
🔦 본 포스트는 유튜브 널널한 개발자 강의를 기반으로 함을 알립니다.
문서를 다루는 프로그램
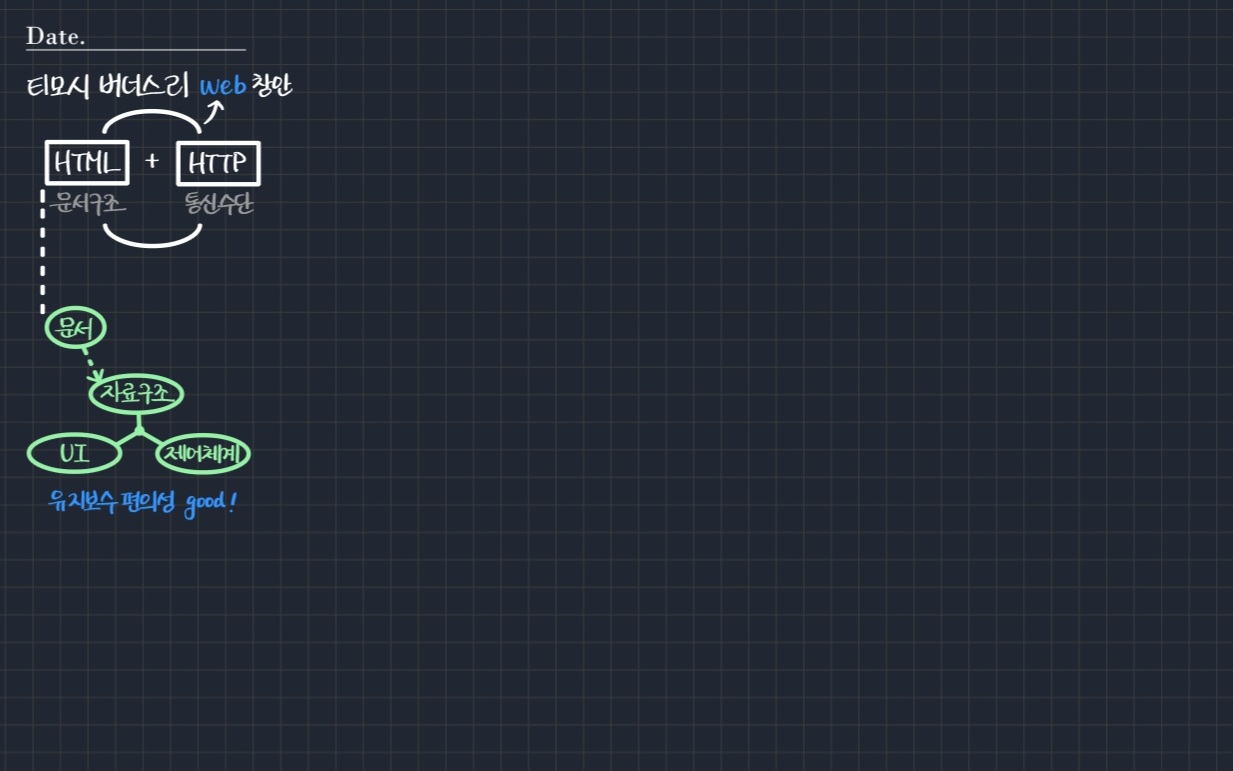
문서를 다루는 프로그램은 3가지 요소로 이루어진다.
- 자료구조 (문서는 자료구조에 해당한다)
- UI
- 이 모든 것을 제어할 제어체계
이렇게 기능을 나누는 이유는 유지보수 편의성을 극대화하기 위해서이다. 웹도 예외는 아니다.
