셀레니움이란?
셀레니움(Selenium)은 사람을 대신한 웹 테스트 자동화 프레임워크입니다.
웹 브라우저를 통해 웹 페이지에 접속하고, 글미이나 버튼을 클릭하거나, 화면을 스크롤하거나, 문자를 입력하는 등 다양한 조작을 할 수 있습니다.
파이어폭스, 인터넷 익스플로러, 크롬 등 다양한 웹 브라우저를 지원하고 있고, 파이썬, 자바, 루비 등 다양한 언어로 코딩이 가능합니다.
셀레니움 기본 사용법
동적인 웹페이지와 셀레니움
웹페이지는 크게 정적인 페이지와 동적인 페이지로 나뉩니다.
정적인 페이지 (Static Web page) 는 서버에 저장된 데이터를 그대로 보여주어 시간이 지나도 모습이 변하지 않습니다. 예를 들면 홈페이지를 소개하는 인사말 등이 있습니다.
반면, 동적인 페이지 (Dynamic web page) 는 사용자가 클릭하거나 텍스트를 입력하여 페이지의 상태를 바꿀 수 있습니다. 그 뿐만 아니라, 텍스트나 이미지를 시간에 따라 바꾸어 보여줄 수 있습니다.
셀레니움 명령어
웹페이지 접속 명령어
예를 들어, 웹 브라우저의 주소창에 www.naver.com 을 입력하고 Enter를 누르는 행위는 다음과 같이 쓸 수 있습니다.
driver.get([URL])get()은 특정 웹페이지에 접속하는 함수입니다.
특정 위치의 텍스트를 찾아 수집
같은 위치의 뉴스 제목을 바뀔때마다 수집하는 동작은 다음과 같습니다.
find_element(): 버튼, 텍스트, 리스트 등의 객체를 찾는 셀레니움 함수
객체를 찾기 위해서 찾는 기준으로 객체의 속성을 지정합니다. 우리는 XML 기반의 XPath를 기준으로 합니다.
driver.find_element('xpath', '[실제 XPath 값]').text)- 첫번째 인자 : 기준 속성 'xpath'명시
- 두번째 인자 : 객체의 실제 XPath 값
- 세번째 인자 : 코드를 실행해 객체를 찾고 나면, text를 호출해 찾은 객체의 텍스트 데이터를 가져옴.
특정 위치 클릭
동적인 웹페이지에서 버튼을 클릭하는 동작을 명령하는 코드는 다음과 같습니다.
find_element() 함수를 활용해 버튼의 xpath값을 찾고, click() 함수를 호출해 객체를 클릭하는 동작을 명령합니다.
driver.find_element('xpath', '[실제 XPath 값]').click()특정 위치에 텍스트 입력
특정 입력란에 텍스트를 입력하는 동작을 명령하는 과정은 다음과 같습니다.
마찬가지로, find_element()함수로 입력란의 xpath값을 찾고, send_keys() 함수를 호출해 입력할 텍스트 문자열을 전달합니다.
driver.find_element('xpath', '[실제 XPath 값]').send_keys('[텍스트]')셀레니움 웹 크롤링
크롤링(Crawling)은 '기다' 라는 뜻의 영어 단어 'crawl'의 명사형입니다.
크롤링이란, 소프트웨어를 통해 인터넷 웹페이지를 돌아다니며 정보를 수집하는 일을 말합니다.
크롤러(Crawler)는 이러한 작업을 수행하는 소프트웨어입니다.
셀레니움 설치 및 실행
셀레니움을 실행하기 위해서는, 셀레니움이 조작할 가상의 웹 브라우저를 연동해야 합니다.
우선, 구글 Colab에서 셀레니움 및 관련 모듈을 설치합니다.
구글 Colab에서 셀레니움 설치
import sys
!sudo add-apt-repository ppa:saiarcot895/chromium-beta
!sudo apt remove chromium-browser
!sudo snap remove chromium
!sudo apt install chromium-browser
!pip3 install selenium
!apt-get update
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
sys.path.insert(0, 'usr/lib/chromium-browser/chromedriver')중간에 3행에서 Enter를 눌러 진행시킵니다.
관련 라이브러리 가져오기
import 명령어를 사용해 모듈을 이 코드에서 사용할 수 있도록 가져옵니다.
