

- 브로드캐스팅(broadcasting)이란 둘 중 작은 차원인 배열을 변형해 큰 차원의 배열에 맞춘 다음 두 배열을 요소별로 연산하는 동작입니다.
배열 복사
얕은 복사
- 등호(=)를 이용
- 배열의 데이터 자체가 새로운 배열로 복사되지 않고, 원본 데이터의 주소가 복사됩니다.
- 원본 배열을 수정하면 원본 배열을 수정하는 복사본이 함께 바뀝니다.
- 반대로 복사본을 수정해도 원본이 함께 바뀝니다.

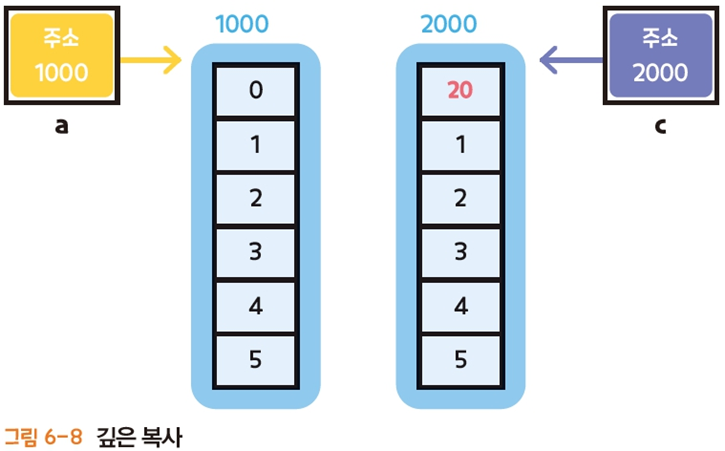
깊은 복사
copy()함수를 이용합니다.- 배열 복사본을 생성하므로 원본을 수정해도 복사본이 바뀌지 않습니다. (복사본 수정도 마찬가지)
배열 정렬
배열 정렬은 sort() 함수를 사용합니다.