클라이언트와 서버, TCP/IP
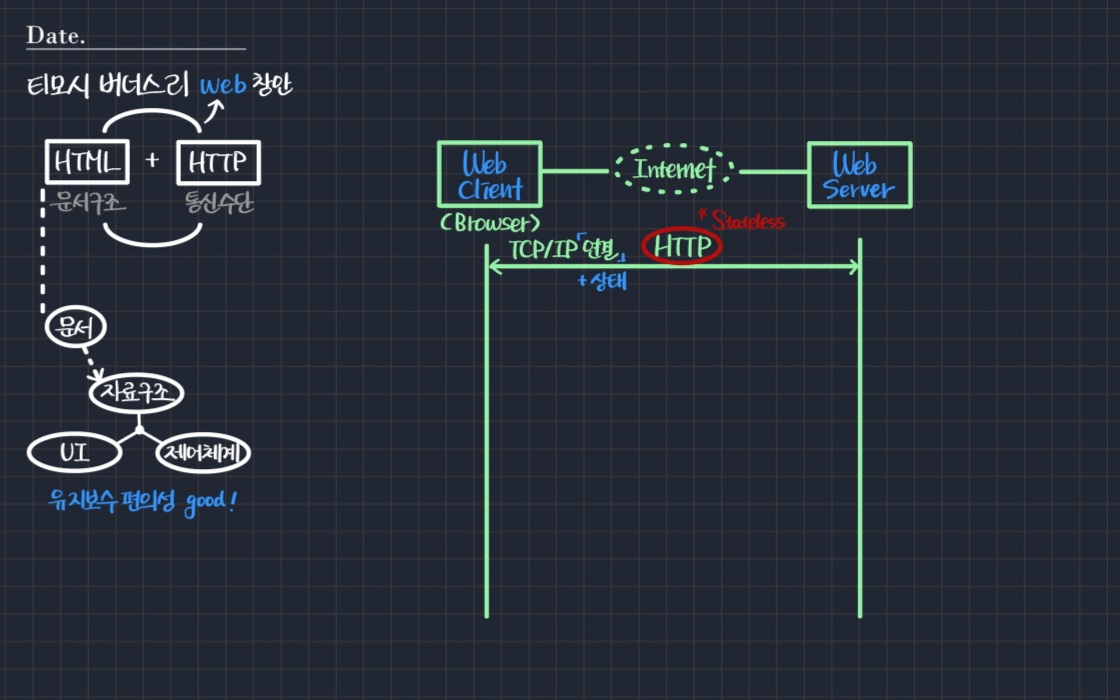
웹을 이루는 구성요소에는 Web Client(=Browser)가 있고, 이것이 인터넷에 연결되어 Web Server를 만난다.
티모시는 웹을 설계할 때 TCP/IP 통신을 대전제로 했다. 다시 말해 클라이언트와 서버가 TCP/IP 연결되어 있는 상태에서 HTTP 통신이 이루어진다고 가정했다는 것이다.
- 이때 HTTP의 중요한 특징으로
stateless가 있다. - TCP/IP 연결은
상태의 개념을 포함하는데, 그 윗단에서 동작하는 HTTP는 상태 개념이 없다는 것이 훗날 문제가 되기도 한다. → 설계적 변화 야기
웹에서 HTML의 의미
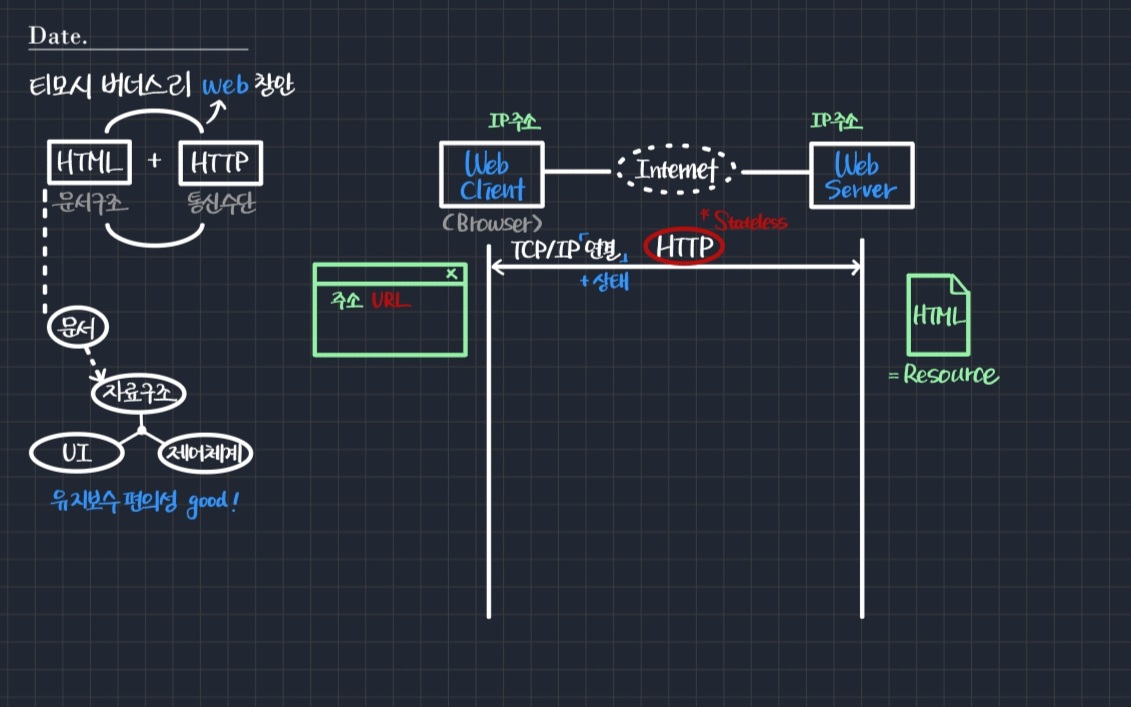
어쨌든 기본 구조는 간단하다.