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.keys import Keys구글 Colab 환경에 맞게 셀레니움 사용 설정
service = Service(executable_path=r'/usr/lib/chromium-browser/chromedriver')
options = webdriver.ChromeOptions()
options.add_argument('--headless') # 창이 나타나지 않도록 Headless 설정
options.add_argument('--no-sandbox')
options.add_argument('--disable-dev-shm-usage')
# chrome driver
driver = webdriver.Chrome(service=service, options=options)
이대로 설정하여 셀레니움을 사용하면 가상의 브라우저인 크롬 드라이버에서 동작을 수행하기 때문에 버튼을 클릭하거나 텍스트를 입력해도 진행 상황이 눈에 보이지 않습니다.
만약 웹브라우저의 동작을 눈으로 확인하고 싶다면, 파이참(Pycham)에서 실행하되, 4행과 5행의 옵션을 삭제합니다.
마지막 행에서는 가상의 웹 브라우저에서 창을 열고, 이 객체럴 변수 driver에 할당합니다.
만약 구글 Colab에 재접속한다면 위의 설정들을 전부 다시 실행해야 합니다!
셀레니움 웹 크롤링
셀레니움으로 웹페이지에 접속
다음과 같이 입력해 해당 url의 웹페이지에 접속합니다.
url = 'https://ncov.kdca.go.kr/'
driver.get(url)
최신 뉴스 수집
특정 위치의 텍스트를 수집하기 위해서는 XPath가 필요합니다.
XPath(XML Path Language)는 웹페이지를 설계할 때 사용한 언어 구조로 위치를 특정하는 방식입니다. 웹페이지 화면에 배치된 많은 개체는 각각의 속성이 있는데, 그 중에서 XPath는 위치 정보를 나타냅니다.
