1. 시작말
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
HBase 의 경우 원천에서 실시간 데이터 저장 Needs 가 점점 발생하기 시작하여 공부하고 있는 중 입니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. HBase 란?
HBase 는 HDFS File System 기반으로 NoSQL 을 지원하는 DataBase 입니다. 컬럼기반으로 데이터를 저장하는 DataBase 이기 때문에 우리가 평소에 알던 테이블과는 약간 다른 모양으로 저장 됩니다.
HBase 는 구글의 Bigtable 의 기능을 많이 구현한 오픈 소스라고 합니다.
아래는 HBase 공식 홈에서 적어 놓은 HBase 에 대한 설명입니다.
" Apache HBase™ is the Hadoop database, a distributed, scalable, big data store.
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware. Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of Hadoop and HDFS. "
참고 : HBase 공식 홈
HBase 는 아래와 같이 구성 돼 있습니다.
- Catalog Tables
- Client
- Master
- RegionServer
- Regions
3. Master
Master 는 각 데이터를 저장하는 Region Server 들을 관리하고, 모니터링 하는 서버입니다.
전통적으로 Hadoop 의 NameNode 위에 Master 서버를 띄웁니다.
Master 는 아래와 같은 프로세스가 동작합니다.
-
LoadBalancer : 행 단위로 Region 에 데이터를 고르게 분배하는 것을 목표로 하는 HBase 에서 정해진 주기에 데이터를 고르게 분배 시키는 기능을 합니다.
-
CatalogJanitor : 저장돼 있는 테이블의 정보나 상태, Region 정보가 적혀 있는
hbase:meta를 관리합니다. Region 서버가 다운 되면 해당 Region 의 메타데이터를 정리합니다. -
MasterProcWAL : 메타데이터를 저장/변경/삭제 등의 행위를 하기 전에 Write Ahead Logging 에 기록합니다.
MasterProcWAL는 WAL 관련 작업을 처리하는 프로세스 입니다.
아래는 HBase 의 전체 아키텍처 입니다.
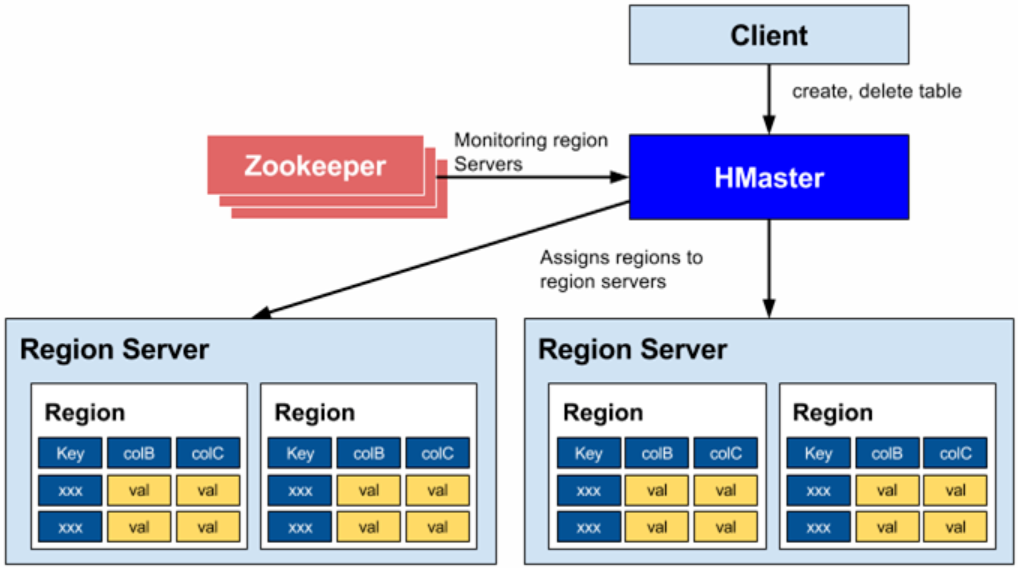
4. Catalog Tables
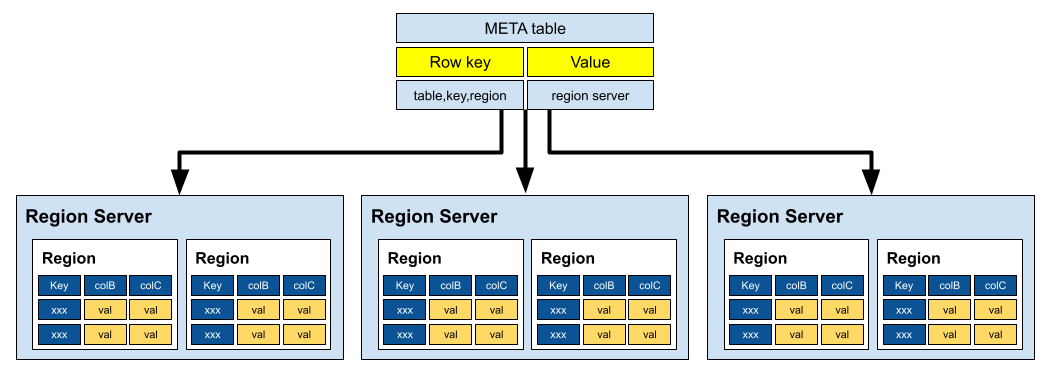