여기저기 흩어져 있는 논문이 HTML 문서 형태로 만들어져 있다고 가정해보자. 티모시가 초기에 만든 브라우저는 프로그램에 URL 형태의 주소를 적는 것이었다.
- url은 Uniform Resource Location의 약자이다. 여기서는 HTML 문서가 리소스가 된다.
클라이언트와 서버는 각각 자신의 IP 주소를 갖는다. 이 주소를 통해 TCP/IP 연결을 한 뒤 resource 연결을 하게 된다.
서버의 문서를 어떻게 가져올까?
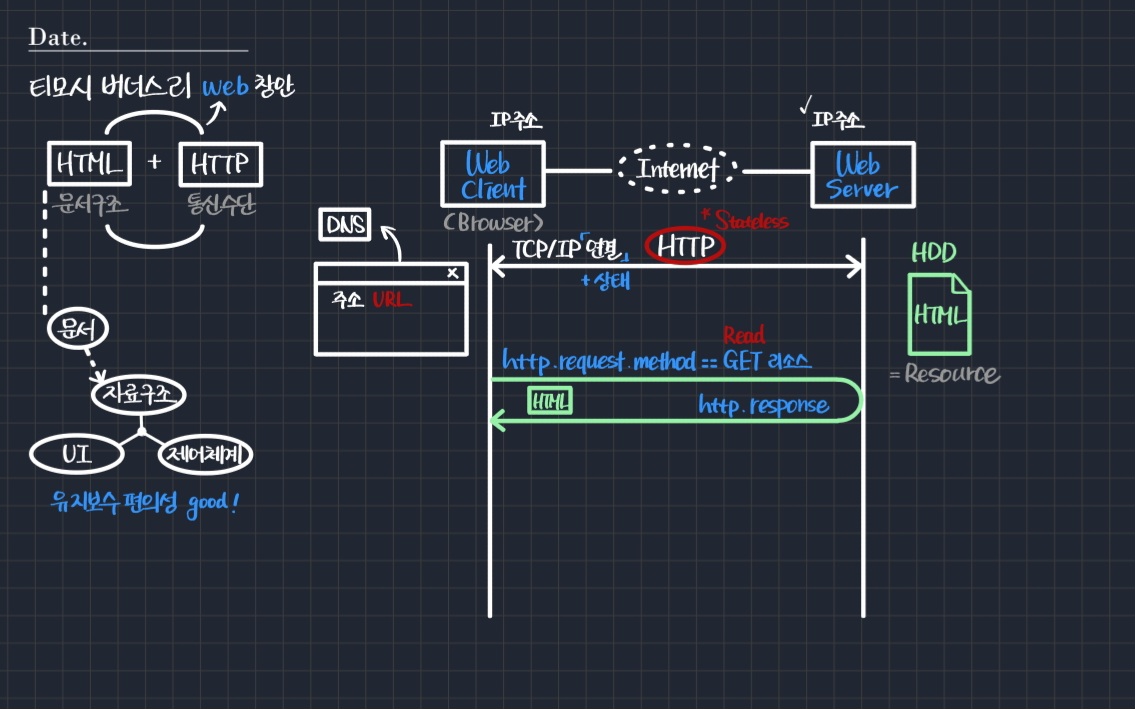
resource 연결을 하면 그때부터 HTTP 프로토콜이 작동하기 시작한다. HTTP 통신을 하는 데 있어 기본적으로 request가 날아간다. HTTP 프로토콜의 구조상, 이후 해당 request에 대한 response가 오게 되어 있다.