XPath는 원하는 위치의 텍스트를 마우스 오른쪽 버튼으로 클릭하여 가장 아래의 검사(Inspect)를 선택합니다. 오른쪽의 개발자 도구(f12)가 실행되고, 선택한 객체에 해당하는 코드가 음영으로 표시됩니다.
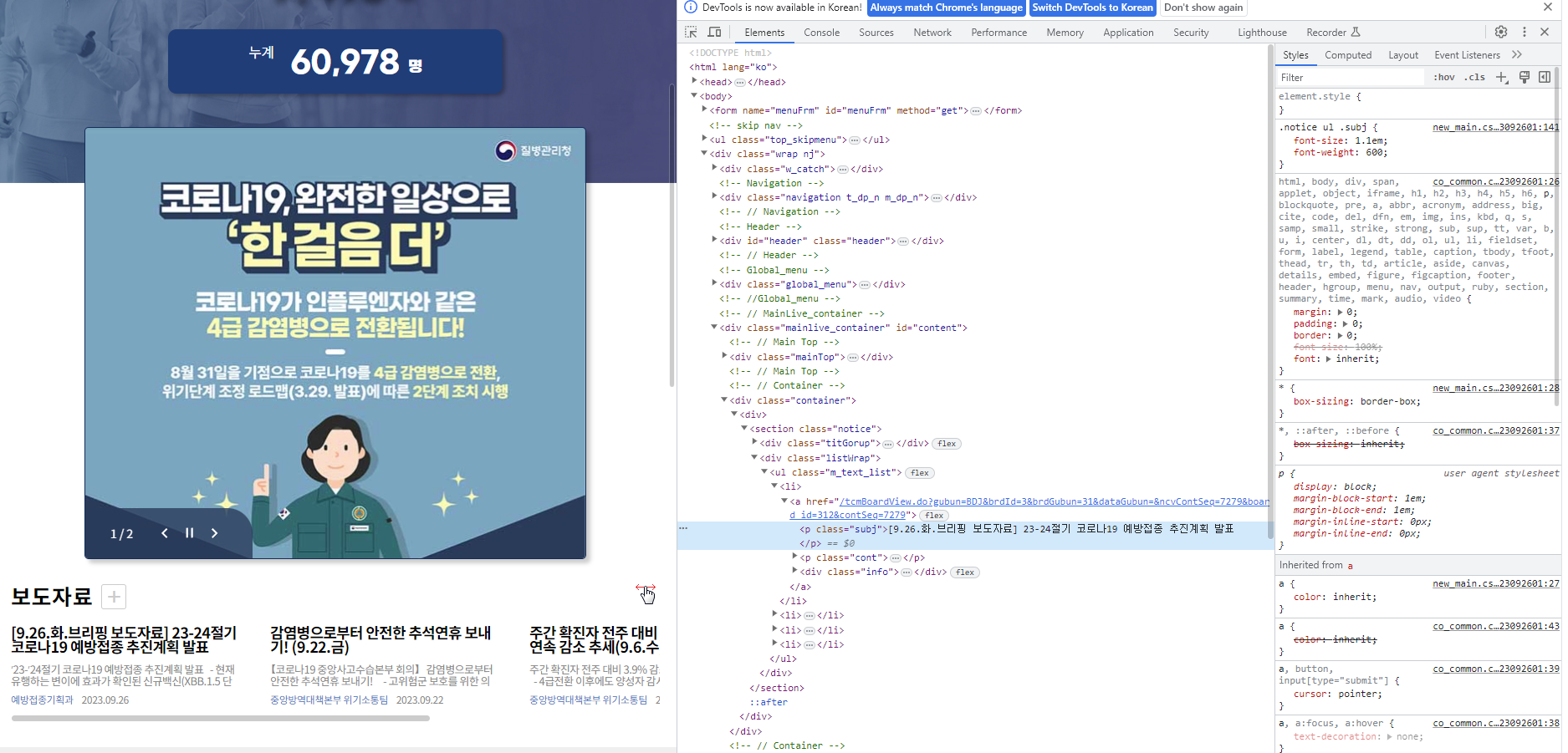
음영 표시된 코드를 마우스 오른쪽 버튼으로 클릭하고, 복사 -> XPath 복사를 선택합니다.
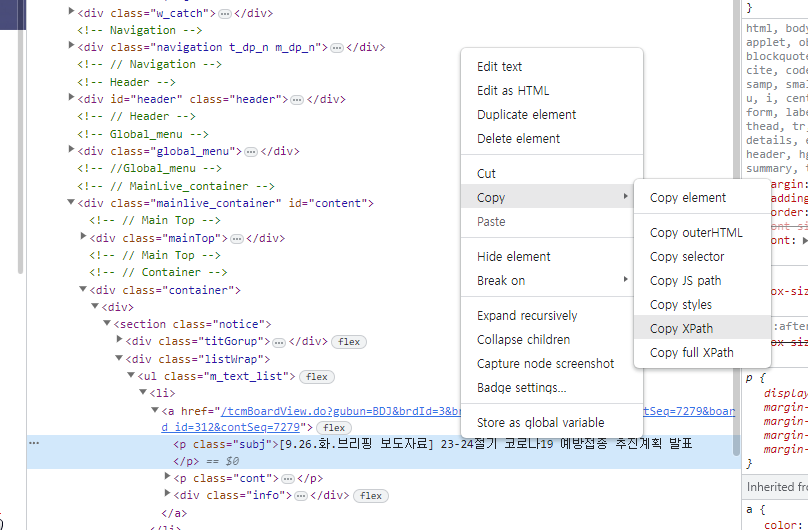
XPath를 확인하면 다음과 같습니다.
//*[@id="content"]/div[2]/div/section/div[2]/ul/li[1]/a/p[1]
해당 XPath로 기사 제목 객체에 접근하는 코드를 작성합니다.
url = 'https://ncov.kdca.go.kr/'
driver.get(url)
topnews = driver.find_element('xpath','//*[@id="content"]/div[2]/div/section/div[2]/ul/li[1]/a/p[1]')
print(topnews.text)find_element()로 XPath에 해당하는 객체를 찾고 반환 값을 topnews 변수에 넣습니다.
topnews 변수에 담은 객체의 텍스트를 text 속성을 호출해 반환하고, print()함수로 출력합니다..

여러 개의 최신 뉴스 한꺼번에 수집
이번에는 여러 줄을 동시에 수집해 보겠습니다.
여러 개의 객체에 공통 속성이 있다면, 한꺼번에 수집할 수 있습니다.
이때는 find_elements() 함수를 사용합니다. 뒤에 s가 붙은 것에 주의합니다.
우선 XPath의 구조를 확인해볼까요?
메인 페이지에 있는 4개의 뉴스 기사들의 XPath 값을 각각 복사해 비교해 봅시다.