Catalog Tables 는 HBase 클러스터의 메타데이터 정보를 저장하는 특별한 테이블입니다.
이 테이블은 클러스터의 구성, 리전 서버의 할당, 테이블의 메타데이터 등과 같은 중요한 정보를 저장하고 관리합니다.
Catalog Tables 의 hbase:meta 테이블은 HBase 클러스터의 구성을 추적하고, 테이블과 리전 서버 간의 매핑 정보를 유지하는데 사용됩니다.
이 테이블은 Zookeeper 에 저장됩니다. 각 행은 하나의 테이블의 리전 정보를 나타내며, 리전 서버의 할당 및 테이블의 위치 정보를 포함합니다.
아래는 hbase:meta 의 구성 입니다.
-
Key :Region key of the format ([table],[region start key],[region id])
-
Values
-
info:regioninfo (serialized HRegionInfo instance for this region)
-
info:server (server:port of the RegionServer containing this region)
-
info:serverstartcode (start-time of the RegionServer process containing this region)
클라이언트가 특정 테이블에 대한 데이터를 요청하면, hbase:meta 테이블에서 해당 테이블의 리전 정보를 찾아 리전 서버의 위치를 확인한 후 해당 리전 서버에 데이터 요청을 전달합니다.
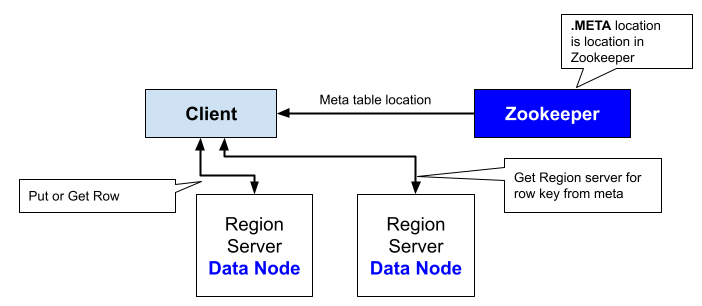
hbase:meta 테이블은 HBase 클러스터의 핵심 메타데이터 저장소이며, 클러스터의 안정성과 데이터의 일관성을 보장하기 위해 중요한 역할을 합니다. 클러스터의 구성 변경, 테이블 생성 및 삭제, 리전 서버 할당 등의 정보가 이 테이블에 저장되어 클러스터의 관리와 운영을 지원합니다.
5. Client
Client는 HBase 데이터에 접근하고 관리하기 위해 HBase API를 사용하여 클러스터와 통신합니다. 클라이언트는 데이터의 쓰기, 읽기, 업데이트, 삭제와 같은 작업을 수행하며, 클러스터의 상태를 조회하거나 테이블 및 리전 서버의 구성 변경을 수행하는 역할을 합니다.
클라이언트는 hbase:meta 테이블을 통해 메타데이터 정보를 조회 & 캐싱 합니다. 이 정보를 사용하여 클러스터 내 테이블과 리전 서버의 위치를 파악하고 데이터를 요청할 올바른 Region Server 를 결정합니다. Master 의 Load Balancer 에 의해 또는 RegionServer 가 종료되어 지역이 재할당 되면 Client 는 다시 Catalog Table 을 조회하여 Region 을 찾습니다.