request에는 여러 가지 방법론(method)이 있다. 그 중 가장 흔한 것이 GET이다. GET 메소드는 "GET이라는 방법론으로 리소스를 주세요"라는 의미를 갖는다.
GET 요청에 따라 그에 해당하는 HTML 문서가 response로 날아가게 된다. HTML 문서는 HDD 등의 특정 공간에 저장된 형태로 존재하다가 그대로 읽힌다. 결국 클라이언트의 입장에서 GET 메소드는 정보를 읽는 read(읽기)의 역할을 하는 것이다.
URL과 HTML 문서의 상관관계
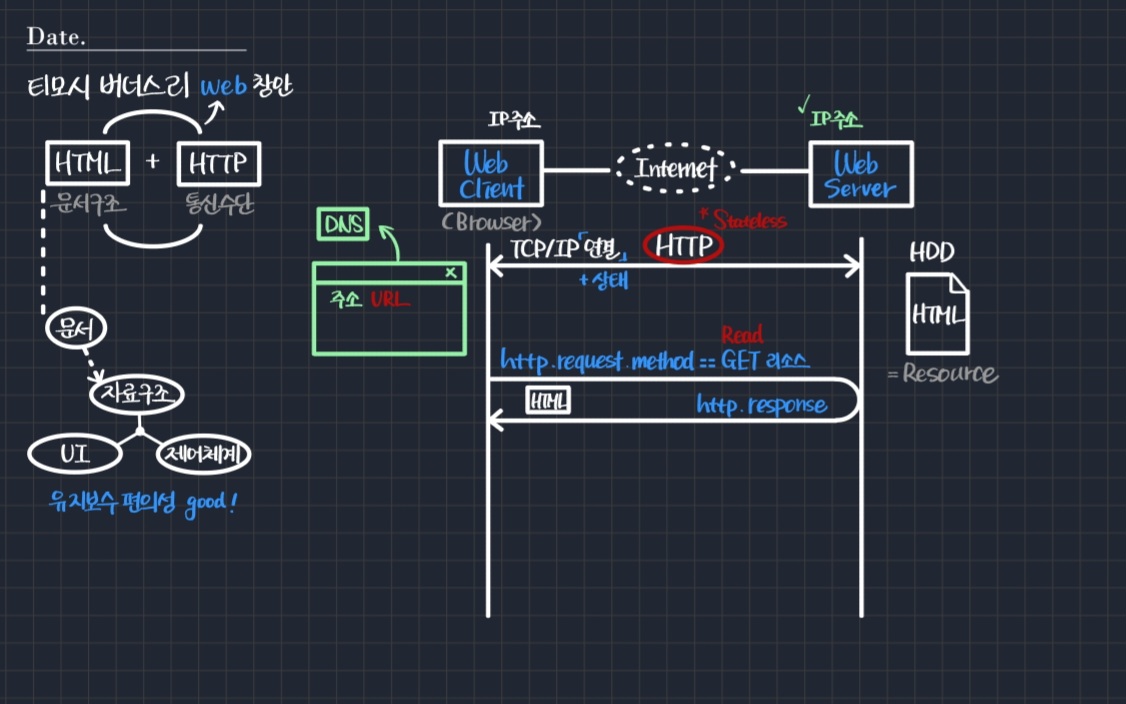
🤔 브라우저의 실제 접속은 IP주소로 한다. 그런데 우리가 주소창에 적는 것은 IP가 아닌 url이다. 어떻게 된 걸까?
