1. 시작말
안녕하세요.
데이터 엔지니어링 & 운영 업무를 하는 중 알게 된 지식이나 의문점들을 시리즈 형식으로 계속해서 작성해나가며
새로 알게 된 점이나 잘 못 알고 있었던 점을 더욱 기억에 남기기 위해 글을 꾸준히 작성 할려고 합니다.
HBase 의 경우 원천에서 실시간 데이터 저장 Needs 가 점점 발생하기 시작하여 공부하고 있는 중 입니다.
반드시 글을 읽어 주실 때 잘 못 말하고 있는 부분은 정정 요청 드립니다.
저의 지식에 큰 도움이 됩니다. :)
2. HBase Table
HBase 는 HDFS File System 기반으로 NoSQL 을 지원하는 DataBase 입니다. 컬럼 기반으로 데이터를 저장하는 DataBase 이기 때문에 우리가 평소에 알던 테이블과는 약간 다른 모양으로 저장 됩니다.
테이블을 생성하게 되면 아래와 같은 계층 구조로 테이블이 생성 됩니다.
Table (HBase table)
Region (Regions for the table)
Store (Store per ColumnFamily for each Region for the table)
MemStore (MemStore for each Store for each Region for the table)
StoreFile (StoreFiles for each Store for each Region for the table)
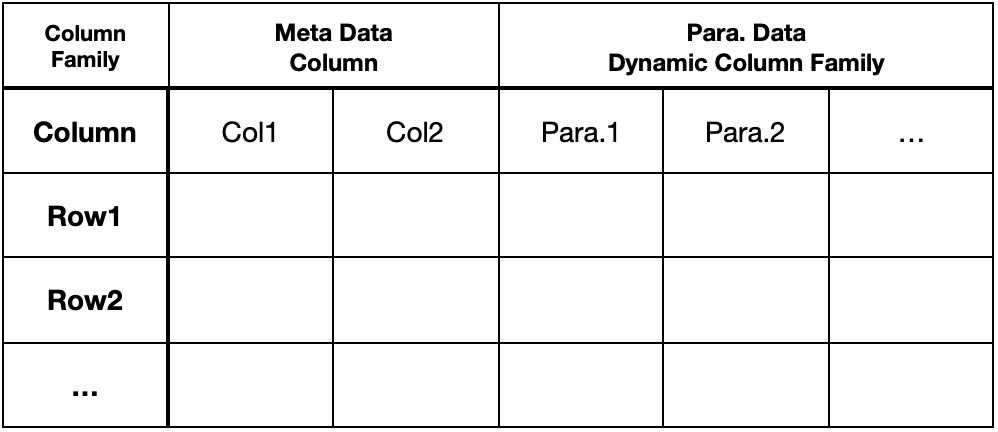
Block (Blocks within a StoreFile within a Store for each Region for the table)실질적으로 사용자가 사용할 때는 아래와 같이 테이블을 볼 수 있습니다.
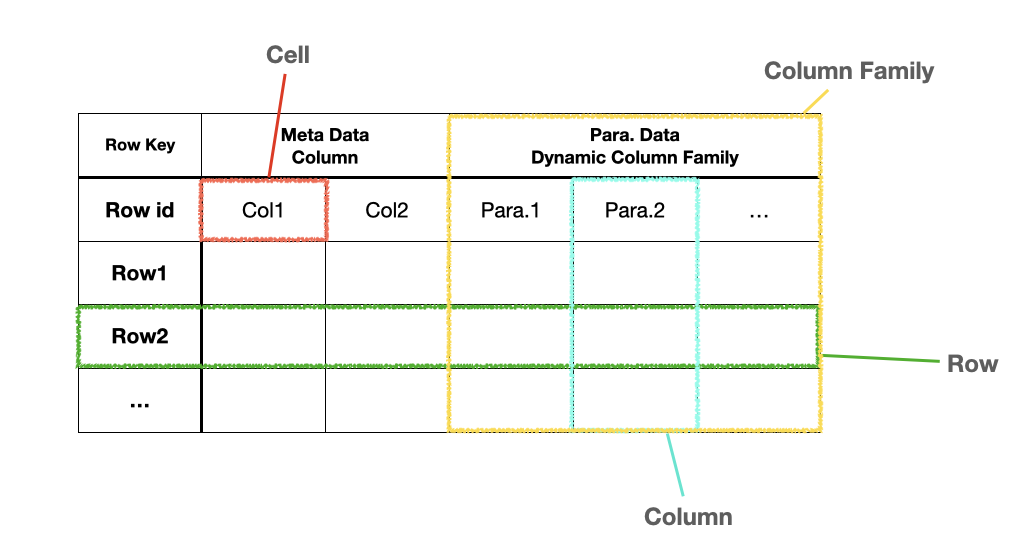
공식문서에서 말하고 있는 Data Model 을 구성하는 요소 중 일부는 아래와 같습니다.
- Namespace
- Table
- Row
- Column Family
- Cells
2.1. Namespace
네임스페이스는 관계 데이터베이스 시스템의 데이터베이스와 유사한 테이블의 논리적 그룹입니다. 이 추상화는 향후 다중 테넌시 관련 기능의 토대를 마련합니다.