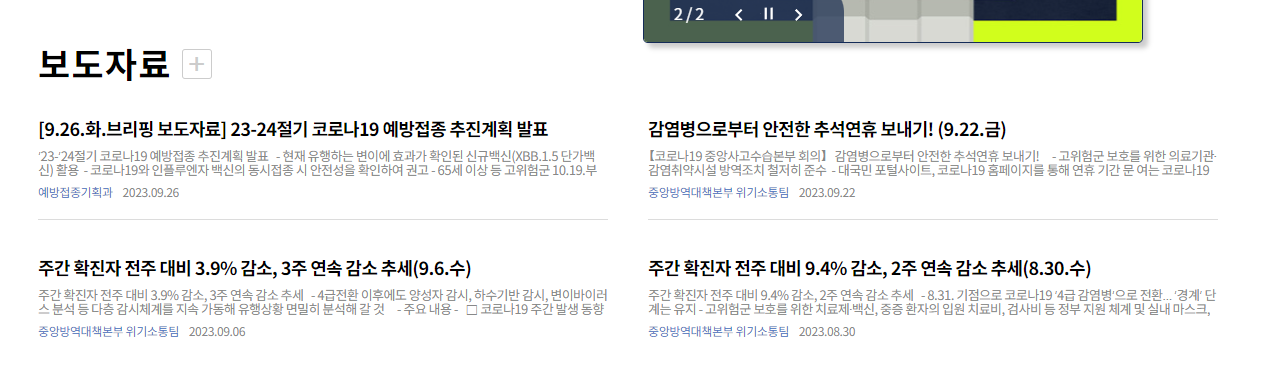
//*[@id="content"]/div[2]/div/section/div[2]/ul/li[1]/a/p[1]
//*[@id="content"]/div[2]/div/section/div[2]/ul/li[2]/a/p[1]
//*[@id="content"]/div[2]/div/section/div[2]/ul/li[3]/a/p[1]
//*[@id="content"]/div[2]/div/section/div[2]/ul/li[4]/a/p[1]무엇이 다른가요? ul까지 구문이 일치하고 그 다음 li태그에 붙은 번호가 다른 것을 알 수 있습니다. 그렇다면 //*[@id="content"]/div[2]/div/section/div[2]/ul 까지 넣어주면 되겠죠?
이제 find_elements() 함수를 사용해 한꺼번에 수집해 봅시다.
topnews = driver.find_elements('xpath','//*[@id="content"]/div[2]/div/section/div[2]/ul')
# 여러 개의 텍스트를 리스트 topnews에 정리하기
topnews = [topnew.text for topnew in topnews]
print(topnews)먼저 변수 topnews에 공통 XPath 위치에 있는 객체를 담아둡니다.
그리고 for문을 이용해 객체의 요소 5개를 순차적으로 텍스트로 변환하고 topnews 리스트에 담습니다.
마지막으로 topnews 전체를 출력해 수집한 텍스트를 확인합니다.

다음과 같이 잘 크롤링이 된 것을 볼 수 있습니다.
버튼 클릭
코로나 현황 페이지에스 뉴스를 검색하기 위해서는 먼저 돋보기 버튼을 클릭하고, 입력란을 나타내야 합니다.
셀레니움에서 돋보기 버튼을 찾아 클릭하는 작업을 자동화 하는 코드는 다음과 같습니다.
(개발자 도구에서 돋보기 버튼의 XPath를 복사합니다.)
# 버튼 객체 클릭
button = driver.find_element('xpath', '//*[@id="header"]/div/div[2]/a[1]')
print(button.text)
button.click()
돋보기 버튼을 클릭하면, 검색어 입력란과 검색 버튼이 나타납니다.

이후 검색어 입력란을 한번 클릭하고, 커서가 깜빡이는 상태로 만든 다음, 텍스트를 입력해 Enter를 누르거나, 검색 버튼을 클릭하는 과정이 필요합니다.
따라서 검색어 입력란의 XPath를 알아냅니다.
=>//*[@id="searchTermPc123"]
이후 검색어를 입력하고 엔터를 누르는 코드는 다음과 같습니다.