클라이언트는 새로운 테이블을 생성하거나 기존 테이블을 삭제할 수 있습니다. 또한, 테이블의 설정 변경이나 리전 서버의 할당 변경과 같은 관리 작업도 수행할 수 있습니다.
클러스터와의 통신 중 발생하는 예외나 오류를 처리하고 관리합니다. 네트워크 문제, 클러스터 장애 또는 다른 예기치 않은 문제에 대응하여 안정적으로 작업을 수행하도록 합니다.
6. Region Server
Region Server 는 HBase 의 Master - Worker 구조에서 Worker 를 담당하는 서버라고 생각할 수 있습니다. Hadoop의 DataNode 에서 동작합니다
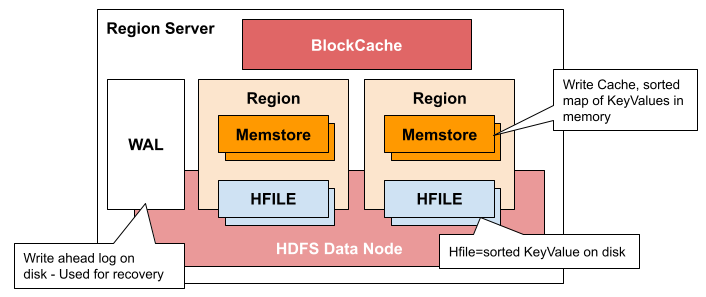
Region Server 에서 동작하는 프로세스는 아래와 같습니다.
- CompactSplitThread : 쓰기 작업을 수행하다보면 삭제 마크, 버전 관리 등으로 인해 불필요한 데이터가 누적될 수 있습니다. CompactSplitThread는 이러한 불필요한 데이터를 정리하기 위해 데이터 압축 작업(minor compaction)을 수행합니다. 그리고 테이블의 크기가 증가하거나 리전 내 데이터가 적절한 크기를 넘을 때, 리전을 분할하는 작업을 수행합니다.
Minor compaction
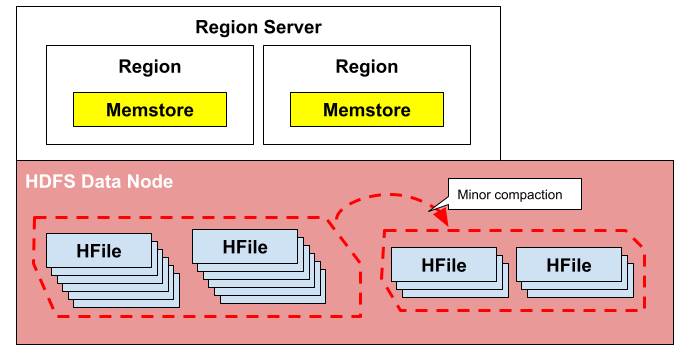
- MajorCompactionChecker : Major Compaction은 불필요한 데이터를 제거하고 데이터를 압축하여 성능을 최적화하기 위해 필요한 작업입니다. 이 스레드는 테이블마다 마지막 Major Compaction이 수행된 시간과 현재 시간을 비교하여 필요한 경우 Major Compaction을 수행할 지 결정합니다.
Major compaction
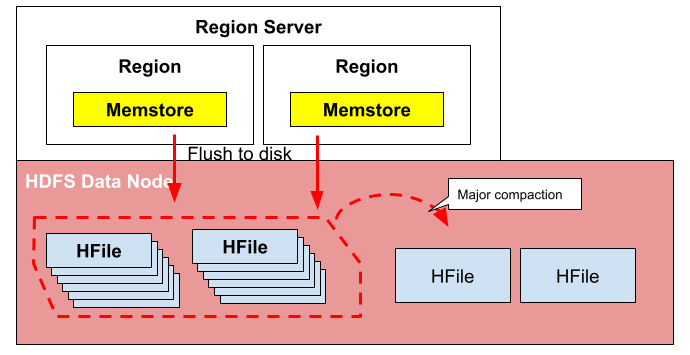
-
MemStoreFlusher : MemstoreFlusher는 Memstore에 저장된 데이터를 디스크에 플러시하여 HFile로 변환하는 작업을 수행합니다. 이를 통해 Memstore의 데이터가 영구 저장되고 읽기 작업에 사용됩니다.