2.2. Table
테이블은 스키마 정의 시 미리 선언됩니다.
2.3. Row
행 키는 uninterpreted bytes 입니다. 행은 사전순으로 정렬되어 테이블의 첫 번째에 가장 낮은 순서가 나타납니다. 빈 바이트 배열은 테이블 네임스페이스의 시작과 끝을 모두 나타내는 데 사용됩니다.
2.4. Column Family
Apache HBase의 Column 은 Column Family 로 그룹화됩니다. 컬olumn Family 의 모든 Column 멤버는 동일한 접두사를 갖습니다. 예를 들어,courses:history 및courses:math 열은 모두 coureses column 계열의 구성원입니다. 콜론 문자(:)는 Column Family 한정자에서 Column Family를 구분합니다.
Column Family 는 스키마 정의 시 미리 선언해야 하지만 Column 은 스키마 시 정의할 필요가 없지만 테이블이 실행 중일 때 즉시 사용할 수 있습니다.
물리적으로 모든 Column Family 는 파일 시스템에 함께 저장됩니다. 튜닝 및 스토리지 사양은 Column Family 수준에서 수행되므로 모든 Column Family 는 동일한 일반 액세스 패턴 및 크기 특성을 갖는 것이 좋습니다.
2.5. Cells
{row, columns, version} 튜플은 HBase의 셀을 정확하게 지정합니다. 셀은 uninterpreted bytes 입니다.
3. 맺음말
최종적으로는 컬럼의 개수가 정해져 있지 않은 테이블을 저장하기 위해 미리 스키마를 지정하기가 쉽지 않습니다.
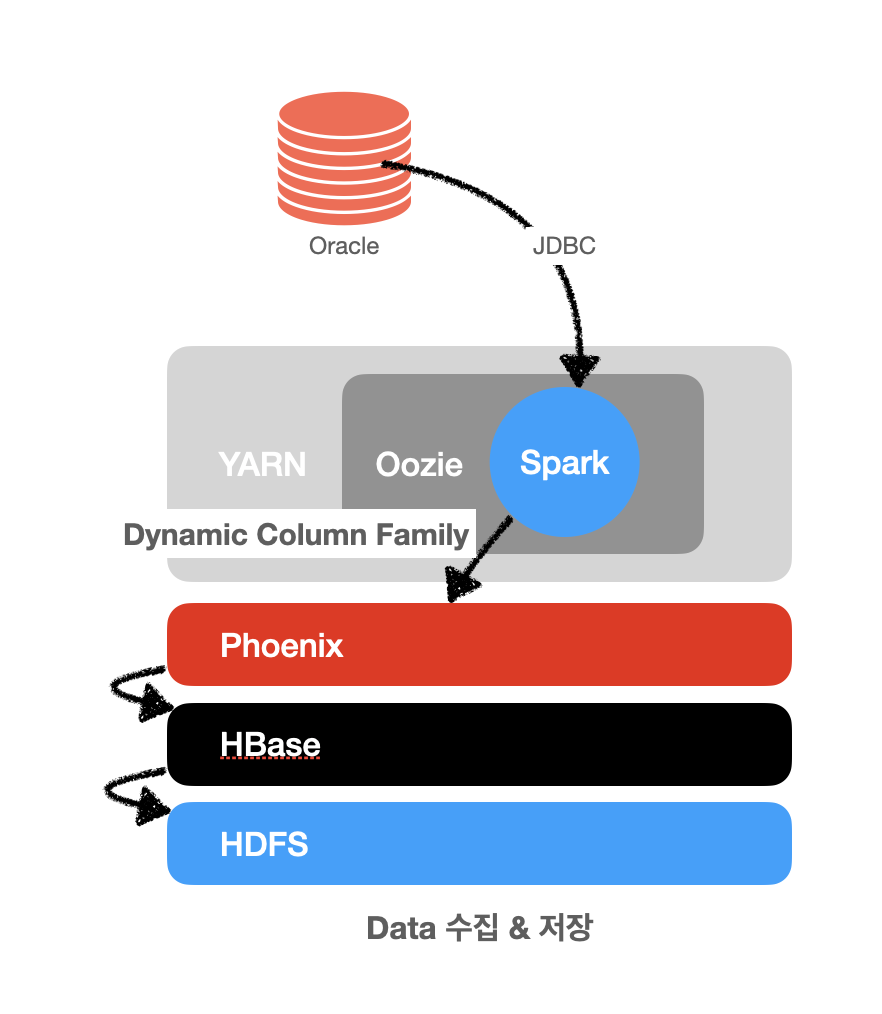
데이터 수집 요건 중 Oracle Table 의 Row 마다 column 개수가 다른 테이블을 blob 처리한 테이블을 백업하는 내용이 있습니다.
이 때 유동적인 컬럼의 범위를 Column Family 로 지정 후 아래와 같이 데이터를 저장하면 dataframe 을 만들어 가는 전처리 과정도 쉬워질 것으로 예상 됩니다.