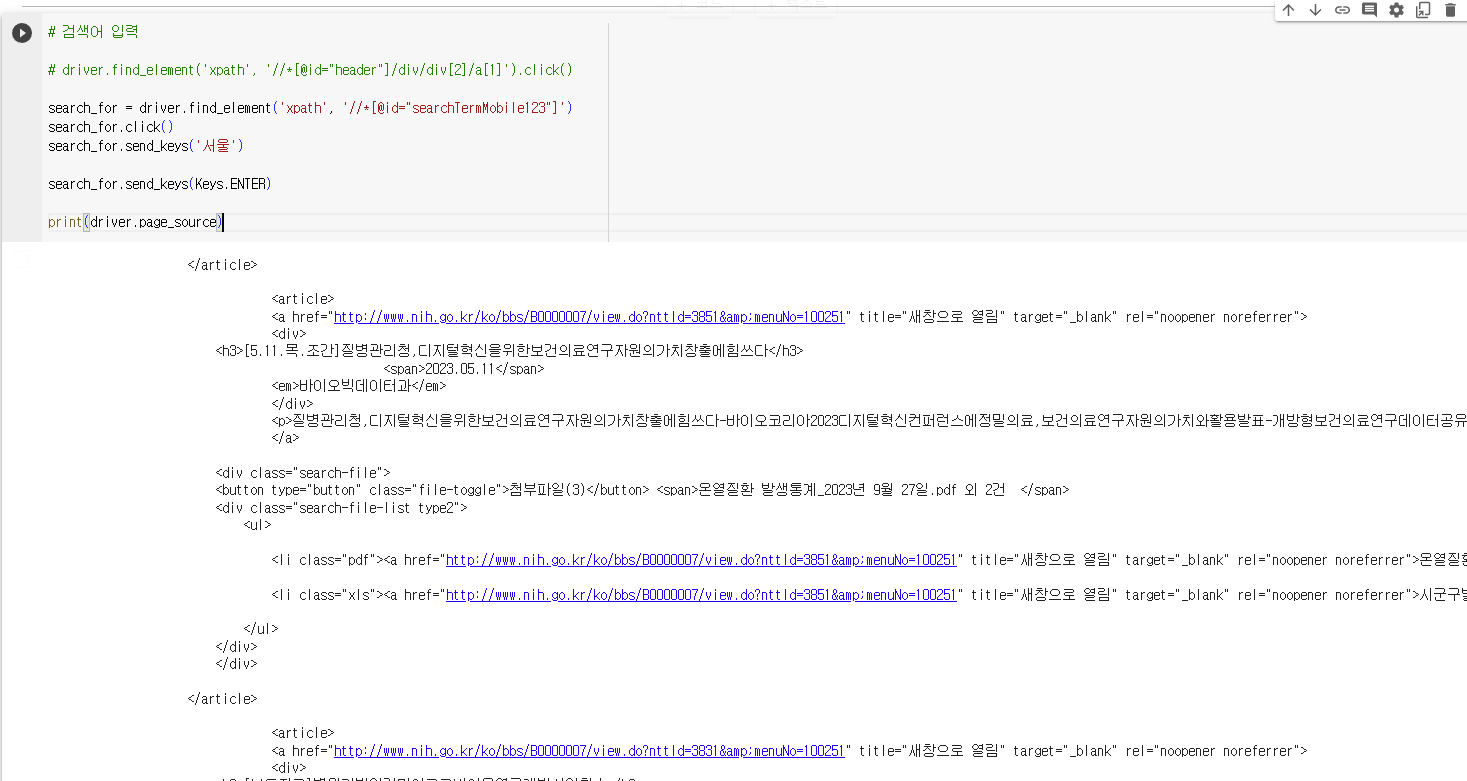
search_for = driver.find_element('xpath', '//*[@id="searchTermMobile123"]')
search_for.click()
search_for.send_keys('서울')
search_for.send_keys(Keys.ENTER)send_keys() 함수를 이용해 객체에 무언가를 입력합니다.
Keys.ENTER 를 send_keys() 함수의 인자로 넣으면 Enter를 입력하라는 명령이 됩니다.
하지만 위의 코드만으로는 현재 페이지가 화면에 나타나지 않아 명령이 제대로 수행된 것인지 알 수 없습니다. 이럴 때는, page_source 속성을 호출해 출력해 보면 페이지의 소스 코드를 보고 간접적으로 현재 페이지를 확인할 수 있습니다.
print(driver.page_source)