-
LogRoller : HBase에서는 쓰기 작업이 발생할 때마다 해당 작업을 트랜잭션 로그(WAL, Write-Ahead Log)에 기록합니다. Log Rolling 은 트랜잭션 로그 파일의 크기가 일정 임계값에 도달하거나 일정 시간이 경과한 경우 새로운 로그 파일을 생성하고 작업을 기록합니다. 새로운 로그 파일이 생성되면 기존의 로그 파일은 유지되어야 합니다. LogRoller는 이전의 로그 파일을 삭제하거나 관리하면서 클러스터의 공간을 효율적으로 관리합니다.
-
Coprocessors : 사용자 정의 함수(UDF)
참고 : Coprocessor 설명
-
Block Cache : HBase는 HDFS에서 읽은 데이터를 캐시할 수 있는 두 가지 블록 캐시 구현 기능을 제공합니다. 기본 on-heap LruBlockCache 와 off-heap인 BucketCache가 있습니다.
참고 : Naver Deview 2023 - Data Lake 활용(HBase) Block cache 개선 사례(LRU 대응 KV Cache 구현)
7. Region Server Split
Region Server 는 데이터 쓰기 작업을 진행할 때 memstore 에 먼저 작성합니다. RegionServer는 해당 파일을 더 적은 수의 더 큰 파일로 압축합니다. 각 플러시 또는 압축이 완료되면 region 에 저장된 데이터 양이 변경됩니다. RegionServer는 region 분할 정책을 참조하여 region이 너무 커졌는지 또는 다른 정책별 이유로 분할해야 하는지 여부를 확인합니다.
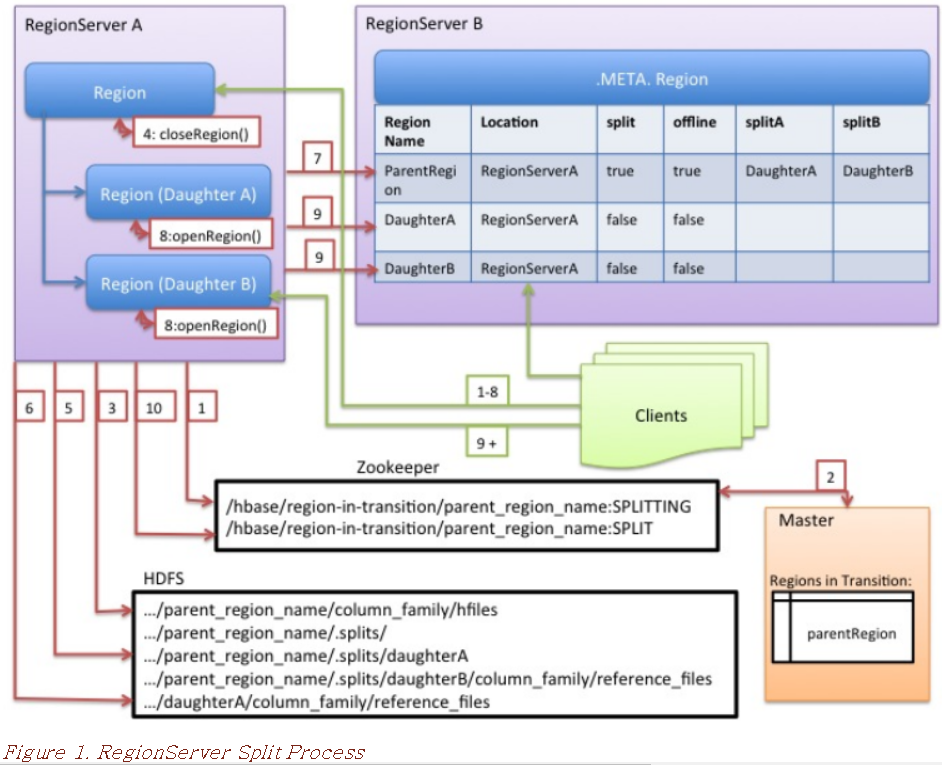
-
RegionServer는 Region Split을 로컬로 결정하고 Split을 준비합니다. 첫 번째 단계로 RegionServer는 분할 프로세스 중에 스키마 수정을 방지하기 위해 테이블에 대한 공유 읽기 잠금을 획득합니다. 그런 다음 /hbase/region-in-transition/region-name 아래의 Zookeeper에 znode를 생성하고 znode의 상태를 SPLITTING으로 설정합니다.