- 사용자가 주소창에 url을 입력하면 DNS라는 시스템은 IP 주소가 무엇인지 알려준다. 이때의 url은 서버의 url이며, 따라서 서버의 IP 주소를 알려주게 된다.
- 결과적으로 우리는 서버의 IP를 이용해 브라우저에 접속한 것이고, 그렇게 HTML 문서를 획득한 것이다.
가져온 문서를 화면에 보여주기
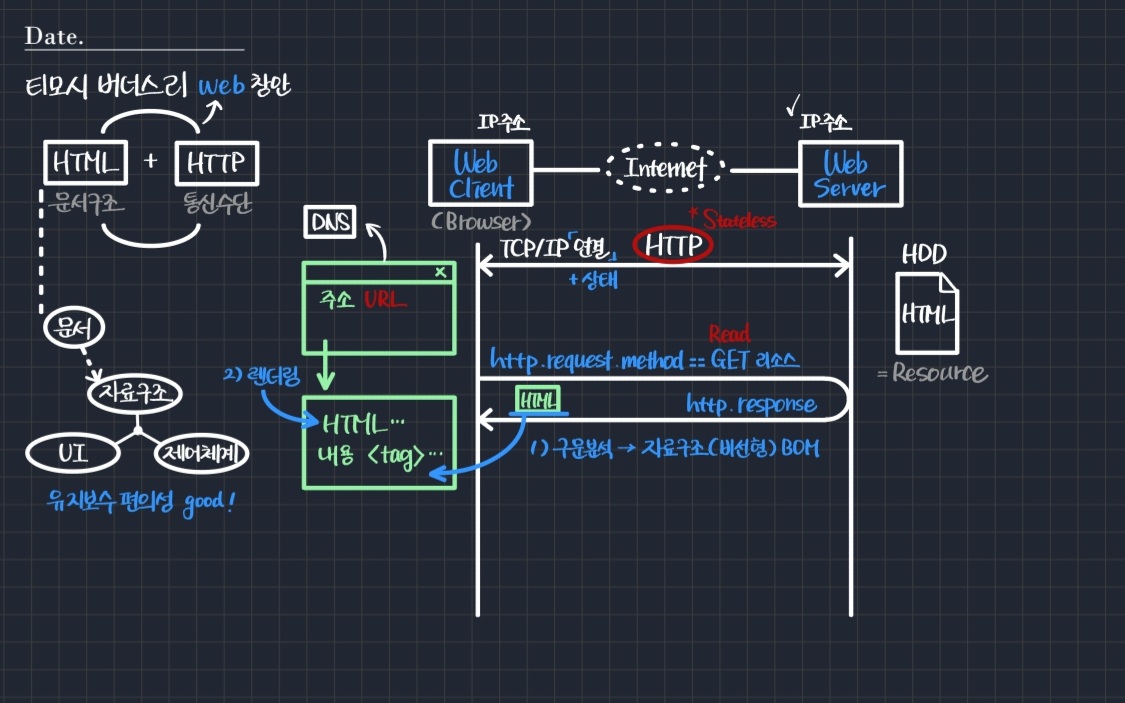
문제는 HTML 문서의 내용이 일반적인 텍스트 외에도 태그(tag) 등의 요소를 포함한다는 데 있다. 이에 브라우저는 HTML 문서를 가져오자마자 첫째로 구문 분석(parsing)을 수행한다. 이후 구문 분석 결과를 가지고 자료구조를 생성한다.
- 자료구조는 비선형으로 이루어져 있다.
다음으로 만들어진 구조를 화면에 렌더링한다(=화면에 출력). 따라서 브라우저를 이루는 핵심 요소는 구문분석기와 렌더링 엔진이다.
정리
여기까지 HTTP 1.0 수준을 살펴보았다. 당시의 브라우저는 문서 뷰어와 동일했던 것으로 보인다. 다만 원격지 문서뷰어였다는 점은 기존의 문서뷰어와 차별화된다. 이렇듯 문서를 가져오고, 또 보여주고 하는 일련의 과정을 초기의 웹이 수행했다.
Reference
https://youtu.be/4Sfned8HLzk
https://blog.naver.com/benuss/222271259443 (노트 속지-울산 고씨 님)