3. 판다스 활용
시리즈와 데이터프레임 생성
시리즈 생성
리스트 -> 시리즈
#코드 6-12
import pandas as pd
a = pd.Series([1, 2, 3, 4])
print(a)
b = pd.Series([1, 2, 3], index=['a', 'b', 'c'])
print(b)
# 시리즈 a는 인덱스를 지정하지 않았으므로 기본 인덱스로 숫자 0, 1, 2, 3이 지정됨
# 시리즈 b는 값 1, 2, 3에 인덱스로 문자열 'a', 'b','c'를 지정함데이터프레임 생성
판다스의 DataFrame() 함수로 데이터프레임을 생성합니다.
파이썬의 리스트, 파이썬의 딕셔너리, 넘파이의 배열을 활용할 수 있습니다.
리스트를 만들어 데이터프레임의 데이터로 한 행씩 지정할 수도 있습니다.
열 이름은 따로 리스트를 만들고 지정합니다.
리스트 -> 데이터프레임 생성
list1 = list([['한빛', '남자', '20', '180'],
['한결', '남자', '21', '177'],
['한라', '여자', '20', '160']])
col_names = ['이름', '성별', '나이', '키']
pd.DataFrame(list1, columns=col_names)
딕셔너리 -> 데이터프레임
- 딕셔너리의 키 -> 열 이름 / 값 -> 열에 대한 각 행의 데이터
pd.DataFrame({키1:{인덱스0:값1, 인덱스1:값2}, 키2:{인덱스0:값3, 인덱스1:값4}})
dict1 = {'이름':{0:'한빛', 1:'한결', 2:'한라'},
'성별':{0:'남자', 1:'남자', 2:'여자'},
'나이':{0:'20', 1:'21', 2:'20'},
'키':{0:'180', 1:'177', 2:'160'}}
pd.DataFrame(dict1)넘파이의 다차원 배열 -> 데이터프레임
넘파이의 다차원 배열에는 값만 있고 열 이름이 없으므로,
열 이름 리스트를 만들고 columns 옵션을 이용해 데이터프레임의 열 이름으로 지정합니다.
import numpy as np
#배열
arr1 = np.array([['한빛','남자', '20', '180’],
['한결','남자', '21', '177'],
['한라','여자', '20', '160’]])
#열 이름 리스트
col_names = ['이름','성별','나이','키’]
#데이터프레임 생성하기
pd.DataFrame(arr1, columns=col_names)CSV 파일 -> 데이터프레임
list1 = list([['허준호','남자','30','183'],
['이가원','여자','24','162'],
['배규민','남자','23','179'],
['고고림','남자','21','182'],
['이새봄','여자','28','160'],
['이보람','여자','26','163'],
['이루리','여자','24','157'],
['오다현','여자','24','172']])
col_names = ['이름','성별','나이','키']
df = pd.DataFrame(list1, columns=col_names)
df
데이터프레임 -> CSV 파일
#디렉토리에 CSV 파일로 저장하기
df.to_csv('./file.csv', header=True, index=False, encoding='utf-8')
#CSV 파일 읽기
df2 = pd.read_csv('./file.csv', sep=',')
df2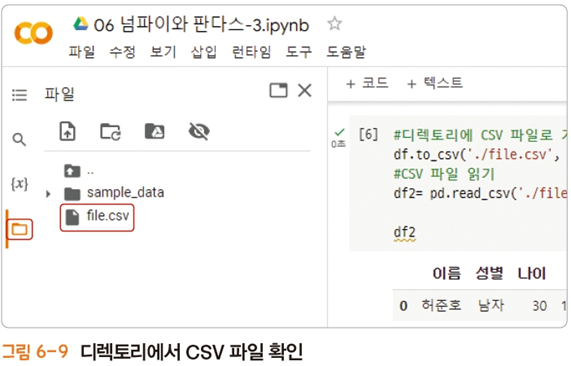
열 이름 조회
모든 열 이름 조회
df.columns
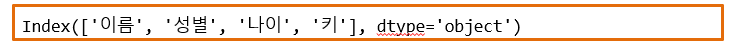
데이터프레임 값 개수와 빈도수 확인
describe() 함수로 열별 값의 개수, 빈도 수와 같은 통계를 확인합니다.
df.describe()
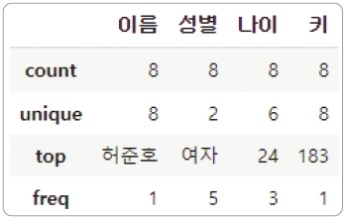
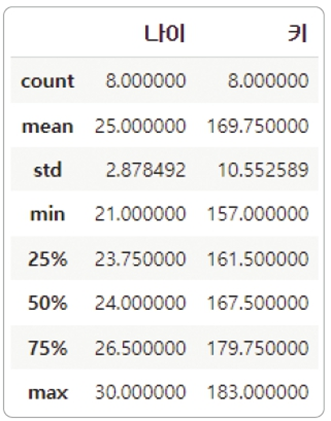
- count : 값의 개수
- unique : 유일한 값의 개수
- top : 제일 개수가 많은 값 (개수가 같은 값이 여러개 -> 먼저 나온 값이 top)
- freq : 빈도수, 즉 그 개수
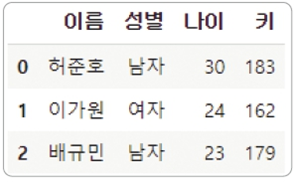
데이터 미리보기
head() 함수와 tail() 함수에 정수 n을 입력해 처음 n개행, 마지막 n개 행을 반환합니다.
함수에 숫자를 입력하지 않으면 head()는 기본 값으로 처음 다섯 행을, tail()은 마지막 다섯 행을 표시합니다.
-
df.head(3)
-
df.tail(5)
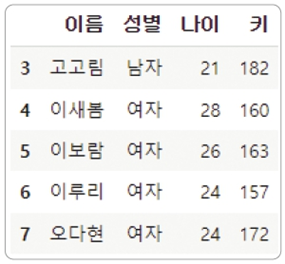
데이터프레임 데이터 분석
행 정렬
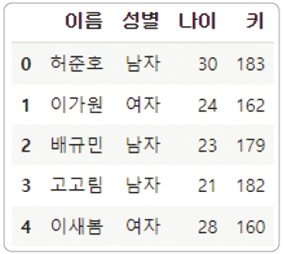
인덱스 기준 정렬
df.sort_index(axis=0).head
-> 인덱스 기준 오름차순 정렬, head()로 처음 다섯 행만 출력
특정 열 기준 정렬
sort_values 함수를 이용해 특정 열을 기준으로 정렬합니다.
# 나이 열과 키 열을 기준으로 행 정렬
df.sort_values(by=['나이', '키'], ascending=False).head위 코드는 나이가 가장 많은 사람부터 내림차순으로 정렬하되, 만약 나이가 같으면 키가 더 큰 사람부터 나타냅니다.
데이터 조회
열이나 조건식을 기준으로 조회가 간으하며, 데이터 프레임 뒤에 대괄호([])로 조건식을 붙입니다.
- 데이터프레임[조건식] # 시리즈로 출력
- 데이터프레임 [[조건식]] # 데이터프레임으로 출력
열 이름 조회
df[['이름', '키']].head( )

인덱스로 데이터 조회
iloc 함수를 사용해 인덱스로 데이터를 조회합니다.
df.iloc[행 인덱스, 열 이름]
df.iloc[1:4, 0:3]
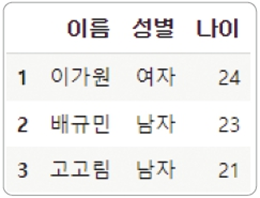
조건식을 만족하는 데이터 조회
df[df['키'] > 180].head( )
-> 오류 (키 열의 데이터 자료형이 문자열이기 때문)
복잡한 조건 조회
ex) 리스트 요소와 일치 -> isin
df[df['나이'].isin([21, 23])]
->isin()함수의 인자로 리스트 입력
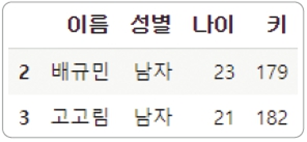
ex) 두 조건식을 동시에 만족 -> &
df[(df['성별'] == '여자') & (df['키'] > 160)]

ex) 두 조건식 중 하나 이상 만족 -> |
df[(df['나이'] >= 28) | (df['성별'] == '남자')]
ex) 특정 문자열 포함 -> str.contains()
df[df['이름'].str.contains('봄')]

데이터프레임 통계
나이와 키 데이터가 숫자형인 데이터프레임 df에 describe( ) 함수를 사용
df.describe()
데이터 갱신
행 인덱스나 열 이름으로 데이터프레임의 데이터를 조회하고 수정합니다.
df.loc[4,'키'] = df.loc[4,'키'] + 5
df.loc[[4]]
반복 연산자 사용
ex) 인덱스 1번 행부터 3번 행까지 키 데이터를 ‘모름’으로 한꺼번에 변경
df.loc[1:3,'키'] = ['모름'] * 3
df파이썬 튜토리얼 사이트