-
마스터는 전환 중인 상위 영역 znode에 대한 감시자가 있기 때문에 이 znode에 대해 알게 됩니다.
-
RegionServer는 HDFS의 상위 지역 디렉터리 아래에 .splits라는 하위 디렉터리를 생성합니다.
-
RegionServer는 상위 영역을 닫고 로컬 데이터 구조에서 해당 영역을 오프라인으로 표시합니다. Split 영역이 이제 오프라인 상태입니다. 이 시점에서 상위 지역으로 들어오는 클라이언트 요청은 NotServingRegionException을 발생시킵니다. 클라이언트는 백오프를 통해 다시 시도합니다. 닫는 영역이 플러시됩니다.
-
RegionServer는 .splits 디렉터리 아래에 하위 영역 A와 B에 대한 영역 디렉터리를 생성하고 필요한 데이터 구조를 생성합니다. 그런 다음 상위 지역의 저장소 파일당 두 개의 참조 파일을 생성한다는 의미에서 저장소 파일을 분할합니다. 해당 참조 파일은 상위 지역의 파일을 가리킵니다.
-
RegionServer는 HDFS에 실제 지역 디렉터리를 생성하고 각 하위 항목에 대한 참조 파일을 이동합니다.
-
RegionServer는 .META에 Put 요청을 보냅니다. 테이블을 사용하여 .META에서 상위 항목을 오프라인으로 설정합니다. 테이블을 만들고 Daughter Region에 대한 정보를 추가합니다. 이 시점에서는 .META에 Daughter Region들의 개별 항목이 없습니다. 클라이언트는 .META.를 스캔하면 상위 영역이 분할된 것을 볼 수 있지만 .META.에 나타날 때까지 Daughter Region들에 대해 알 수 없습니다. 또한 이 경우 Put to .META. 성공하면 부모가 효과적으로 분할됩니다. 이 RPC가 성공하기 전에 RegionServer가 실패하면 마스터와 지역을 여는 다음 지역 서버가 지역 분할에 대한 더티 상태를 정리합니다. .META 이후. 하지만 업데이트하면 지역 분할이 마스터에 의해 롤포워드됩니다.
-
RegionServer는 Daughter A와 B를 병렬로 엽니다.
-
RegionServer는 Region을 호스팅한다는 정보와 함께 Daughter A와 B를 .META.에 추가합니다. 분할 지역(부모를 참조하는 Daughter)이 이제 온라인 상태입니다. 이 시점 이후 클라이언트는 새 Region을 검색하고 해당 지역에 요청을 보낼 수 있습니다. 클라이언트는 .META를 캐시합니다. 로컬 항목이지만 RegionServer 또는 .META.에 요청하면 캐시가 무효화되고 .META.에서 새 지역에 대해 학습하게 됩니다.
-
RegionServer는 ZooKeeper의 znode /hbase/region-in-transition/region-name을 SPLIT 상태로 업데이트하여 마스터가 이에 대해 알아볼 수 있도록 합니다. 밸런서는 필요한 경우 하위 지역을 다른 지역 서버에 자유롭게 재할당할 수 있습니다. 이제 분할 거래가 완료되었습니다.
-
분할 후 .META. HDFS에는 여전히 상위 지역에 대한 참조가 포함됩니다. 하위 영역의 압축이 데이터 파일을 다시 작성할 때 해당 참조는 제거됩니다. 마스터의 GC 작업은 Daughter Region이 여전히 상위 영역의 파일을 참조하는지 여부를 주기적으로 확인합니다. 그렇지 않은 경우 상위 지역이 제거됩니다.
8. Write Ahead Log(WAL)
WAL(Write Ahead Log)은 HBase, 파일 기반 스토리지에서 데이터의 모든 변경 사항을 기록합니다. WAL은 변경 정보 리스트를 저장하고 있고, 하나의 변경 정보는 하나의 put/delete 를 나타냅니다. 해당 변경 정보는 변경 내역과, 어떤 Region에 변경이 있었는지를 저장합니다. 변경 정보는 시간순으로 기록되어 있고, 보존을 위해서 WAL 파일의 끝에 계속 추가되어서 디스크에 저장됩니다.
기본적으로 WAL 이 없다면 Memstore 에 바로 데이터가 작성이 되겠지만 이 때 Memstore 는 각 Region Server 들의 내부 메모리를 사용한다고 합니다.Memstore 에서 Disk 로 Flush 가 발생하지 않은 채로 장애를 맞이한다면, 트랜잭션들을 복구할 수 있는 방법이 사라지게 됩니다.
이 때 WAL 에 먼저 트랜잭션들이 기록이 돼 있다면, HBase 재기동시 WAL 을 보고 복구를 할 수 있습니다.
기본적으로, WAL 파일은 HDFS의 block size의 95% 정도 크기가 되면 바뀌게 됩니다. “hbase.regionserver.logroll.multiplier” 파라매터를 이용해서 값을 설정할 수 있고 block size는 “hbase.regionserver.hlog.blocksize” 로 설정이 가능합니다. WAL 파일을 일정 간격으로 변경되도록 할 때는 “hbase.regionserver.logroll.period” 을 사용하면 됩니다. 기본적으로 한 시간으로 설정되어 있습니다. WAL 파일의 크기가 설정 값 보다 작아도 한시간 마다 바뀌게 됩니다.
WAL 은 아래와 같이 저장소를 선정 수 있습니다.
-
asyncfs : WAL을 HDFS에 비동기적으로 기록하는 옵션입니다. 비동기적으로 기록되기 때문에 성능 향상을 가져올 수 있습니다.
-
filesystem : HDFS에 WAL을 기록하는 또 다른 옵션입니다.
-
multiwal: 복수의 WAL 프로바이더를 사용할 수 있는 옵션입니다. 각 테이블 또는 테이블 그룹별로 다른 WAL 프로바이더를 지정할 수 있습니다. 예를 들어, Replication 등의 목적으로 특정 테이블에 대해서만 별도의 WAL 프로바이더를 설정할 수 있습니다.
한 RegionServer의 모든 영역은 동일한 활성 WAL 파일을 공유합니다. Region이 열리면 해당 영역에 속하는 WAL 파일의 기록된 트랜잭션이 수행 됩니다. 따라서 WAL 파일의 편집 내용은 특정 영역을 수행하여 특정 영역의 데이터를 재생성할 수 있도록 영역별로 그룹화해야 합니다. WAL 편집을 영역별로 그룹화하는 과정을 로그 분할이라고 합니다.
로그 분할은 클러스터 시작 중에 HMaster에 의해 수행되거나 영역 서버가 종료될 때 ServerShutdownHandler에 의해 수행됩니다. 따라서 데이터가 복원될 때까지 영향을 받는 region을 사용할 수 없습니다. 지정된 영역을 다시 사용하려면 먼저 모든 WAL 트랜잭션들을 복구하고 수행해야 합니다.
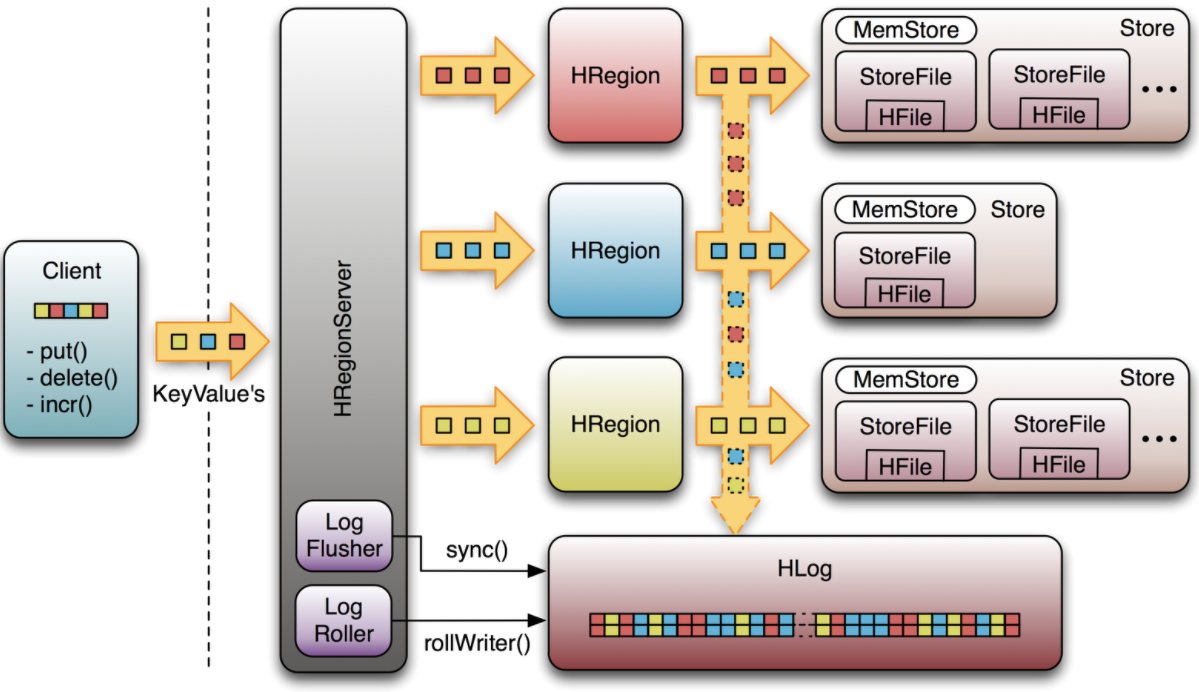
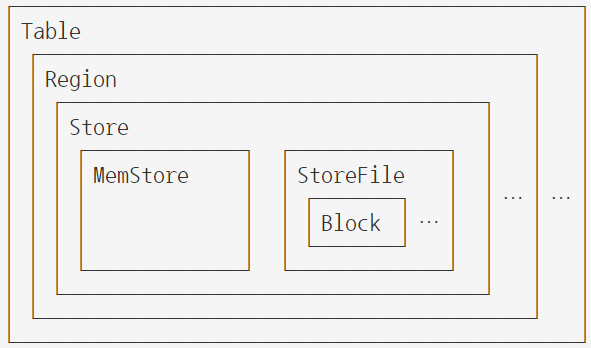
9. Regions
Region은 테이블의 가용성과 분배의 기본 요소로, Column Family당 저장되는것으로 구성됩니다. 계층 구조는 다음과 같습니다.
Table (HBase table)
Region (Regions for the table)
Store (Store per ColumnFamily for each Region for the table)
MemStore (MemStore for each Store for each Region for the table)
StoreFile (StoreFiles for each Store for each Region for the table)
Block (Blocks within a StoreFile within a Store for each Region for the table)일반적으로 HBase는 서버당 비교적 큰 용량(5-20Gb)의 region으로 적게(20-200) 설계됩니다.
일반적으로 여러 가지 이유로 인해 HBase에서 region 수를 작게 유지하려고 합니다. 보통 RegionServer당 약 100개의 region이 최상의 결과를 도출했다고 합니다.
10. 맺음말
HBase 공식 문서를 보며 상당히 데이터 복구나 저장, 읽기 능력에 많이 초점을 둔 DB라는 것을 알 수 있었습니다.
아직 제가 원하는 기능(Dynamic Column Family, Random Access 성능 비교, Write 성능 등)에 대해서는 더 찾아봐야할 듯 합니다만 충분히 조사를 해볼 만한 가치가 있는 듯 합니다.
11. 참고 사이트
https://www.joinc.co.kr/w/man/12/hadoop/hbase/about
https://songdev.tistory.com/71
https://hbase.apache.org/book.html#regions.arch
https://charsyam.wordpress.com/2012/06/20/%EB%B0%9C-%EB%B2%88%EC%97%AD-hbase-write-path/
